 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferential Private Hogwild! over Distributed Local Data Sets
Feb 17, 2021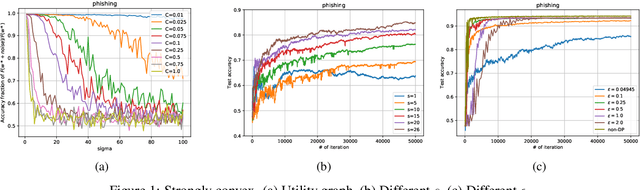

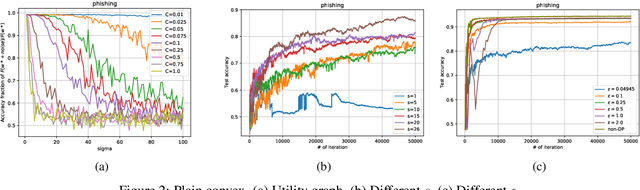
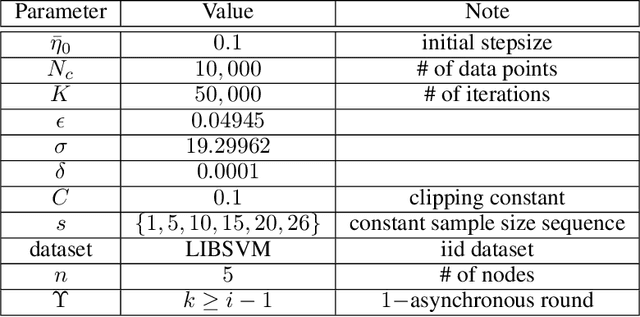
We consider the Hogwild! setting where clients use local SGD iterations with Gaussian based Differential Privacy (DP) for their own local data sets with the aim of (1) jointly converging to a global model (by interacting at a round to round basis with a centralized server that aggregates local SGD updates into a global model) while (2) keeping each local data set differentially private with respect to the outside world (this includes all other clients who can monitor client-server interactions). We show for a broad class of sample size sequences (this defines the number of local SGD iterations for each round) that a local data set is $(\epsilon,\delta)$-DP if the standard deviation $\sigma$ of the added Gaussian noise per round interaction with the centralized server is at least $\sqrt{2(\epsilon+ \ln(1/\delta))/\epsilon}$.
Shuffling Gradient-Based Methods with Momentum
Nov 24, 2020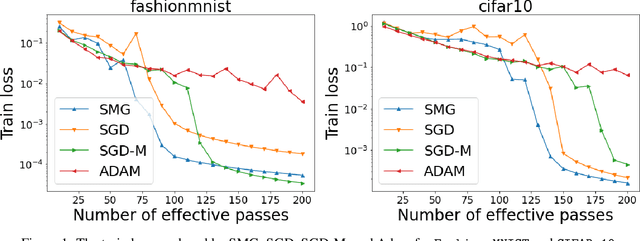
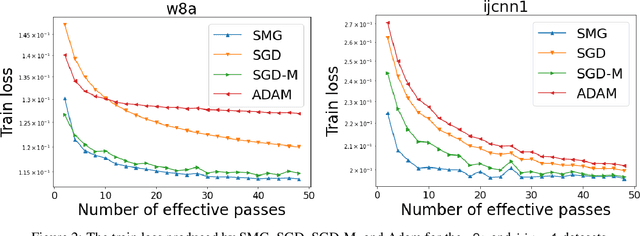
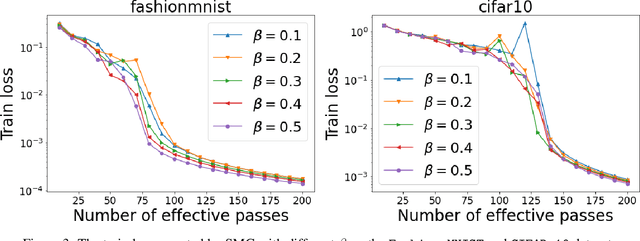
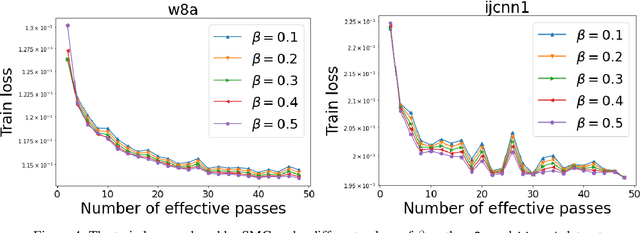
We combine two advanced ideas widely used in optimization for machine learning: shuffling strategy and momentum technique to develop a novel shuffling gradient-based method with momentum to approximate a stationary point of non-convex finite-sum minimization problems. While our method is inspired by momentum techniques, its update is significantly different from existing momentum-based methods. We establish that our algorithm achieves a state-of-the-art convergence rate for both constant and diminishing learning rates under standard assumptions (i.e., $L$-smoothness and bounded variance). When the shuffling strategy is fixed, we develop another new algorithm that is similar to existing momentum methods. This algorithm covers the single-shuffling and incremental gradient schemes as special cases. We prove the same convergence rate of this algorithm under the $L$-smoothness and bounded gradient assumptions. We demonstrate our algorithms via numerical simulations on standard datasets and compare them with existing shuffling methods. Our tests have shown encouraging performance of the new algorithms.
