 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA simple defense against adversarial attacks on heatmap explanations
Jul 13, 2020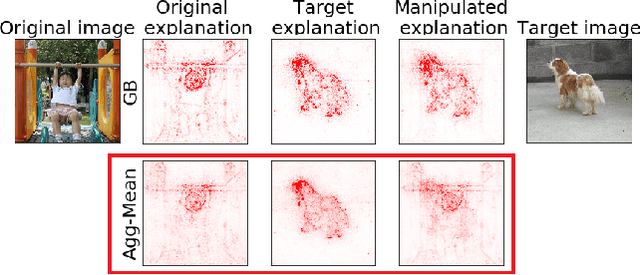
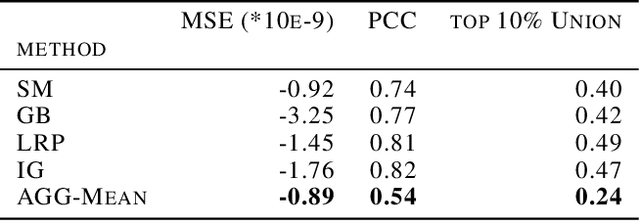
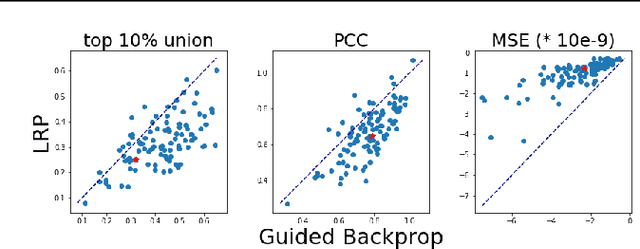
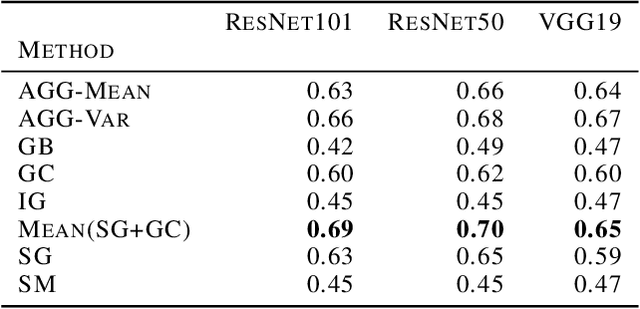
With machine learning models being used for more sensitive applications, we rely on interpretability methods to prove that no discriminating attributes were used for classification. A potential concern is the so-called "fair-washing" - manipulating a model such that the features used in reality are hidden and more innocuous features are shown to be important instead. In our work we present an effective defence against such adversarial attacks on neural networks. By a simple aggregation of multiple explanation methods, the network becomes robust against manipulation. This holds even when the attacker has exact knowledge of the model weights and the explanation methods used.
