 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge graphs for empirical concept retrieval
Apr 10, 2024Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz.\ as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
Hubness Reduction Improves Sentence-BERT Semantic Spaces
Nov 30, 2023



Semantic representations of text, i.e. representations of natural language which capture meaning by geometry, are essential for areas such as information retrieval and document grouping. High-dimensional trained dense vectors have received much attention in recent years as such representations. We investigate the structure of semantic spaces that arise from embeddings made with Sentence-BERT and find that the representations suffer from a well-known problem in high dimensions called hubness. Hubness results in asymmetric neighborhood relations, such that some texts (the hubs) are neighbours of many other texts while most texts (so-called anti-hubs), are neighbours of few or no other texts. We quantify the semantic quality of the embeddings using hubness scores and error rate of a neighbourhood based classifier. We find that when hubness is high, we can reduce error rate and hubness using hubness reduction methods. We identify a combination of two methods as resulting in the best reduction. For example, on one of the tested pretrained models, this combined method can reduce hubness by about 75% and error rate by about 9%. Thus, we argue that mitigating hubness in the embedding space provides better semantic representations of text.
Concept-based explainability for an EEG transformer model
Jul 24, 2023



Deep learning models are complex due to their size, structure, and inherent randomness in training procedures. Additional complexity arises from the selection of datasets and inductive biases. Addressing these challenges for explainability, Kim et al. (2018) introduced Concept Activation Vectors (CAVs), which aim to understand deep models' internal states in terms of human-aligned concepts. These concepts correspond to directions in latent space, identified using linear discriminants. Although this method was first applied to image classification, it was later adapted to other domains, including natural language processing. In this work, we attempt to apply the method to electroencephalogram (EEG) data for explainability in Kostas et al.'s BENDR (2021), a large-scale transformer model. A crucial part of this endeavor involves defining the explanatory concepts and selecting relevant datasets to ground concepts in the latent space. Our focus is on two mechanisms for EEG concept formation: the use of externally labeled EEG datasets, and the application of anatomically defined concepts. The former approach is a straightforward generalization of methods used in image classification, while the latter is novel and specific to EEG. We present evidence that both approaches to concept formation yield valuable insights into the representations learned by deep EEG models.
Using Sequences of Life-events to Predict Human Lives
Jun 05, 2023Over the past decade, machine learning has revolutionized computers' ability to analyze text through flexible computational models. Due to their structural similarity to written language, transformer-based architectures have also shown promise as tools to make sense of a range of multi-variate sequences from protein-structures, music, electronic health records to weather-forecasts. We can also represent human lives in a way that shares this structural similarity to language. From one perspective, lives are simply sequences of events: People are born, visit the pediatrician, start school, move to a new location, get married, and so on. Here, we exploit this similarity to adapt innovations from natural language processing to examine the evolution and predictability of human lives based on detailed event sequences. We do this by drawing on arguably the most comprehensive registry data in existence, available for an entire nation of more than six million individuals across decades. Our data include information about life-events related to health, education, occupation, income, address, and working hours, recorded with day-to-day resolution. We create embeddings of life-events in a single vector space showing that this embedding space is robust and highly structured. Our models allow us to predict diverse outcomes ranging from early mortality to personality nuances, outperforming state-of-the-art models by a wide margin. Using methods for interpreting deep learning models, we probe the algorithm to understand the factors that enable our predictions. Our framework allows researchers to identify new potential mechanisms that impact life outcomes and associated possibilities for personalized interventions.
Masked Autoencoders with Multi-Window Attention Are Better Audio Learners
Jun 01, 2023



Several recent works have adapted Masked Autoencoders (MAEs) for learning general-purpose audio representations. However, they do not address two key aspects of modelling multi-domain audio data: (i) real-world audio tasks consist of a combination of local+global contexts, and (ii) real-world audio signals are complex compositions of several acoustic elements with different time-frequency characteristics. To address these concerns, this work proposes a Multi-Window Masked Autoencoder (MW-MAE) fitted with a novel Multi-Window Multi-Head Attention module that can capture information at multiple local and global contexts in every decoder transformer block through attention heads of several distinct local and global windows. Empirical results on ten downstream audio tasks show that MW-MAEs consistently outperform standard MAEs in overall performance and learn better general-purpose audio representations, as well as demonstrate considerably better scaling characteristics. Exploratory analyses of the learned representations reveals that MW-MAE encoders learn attention heads with more distinct entropies compared to those learned by MAEs, while attention heads across the different transformer blocks in MW-MAE decoders learn correlated feature representations, enabling each block to independently capture local and global information, leading to a decoupled feature hierarchy. Code for feature extraction and downstream experiments along with pre-trained weights can be found at https://github.com/10997NeurIPS23/10997_mwmae.
On convex conceptual regions in deep network representations
May 26, 2023