A Scalable MIP-based Method for Learning Optimal Multivariate Decision Trees
Nov 06, 2020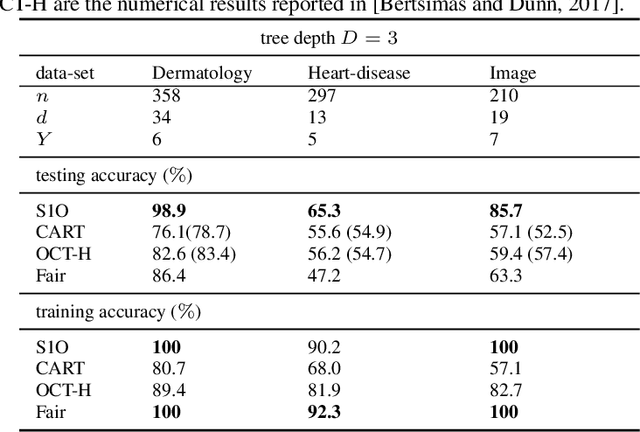
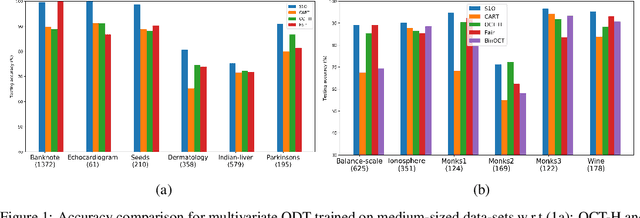
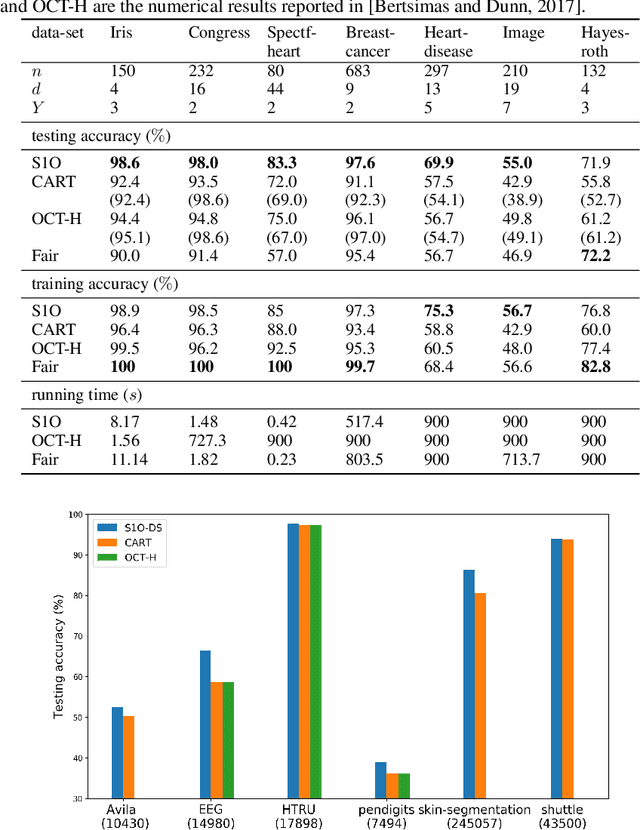
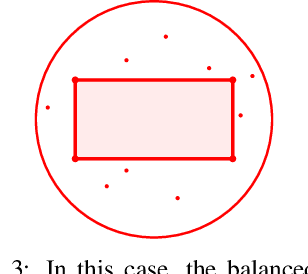
Several recent publications report advances in training optimal decision trees (ODT) using mixed-integer programs (MIP), due to algorithmic advances in integer programming and a growing interest in addressing the inherent suboptimality of heuristic approaches such as CART. In this paper, we propose a novel MIP formulation, based on a 1-norm support vector machine model, to train a multivariate ODT for classification problems. We provide cutting plane techniques that tighten the linear relaxation of the MIP formulation, in order to improve run times to reach optimality. Using 36 data-sets from the University of California Irvine Machine Learning Repository, we demonstrate that our formulation outperforms its counterparts in the literature by an average of about 10% in terms of mean out-of-sample testing accuracy across the data-sets. We provide a scalable framework to train multivariate ODT on large data-sets by introducing a novel linear programming (LP) based data selection method to choose a subset of the data for training. Our method is able to routinely handle large data-sets with more than 7,000 sample points and outperform heuristics methods and other MIP based techniques. We present results on data-sets containing up to 245,000 samples. Existing MIP-based methods do not scale well on training data-sets beyond 5,500 samples.