Probabilistic Decoupling of Labels in Classification
Jun 16, 2020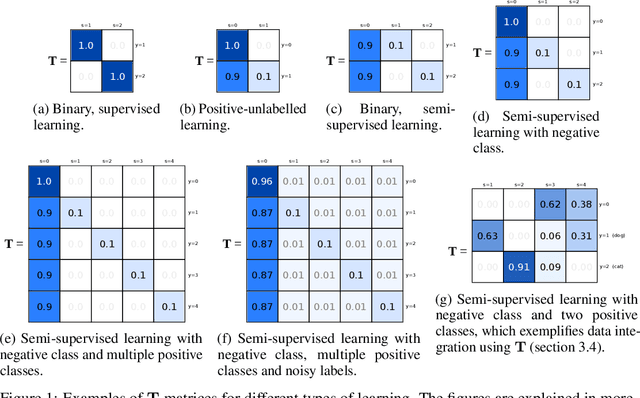
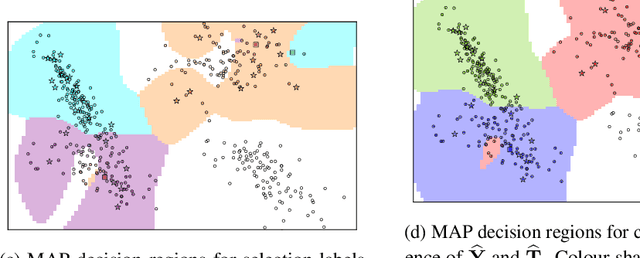
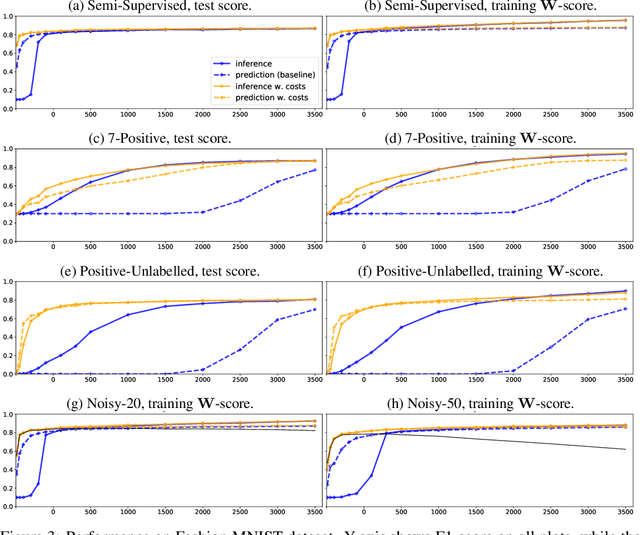
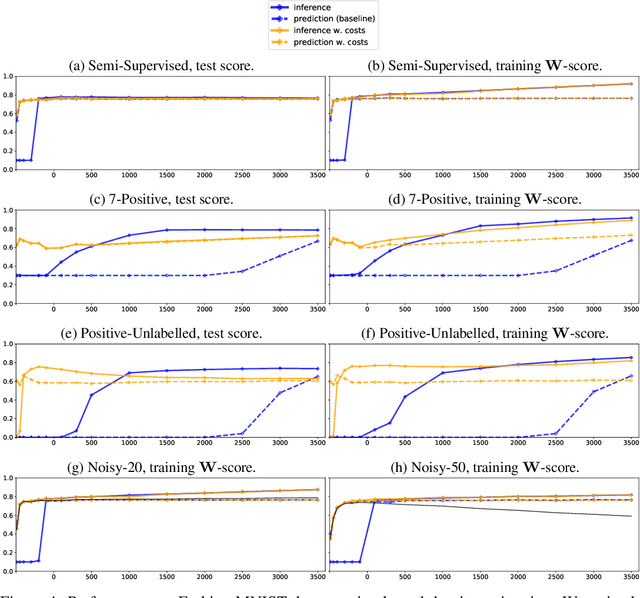
In this paper we develop a principled, probabilistic, unified approach to non-standard classification tasks, such as semi-supervised, positive-unlabelled, multi-positive-unlabelled and noisy-label learning. We train a classifier on the given labels to predict the label-distribution. We then infer the underlying class-distributions by variationally optimizing a model of label-class transitions.