The current study of human-machine alignment aims at understanding the geometry of latent spaces and the correspondence to human representations. G\"ardenfors' conceptual spaces is a prominent framework for understanding human representations. Convexity of object regions in conceptual spaces is argued to promote generalizability, few-shot learning, and intersubject alignment. Based on these insights, we investigate the notion of convexity of concept regions in machine-learned latent spaces. We develop a set of tools for measuring convexity in sampled data and evaluate emergent convexity in layered representations of state-of-the-art deep networks. We show that convexity is robust to basic re-parametrization, hence, meaningful as a quality of machine-learned latent spaces. We find that approximate convexity is pervasive in neural representations in multiple application domains, including models of images, audio, human activity, text, and brain data. We measure convexity separately for labels (i.e., targets for fine-tuning) and other concepts. Generally, we observe that fine-tuning increases the convexity of label regions, while for more general concepts, it depends on the alignment of the concept with the fine-tuning objective. We find evidence that pre-training convexity of class label regions predicts subsequent fine-tuning performance.
Robustness of Visual Explanations to Common Data Augmentation
Apr 18, 2023



As the use of deep neural networks continues to grow, understanding their behaviour has become more crucial than ever. Post-hoc explainability methods are a potential solution, but their reliability is being called into question. Our research investigates the response of post-hoc visual explanations to naturally occurring transformations, often referred to as augmentations. We anticipate explanations to be invariant under certain transformations, such as changes to the colour map while responding in an equivariant manner to transformations like translation, object scaling, and rotation. We have found remarkable differences in robustness depending on the type of transformation, with some explainability methods (such as LRP composites and Guided Backprop) being more stable than others. We also explore the role of training with data augmentation. We provide evidence that explanations are typically less robust to augmentation than classification performance, regardless of whether data augmentation is used in training or not.
On the role of Model Uncertainties in Bayesian Optimization
Jan 14, 2023



Bayesian optimization (BO) is a popular method for black-box optimization, which relies on uncertainty as part of its decision-making process when deciding which experiment to perform next. However, not much work has addressed the effect of uncertainty on the performance of the BO algorithm and to what extent calibrated uncertainties improve the ability to find the global optimum. In this work, we provide an extensive study of the relationship between the BO performance (regret) and uncertainty calibration for popular surrogate models and compare them across both synthetic and real-world experiments. Our results confirm that Gaussian Processes are strong surrogate models and that they tend to outperform other popular models. Our results further show a positive association between calibration error and regret, but interestingly, this association disappears when we control for the type of model in the analysis. We also studied the effect of re-calibration and demonstrate that it generally does not lead to improved regret. Finally, we provide theoretical justification for why uncertainty calibration might be difficult to combine with BO due to the small sample sizes commonly used.
Topic Model Robustness to Automatic Speech Recognition Errors in Podcast Transcripts
Sep 25, 2021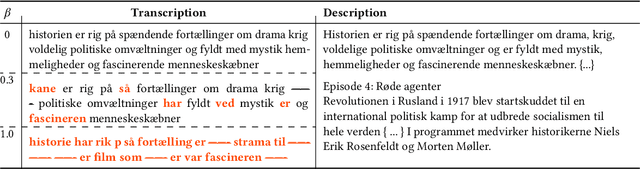
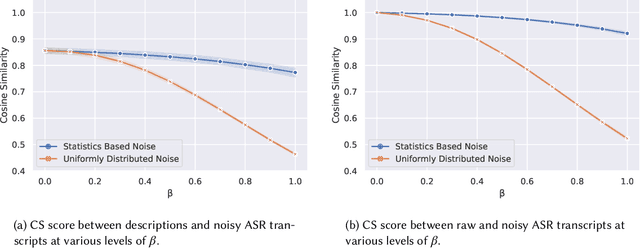