Hogwild! over Distributed Local Data Sets with Linearly Increasing Mini-Batch Sizes
Oct 27, 2020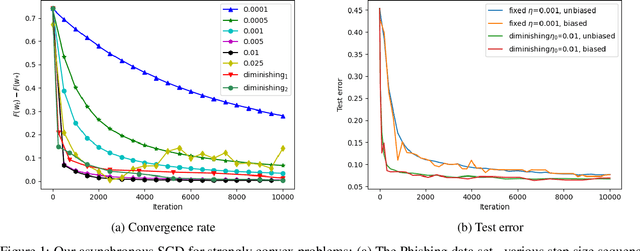

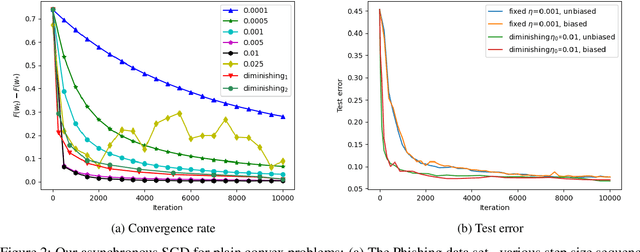
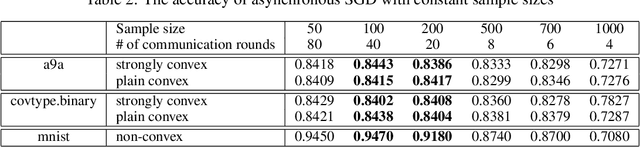
Hogwild! implements asynchronous Stochastic Gradient Descent (SGD) where multiple threads in parallel access a common repository containing training data, perform SGD iterations and update shared state that represents a jointly learned (global) model. We consider big data analysis where training data is distributed among local data sets -- and we wish to move SGD computations to local compute nodes where local data resides. The results of these local SGD computations are aggregated by a central "aggregator" which mimics Hogwild!. We show how local compute nodes can start choosing small mini-batch sizes which increase to larger ones in order to reduce communication cost (round interaction with the aggregator). We prove a tight and novel non-trivial convergence analysis for strongly convex problems which does not use the bounded gradient assumption as seen in many existing publications. The tightness is a consequence of our proofs for lower and upper bounds of the convergence rate, which show a constant factor difference. We show experimental results for plain convex and non-convex problems for biased and unbiased local data sets.
An Optimal Hybrid Variance-Reduced Algorithm for Stochastic Composite Nonconvex Optimization
Aug 20, 2020In this note we propose a new variant of the hybrid variance-reduced proximal gradient method in [7] to solve a common stochastic composite nonconvex optimization problem under standard assumptions. We simply replace the independent unbiased estimator in our hybrid- SARAH estimator introduced in [7] by the stochastic gradient evaluated at the same sample, leading to the identical momentum-SARAH estimator introduced in [2]. This allows us to save one stochastic gradient per iteration compared to [7], and only requires two samples per iteration. Our algorithm is very simple and achieves optimal stochastic oracle complexity bound in terms of stochastic gradient evaluations (up to a constant factor). Our analysis is essentially inspired by [7], but we do not use two different step-sizes.