On the Limits to Multi-Modal Popularity Prediction on Instagram -- A New Robust, Efficient and Explainable Baseline
Apr 26, 2020
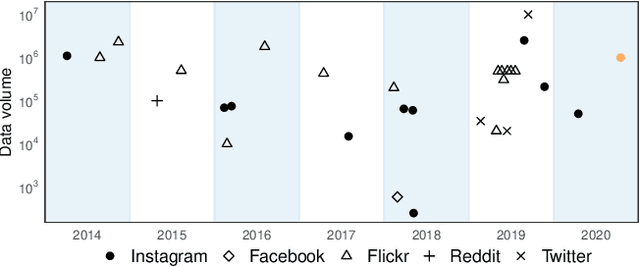
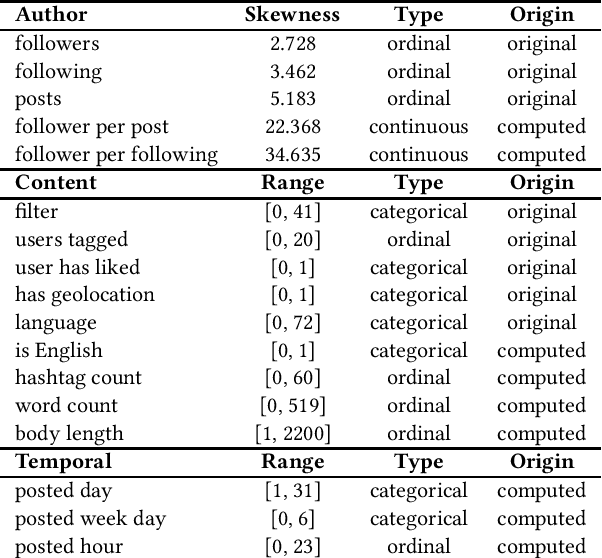
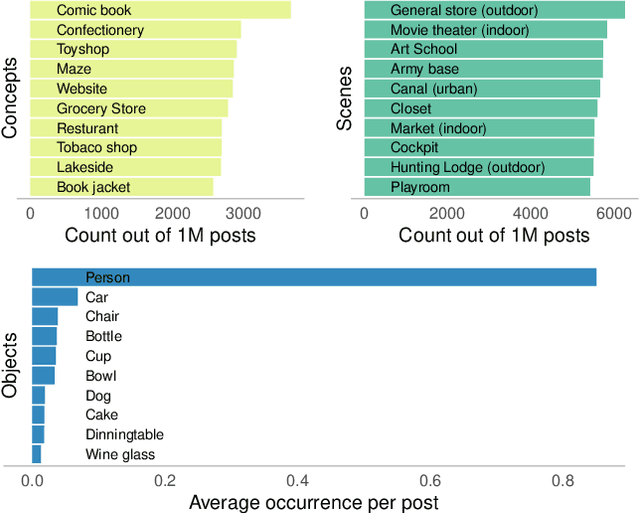
The predictability of social media popularity is a topic of much scientific interest and significant practical importance. We present a new strong baseline for popularity prediction on Instagram, which is both robust and efficient to compute. The approach expands previous work by a comprehensive ablation study of the predictive power of multiple representations of the visual modality and by detailed use of explainability tools. We use transfer learning to extract visual semantics as concepts, scenes, and objects, which allows us to interpret and explain the trained model and predictions. The study is based in one million posts extracted from Instagram. We approach the problem of popularity prediction as a ranking problem, where we predict the log-normalised number of likes. Through our ablation study design, we can suggest models that outperform a previous state-of-the-art black-box method for multi-modal popularity prediction on Instagram.
IROF: a low resource evaluation metric for explanation methods
Mar 09, 2020

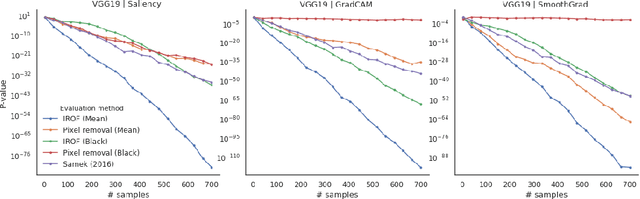
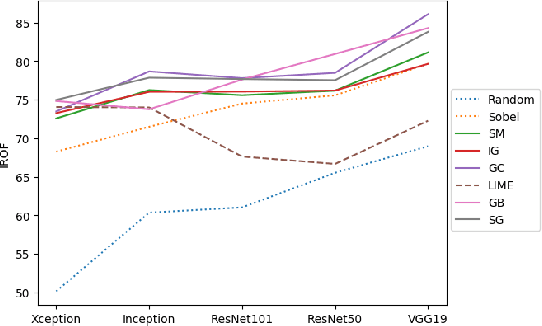
The adoption of machine learning in health care hinges on the transparency of the used algorithms, necessitating the need for explanation methods. However, despite a growing literature on explaining neural networks, no consensus has been reached on how to evaluate those explanation methods. We propose IROF, a new approach to evaluating explanation methods that circumvents the need for manual evaluation. Compared to other recent work, our approach requires several orders of magnitude less computational resources and no human input, making it accessible to lower resource groups and robust to human bias.