For a multilingual podcast streaming service, it is critical to be able to deliver relevant content to all users independent of language. Podcast content relevance is conventionally determined using various metadata sources. However, with the increasing quality of speech recognition in many languages, utilizing automatic transcriptions to provide better content recommendations becomes possible. In this work, we explore the robustness of a Latent Dirichlet Allocation topic model when applied to transcripts created by an automatic speech recognition engine. Specifically, we explore how increasing transcription noise influences topics obtained from transcriptions in Danish; a low resource language. First, we observe a baseline of cosine similarity scores between topic embeddings from automatic transcriptions and the descriptions of the podcasts written by the podcast creators. We then observe how the cosine similarities decrease as transcription noise increases and conclude that even when automatic speech recognition transcripts are erroneous, it is still possible to obtain high-quality topic embeddings from the transcriptions.
Generalization by design: Shortcuts to Generalization in Deep Learning
Jul 05, 2021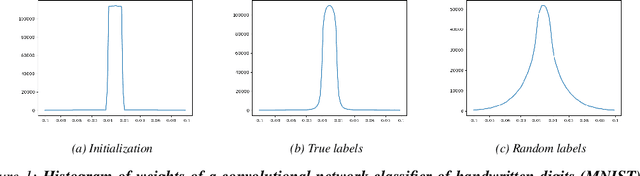

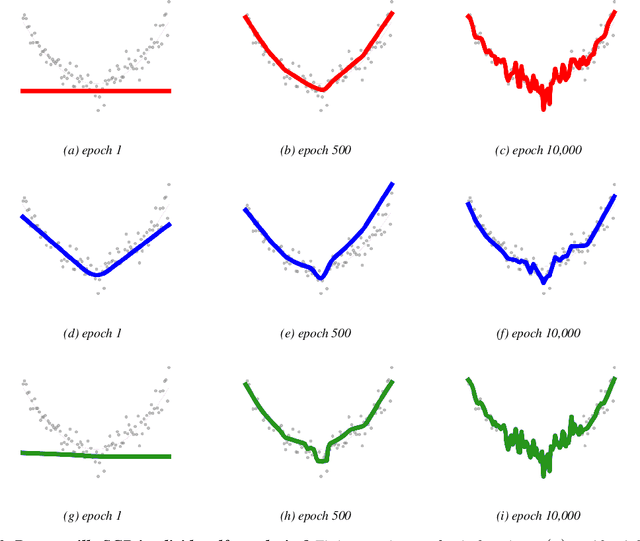
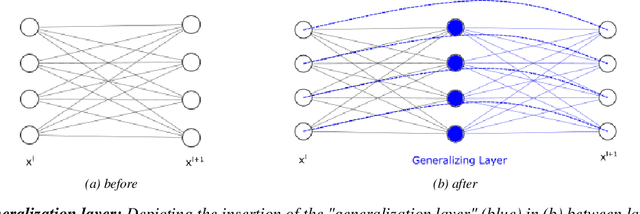
We take a geometrical viewpoint and present a unifying view on supervised deep learning with the Bregman divergence loss function - this entails frequent classification and prediction tasks. Motivated by simulations we suggest that there is principally no implicit bias of vanilla stochastic gradient descent training of deep models towards "simpler" functions. Instead, we show that good generalization may be instigated by bounded spectral products over layers leading to a novel geometric regularizer. It is revealed that in deep enough models such a regularizer enables both, extreme accuracy and generalization, to be reached. We associate popular regularization techniques like weight decay, drop out, batch normalization, and early stopping with this perspective. Backed up by theory we further demonstrate that "generalization by design" is practically possible and that good generalization may be encoded into the structure of the network. We design two such easy-to-use structural regularizers that insert an additional \textit{generalization layer} into a model architecture, one with a skip connection and another one with drop-out. We verify our theoretical results in experiments on various feedforward and convolutional architectures, including ResNets, and datasets (MNIST, CIFAR10, synthetic data). We believe this work opens up new avenues of research towards better generalizing architectures.