Asynchronous Federated Learning with Reduced Number of Rounds and with Differential Privacy from Less Aggregated Gaussian Noise
Jul 17, 2020

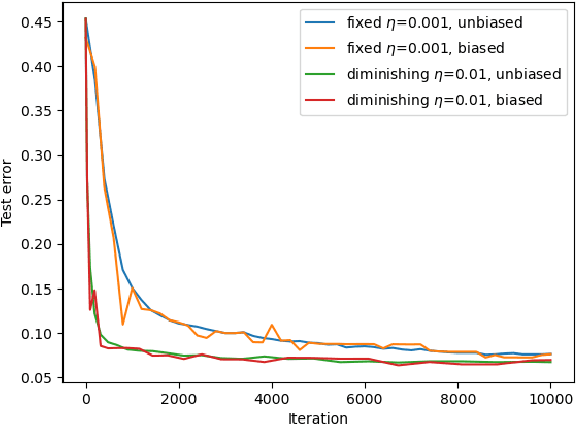

The feasibility of federated learning is highly constrained by the server-clients infrastructure in terms of network communication. Most newly launched smartphones and IoT devices are equipped with GPUs or sufficient computing hardware to run powerful AI models. However, in case of the original synchronous federated learning, client devices suffer waiting times and regular communication between clients and server is required. This implies more sensitivity to local model training times and irregular or missed updates, hence, less or limited scalability to large numbers of clients and convergence rates measured in real time will suffer. We propose a new algorithm for asynchronous federated learning which eliminates waiting times and reduces overall network communication - we provide rigorous theoretical analysis for strongly convex objective functions and provide simulation results. By adding Gaussian noise we show how our algorithm can be made differentially private -- new theorems show how the aggregated added Gaussian noise is significantly reduced.
Hybrid Variance-Reduced SGD Algorithms For Nonconvex-Concave Minimax Problems
Jun 27, 2020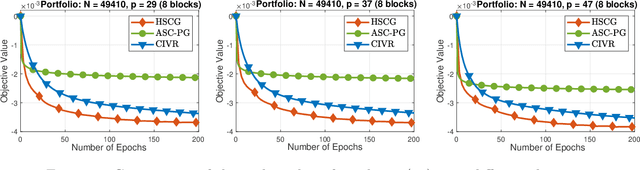
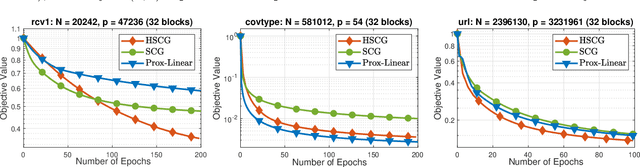
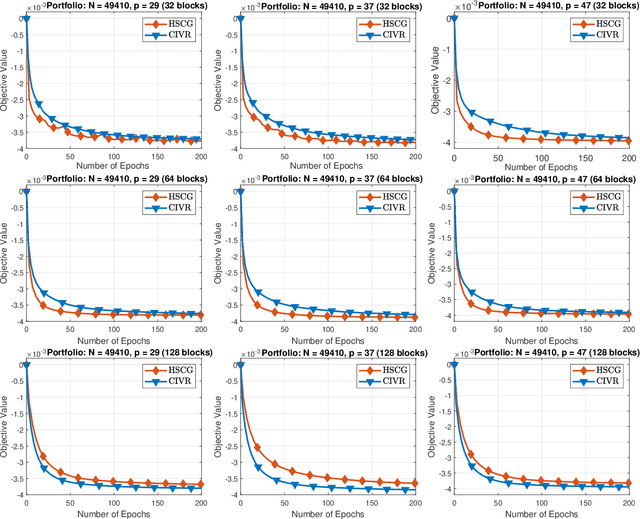
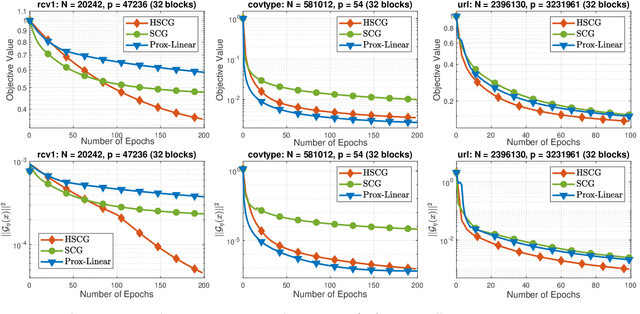
We develop a novel variance-reduced algorithm to solve a stochastic nonconvex-concave minimax problem which has various applications in different fields. This problem has several computational challenges due to its nonsmoothness, nonconvexity, nonlinearity, and non-separability of the objective functions. Our approach relies on a novel combination of recent ideas, including smoothing and hybrid stochastic variance-reduced techniques. Our algorithm and its variants can achieve $\mathcal{O}(T^{-2/3})$-convergence rate in $T$, and the best-known oracle complexity under standard assumptions. They have several computational advantages compared to existing methods. They can also work with both single sample or mini-batch on derivative estimators, with constant or diminishing step-sizes. We demonstrate the benefits of our algorithms over existing methods through two numerical examples.
