 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying the Modeling of Arbitrary Conditionals in Natural Language
Jun 12, 2026Causal Transformers model sequences through an autoregressive factorization of the joint distribution, which enables efficient left-to-right decoding and conditional likelihood computation. However, they cannot tractably sample from or evaluate arbitrary conditionals -- e.g., a block of text conditioned on past and future tokens. Recent work aims to solve this problem through novel architectures, but they often lead to sub-optimal modeling of such conditionals and degraded generations. We propose Arbitrary Conditionals GPT (AC-GPT) which introduces a simple modification to standard causal Transformers to enable evaluating and sampling from arbitrary conditionals -- including past, future, and mixed contexts -- within a single forward pass. Unlike prior approaches, our method preserves the standard left-to-right ordering and next-token prediction objective essential for both strong performance and efficient training on natural language. Crucially, this compatibility allows existing LLMs to be fine-tuned for arbitrary conditioning. Our empirical results indicate that our method outperforms baselines on modeling arbitrary conditionals, without degrading standard left-to-right performance.
Clarifying MCMC-based training of modern EBMs : Contrastive Divergence versus Maximum Likelihood
Feb 24, 2022
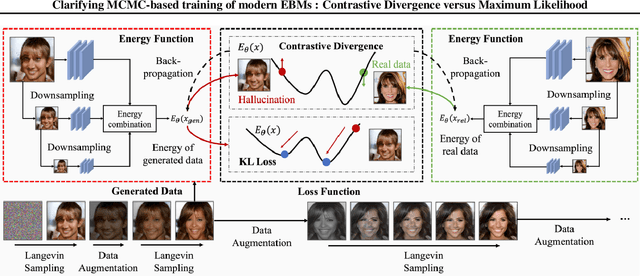


The Energy-Based Model (EBM) framework is a very general approach to generative modeling that tries to learn and exploit probability distributions only defined though unnormalized scores. It has risen in popularity recently thanks to the impressive results obtained in image generation by parameterizing the distribution with Convolutional Neural Networks (CNN). However, the motivation and theoretical foundations behind modern EBMs are often absent from recent papers and this sometimes results in some confusion. In particular, the theoretical justifications behind the popular MCMC-based learning algorithm Contrastive Divergence (CD) are often glossed over and we find that this leads to theoretical errors in recent influential papers (Du & Mordatch, 2019; Du et al., 2020). After offering a first-principles introduction of MCMC-based training, we argue that the learning algorithm they use can in fact not be described as CD and reinterpret theirs methods in light of a new interpretation. Finally, we discuss the implications of our new interpretation and provide some illustrative experiments.