Towards Federated Learning: Robustness Analytics to Data Heterogeneity
Feb 12, 2020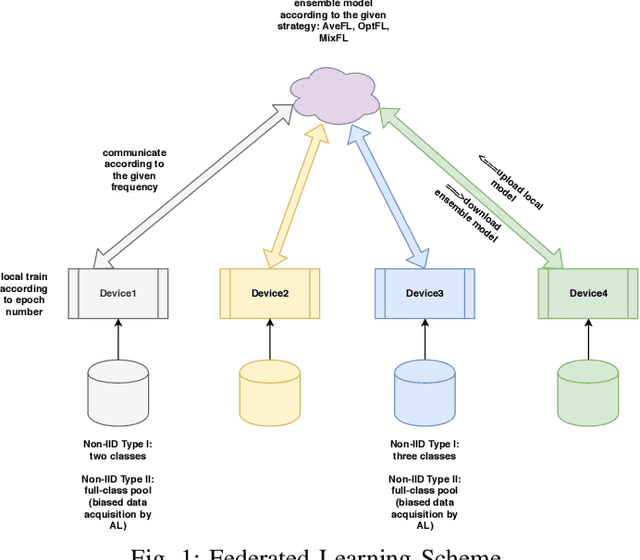
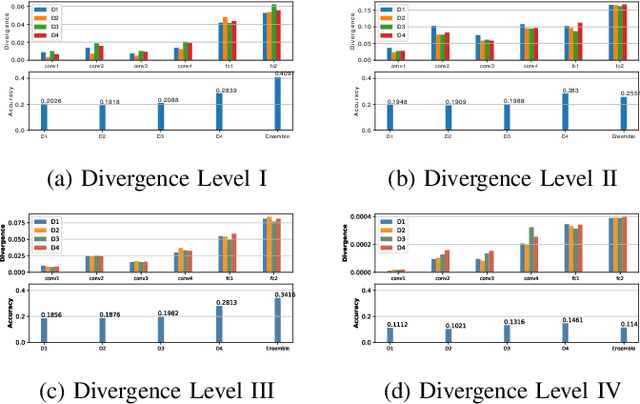
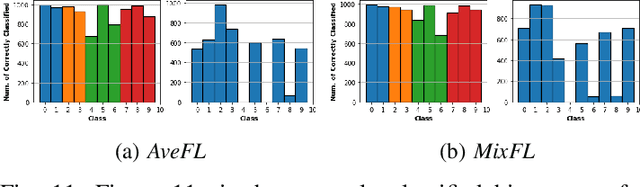
Federated Learning allows remote centralized server training models without to access the data stored in distributed (edge) devices. Most work assume the data generated from edge devices is identically and independently sampled from a common population distribution. However, such ideal sampling may not be realistic in many contexts where edge devices correspond to units in variable context. Also, models based on intrinsic agency, such as active sampling schemes, may lead to highly biased sampling. So an imminent question is how robust Federated Learning is to biased sampling? In this work, we investigate two such scenarios. First, we study Federated Learning of a classifier from data with edge device class distribution heterogeneity. Second, we study Federated Learning of a classifier with active sampling at the edge. We present evidence in both scenarios, that federated learning is robust to data heterogeneity.