Finite-Time Analysis of Stochastic Gradient Descent under Markov Randomness
Apr 01, 2020Motivated by broad applications in reinforcement learning and machine learning, this paper considers the popular stochastic gradient descent (SGD) when the gradients of the underlying objective function are sampled from Markov processes. This Markov sampling leads to the gradient samples being biased and not independent. The existing results for the convergence of SGD under Markov randomness are often established under the assumptions on the boundedness of either the iterates or the gradient samples. Our main focus is to study the finite-time convergence of SGD for different types of objective functions, without requiring these assumptions. We show that SGD converges nearly at the same rate with Markovian gradient samples as with independent gradient samples. The only difference is a logarithmic factor that accounts for the mixing time of the Markov chain.
A Hybrid Stochastic Policy Gradient Algorithm for Reinforcement Learning
Mar 01, 2020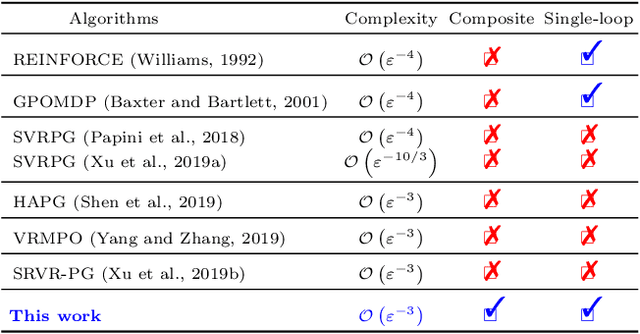
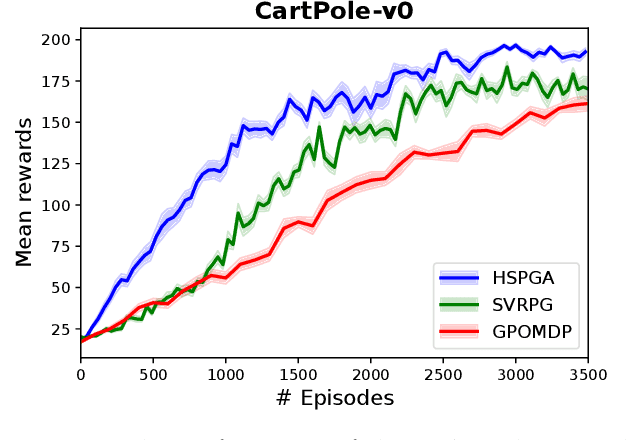
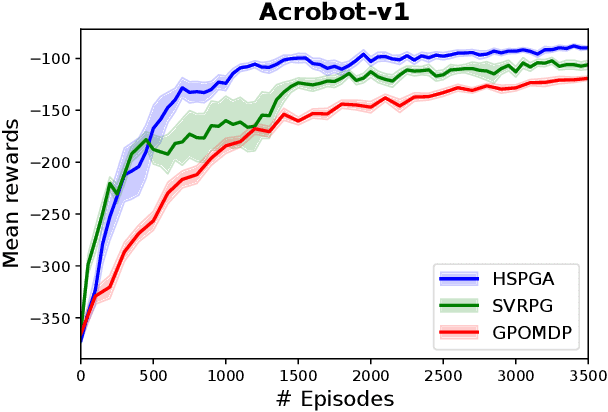
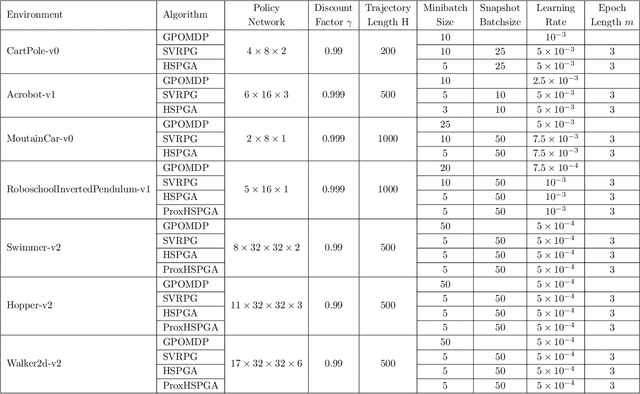
We propose a novel hybrid stochastic policy gradient estimator by combining an unbiased policy gradient estimator, the REINFORCE estimator, with another biased one, an adapted SARAH estimator for policy optimization. The hybrid policy gradient estimator is shown to be biased, but has variance reduced property. Using this estimator, we develop a new Proximal Hybrid Stochastic Policy Gradient Algorithm (ProxHSPGA) to solve a composite policy optimization problem that allows us to handle constraints or regularizers on the policy parameters. We first propose a single-looped algorithm then introduce a more practical restarting variant. We prove that both algorithms can