 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Impact of Fault localization Granularity for Repository-Scale Code Repair Tasks
Mar 31, 2026Automatic program repair can be a challenging task, especially when resolving complex issues at a repository-level, which often involves issue reproduction, fault localization, code repair, testing and validation. Issues of this scale can be commonly found in popular GitHub repositories or datasets that are derived from them. Some repository-level approaches separate localization and repair into distinct phases. Where this is the case, the fault localization approaches vary in terms of the granularity of localization. Where the impact of granularity is explored to some degree for smaller datasets, not all isolate this issue from the separate question of localization accuracy by testing code repair under the assumption of perfect fault localization. To the best of the authors' knowledge, no repository-scale studies have explicitly investigated granularity under this assumption, nor conducted a systematic empirical comparison of granularity levels in isolation. We propose a framework for performing such tests by modifying the localization phase of the Agentless framework to retrieve ground-truth localization data and include this as context in the prompt fed to the repair phase. We show that under this configuration and as a generalization over the SWE-Bench-Mini dataset, function-level granularity yields the highest repair rate against line-level and file-level. However, a deeper dive suggests that the ideal granularity may in fact be task dependent. This study is not intended to improve on the state-of-the-art, nor do we intend for results to be compared against any complete agentic frameworks. Rather, we present a proof of concept for investigating how fault localization may impact automatic code repair in repository-scale scenarios. We present preliminary findings to this end and encourage further research into this relationship between the two phases.
Contrastive Counterfactual Visual Explanations With Overdetermination
Jun 28, 2021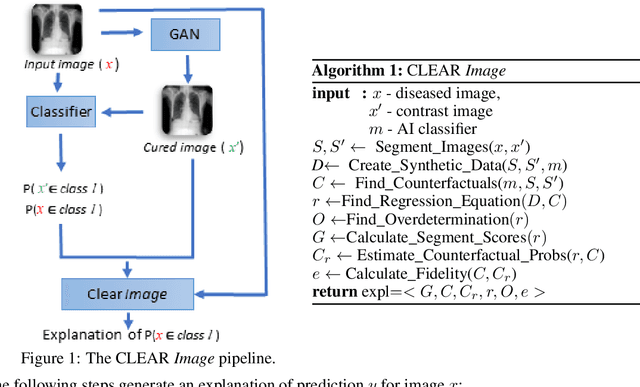
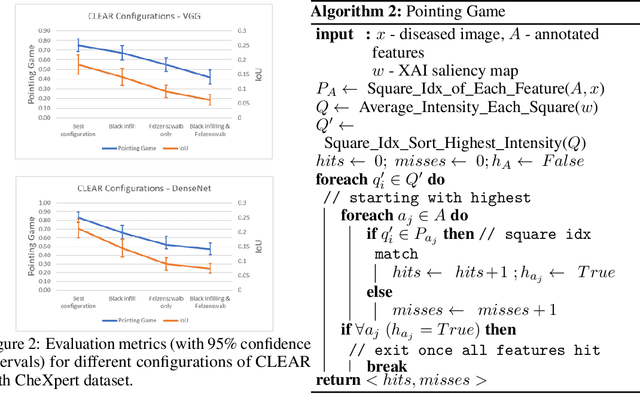

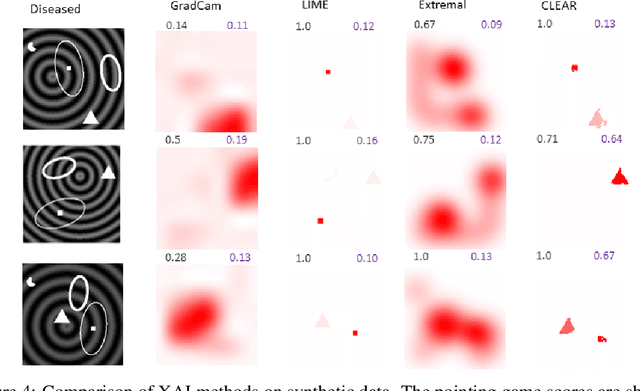
A novel explainable AI method called CLEAR Image is introduced in this paper. CLEAR Image is based on the view that a satisfactory explanation should be contrastive, counterfactual and measurable. CLEAR Image explains an image's classification probability by contrasting the image with a corresponding image generated automatically via adversarial learning. This enables both salient segmentation and perturbations that faithfully determine each segment's importance. CLEAR Image was successfully applied to a medical imaging case study where it outperformed methods such as Grad-CAM and LIME by an average of 27% using a novel pointing game metric. CLEAR Image excels in identifying cases of "causal overdetermination" where there are multiple patches in an image, any one of which is sufficient by itself to cause the classification probability to be close to one.