Active Learning Solution on Distributed Edge Computing
Jun 25, 2019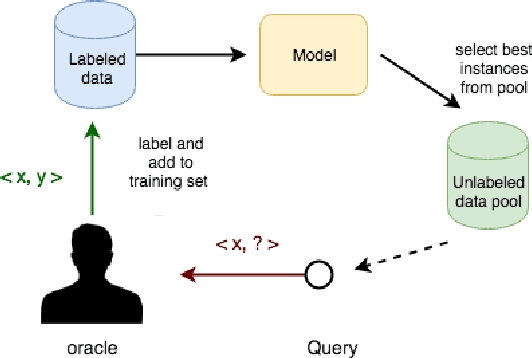
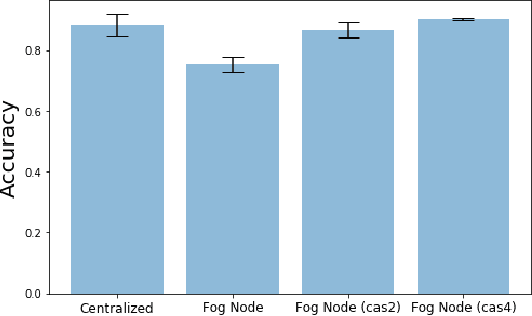
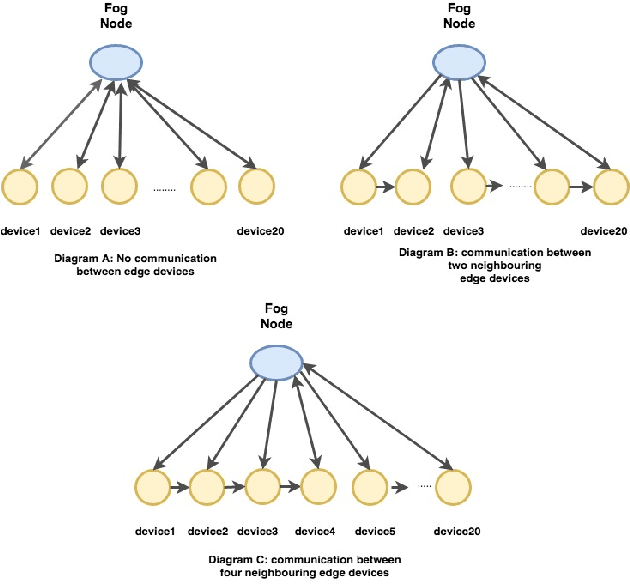
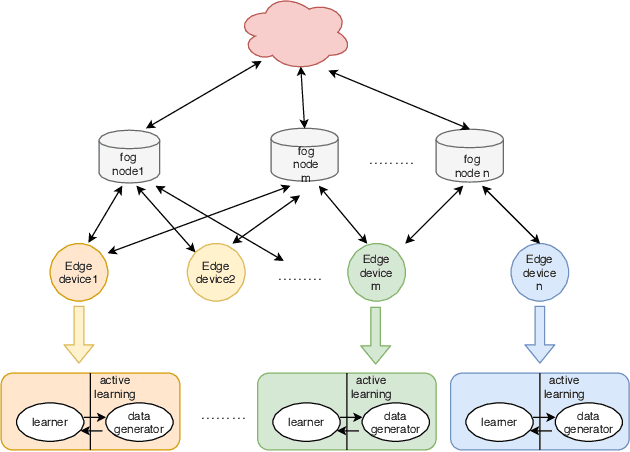
Industry 4.0 becomes possible through the convergence between Operational and Information Technologies. All the requirements to realize the convergence is integrated on the Fog Platform. Fog Platform is introduced between the cloud server and edge devices when the unprecedented generation of data causes the burden of the cloud server, leading the ineligible latency. In this new paradigm, we divide the computation tasks and push it down to edge devices. Furthermore, local computing (at edge side) may improve privacy and trust. To address these problems, we present a new method, in which we decompose the data aggregation and processing, by dividing them between edge devices and fog nodes intelligently. We apply active learning on edge devices; and federated learning on the fog node which significantly reduces the data samples to train the model as well as the communication cost. To show the effectiveness of the proposed method, we implemented and evaluated its performance for an image classification task. In addition, we consider two settings: massively distributed and non-massively distributed and offer the corresponding solutions.