achieve the best-known trajectory complexity $\mathcal{O}\left(\varepsilon^{-3}\right)$ to attain a first-order stationary point for the composite problem which is better than existing REINFORCE/GPOMDP $\mathcal{O}\left(\varepsilon^{-4}\right)$ and SVRPG $\mathcal{O}\left(\varepsilon^{-10/3}\right)$ in the non-composite setting. We evaluate the performance of our algorithm on several well-known examples in reinforcement learning. Numerical results show that our algorithm outperforms two existing methods on these examples. Moreover, the composite settings indeed have some advantages compared to the non-composite ones on certain problems.
A Unified Convergence Analysis for Shuffling-Type Gradient Methods
Feb 19, 2020
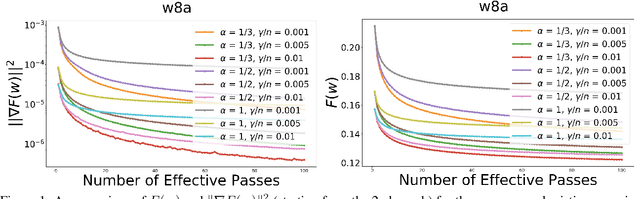
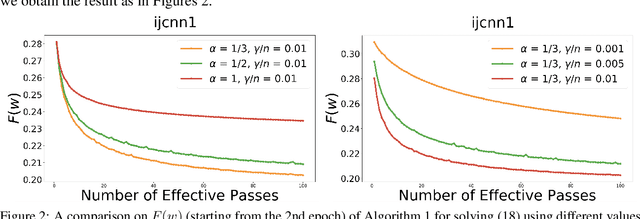
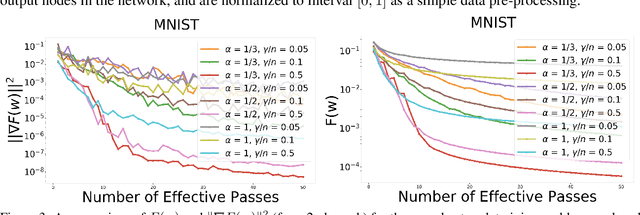
In this paper, we provide a unified convergence analysis for a class of shuffling-type gradient methods for solving a well-known finite-sum minimization problem commonly used in machine learning. This algorithm covers various variants such as randomized reshuffling, single shuffling, and cyclic/incremental gradient schemes. We consider two different settings: strongly convex and non-convex problems. Our main contribution consists of new non-asymptotic and asymptotic convergence rates for a general class of shuffling-type gradient methods to solve both non-convex and strongly convex problems. While our rate in the non-convex problem is new (i.e. not known yet under standard assumptions), the rate on the strongly convex case matches (up to a constant) the best-known results. However, unlike existing works in this direction, we only use standard assumptions such as smoothness and strong convexity. Finally, we empirically illustrate the effect of learning rates via a non-convex logistic regression and neural network examples.