Phase transition in PCA with missing data: Reduced signal-to-noise ratio, not sample size!
May 02, 2019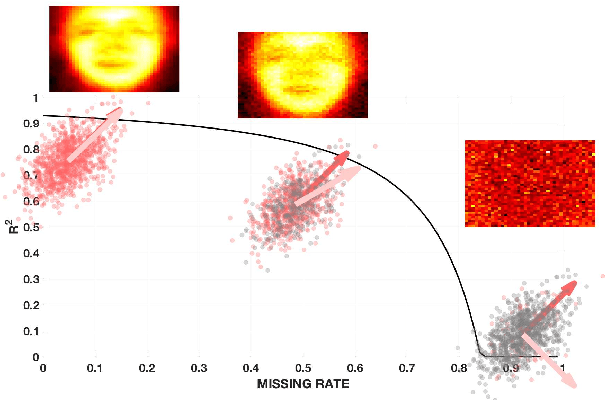
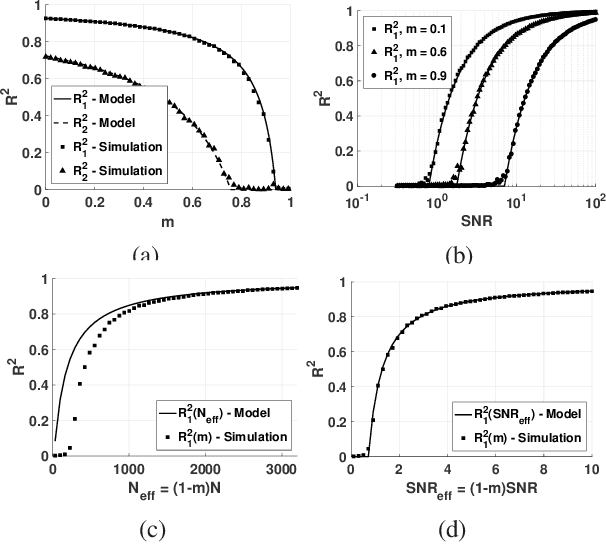
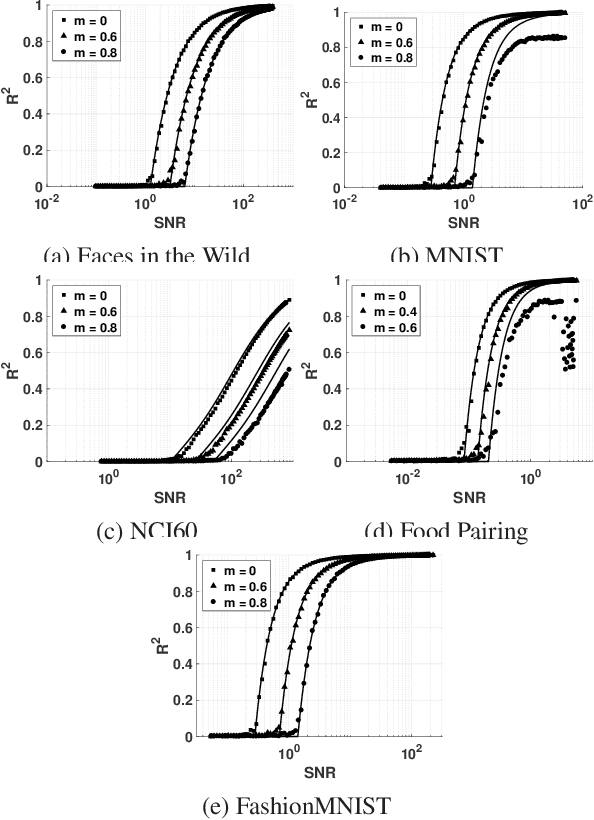
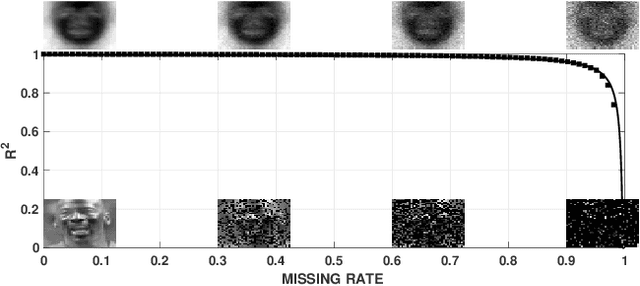
How does missing data affect our ability to learn signal structures? It has been shown that learning signal structure in terms of principal components is dependent on the ratio of sample size and dimensionality and that a critical number of observations is needed before learning starts (Biehl and Mietzner, 1993). Here we generalize this analysis to include missing data. Probabilistic principal component analysis is regularly used for estimating signal structures in datasets with missing data. Our analytic result suggests that the effect of missing data is to effectively reduce signal-to-noise ratio rather than - as generally believed - to reduce sample size. The theory predicts a phase transition in the learning curves and this is indeed found both in simulation data and in real datasets.
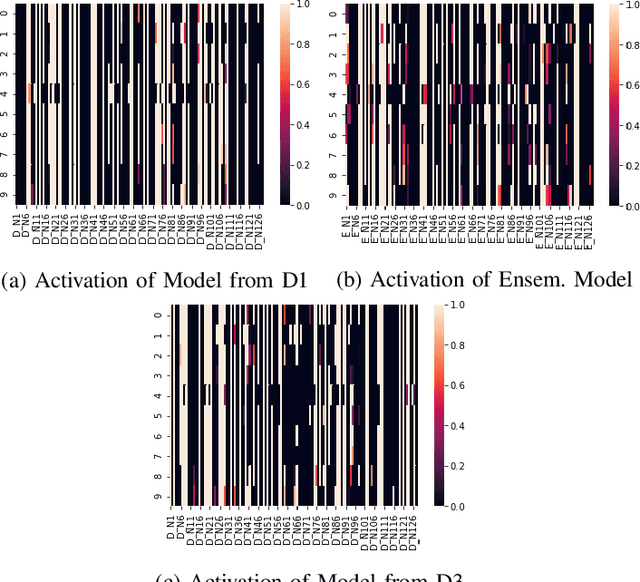
Aggregating explainability methods for neural networks stabilizes explanations
Mar 01, 2019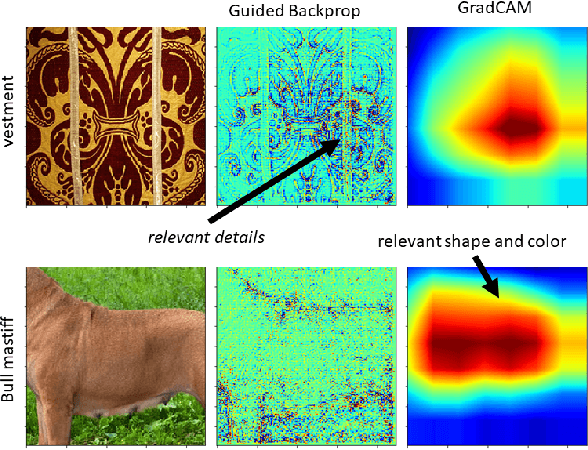


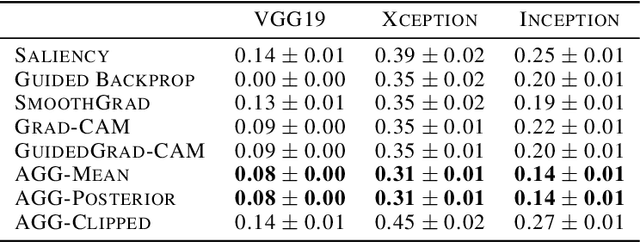
Despite a growing literature on explaining neural networks, no consensus has been reached on how to explain a neural network decision or how to evaluate an explanation. In fact, most works rely on manually assessing the explanation to evaluate the quality of a method. This injects uncertainty in the explanation process along several dimensions: Which explanation method to apply? Who should we ask to evaluate it and which criteria should be used for the evaluation? Our contributions in this paper are twofold. First, we investigate schemes to combine explanation methods and reduce model uncertainty to obtain a single aggregated explanation. Our findings show that the aggregation is more robust, well-aligned with human explanations and can attribute relevance to a broader set of features (completeness). Second, we propose a novel way of evaluating explanation methods that circumvents the need for manual evaluation and is not reliant on the alignment of neural networks and humans decision processes.
Multi-View Bayesian Correlated Component Analysis
Feb 07, 2018Correlated component analysis as proposed by Dmochowski et al. (2012) is a tool for investigating brain process similarity in the responses to multiple views of a given stimulus. Correlated components are identified under the assumption that the involved spatial networks are identical. Here we propose a hierarchical probabilistic model that can infer the level of universality in such multi-view data, from completely unrelated representations, corresponding to canonical correlation analysis, to identical representations as in correlated component analysis. This new model, which we denote Bayesian correlated component analysis, evaluates favourably against three relevant algorithms in simulated data. A well-established benchmark EEG dataset is used to further validate the new model and infer the variability of spatial representations across multiple subjects.
Latent Space Oddity: on the Curvature of Deep Generative Models
Jan 31, 2018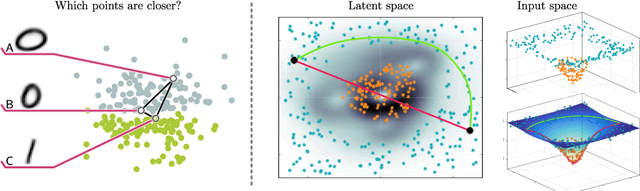
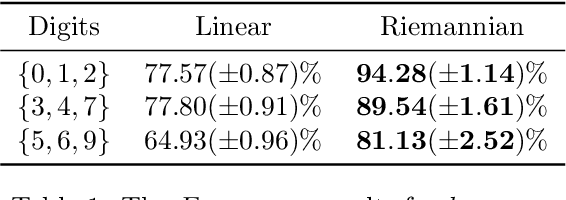
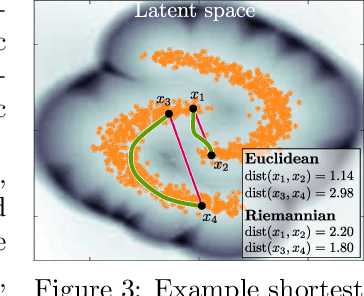

Deep generative models provide a systematic way to learn nonlinear data distributions, through a set of latent variables and a nonlinear "generator" function that maps latent points into the input space. The nonlinearity of the generator imply that the latent space gives a distorted view of the input space. Under mild conditions, we show that this distortion can be characterized by a stochastic Riemannian metric, and demonstrate that distances and interpolants are significantly improved under this metric. This in turn improves probability distributions, sampling algorithms and clustering in the latent space. Our geometric analysis further reveals that current generators provide poor variance estimates and we propose a new generator architecture with vastly improved variance estimates. Results are demonstrated on convolutional and fully connected variational autoencoders, but the formalism easily generalize to other deep generative models.