 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Guided Named Entity Recognition
Nov 10, 2019
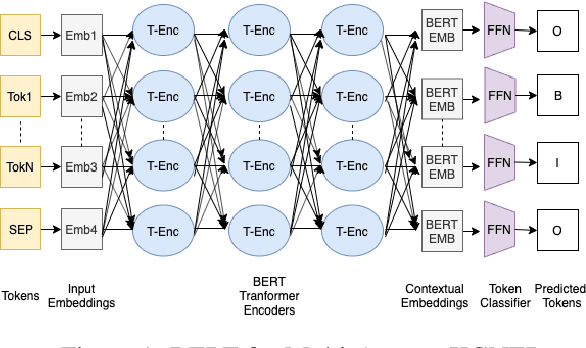
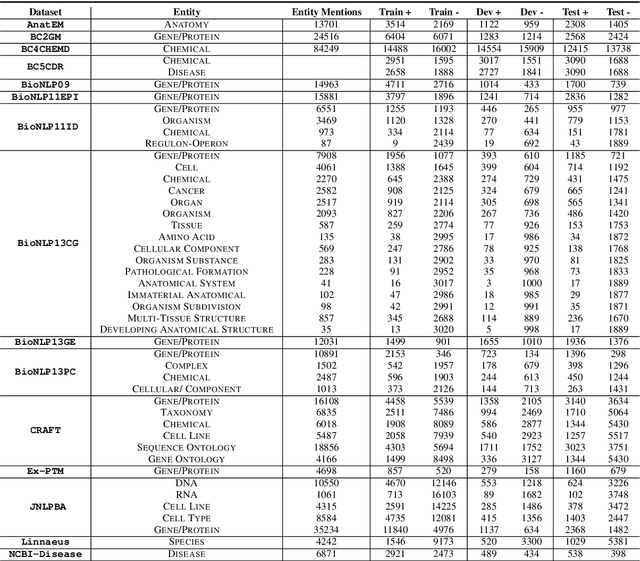
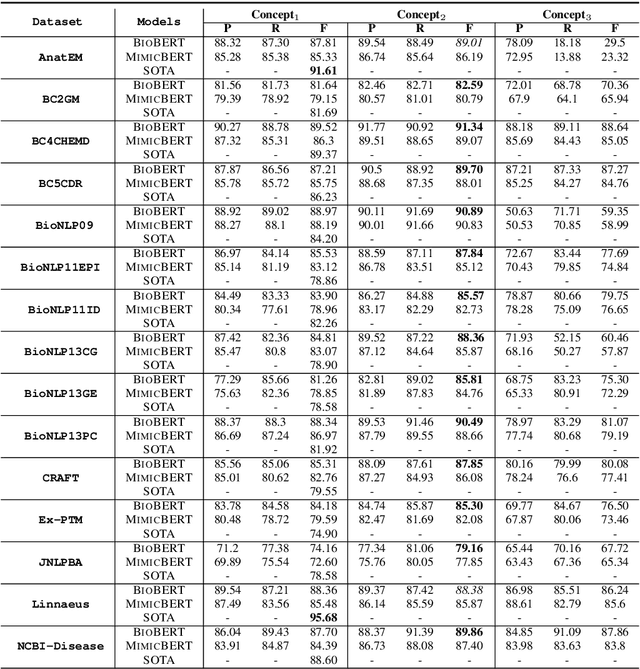
In this work, we try to perform Named Entity Recognition (NER) with external knowledge. We formulate the NER task as a multi-answer question answering (MAQA) task and provide different knowledge contexts, such as entity types, questions, definitions, and definitions with examples. Moreover, the formulation of the task as a MAQA task helps to reduce other errors. This formulation (a) enables systems to jointly learn from varied NER datasets, enabling systems to learn more NER specific features, (b) can use knowledge-text attention to identify words having higher similarity to 'entity type' mentioned in the knowledge, improving performance, (c) reduces confusion in systems by reducing the classes to be predicted, limited to only three (B, I, O), (d) Makes detection of Nested Entities easier. We perform extensive experiments of this Knowledge Guided NER (KGNER) formulation on 15 Biomedical NER datasets, and through these experiments, we see external knowledge helps. We will release the code for dataset conversion and our trained models for replicating experiments.
Exploring ways to incorporate additional knowledge to improve Natural Language Commonsense Question Answering
Sep 19, 2019
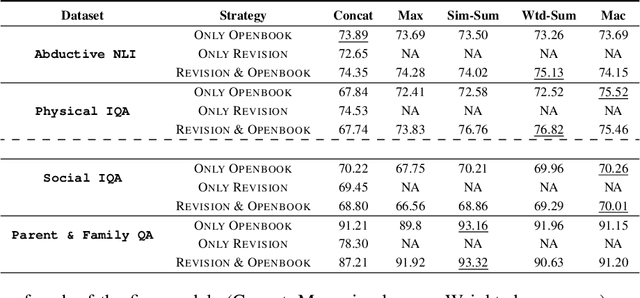
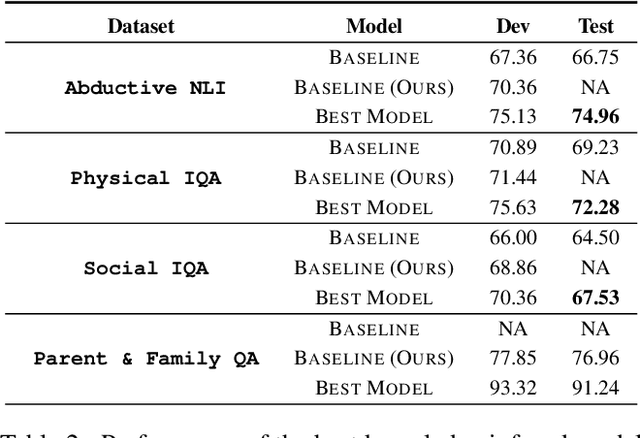
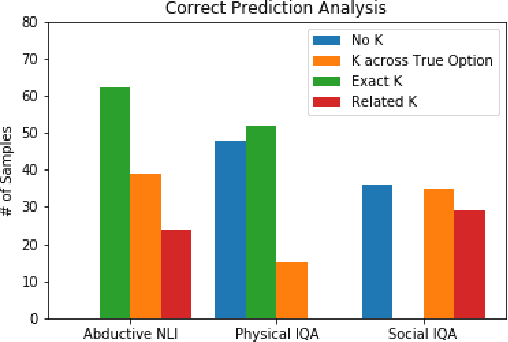
DARPA and Allen AI have proposed a collection of datasets to encourage research in Question Answering domains where (commonsense) knowledge is expected to play an important role. Recent language models such as BERT and GPT that have been pre-trained on Wikipedia articles and books, have shown decent performance with little fine-tuning on several such Multiple Choice Question-Answering (MCQ) datasets. Our goal in this work is to develop methods to incorporate additional (commonsense) knowledge into language model based approaches for better question answering in such domains. In this work we first identify external knowledge sources, and show that the performance further improves when a set of facts retrieved through IR is prepended to each MCQ question during both training and test phase. We then explore if the performance can be further improved by providing task specific knowledge in different manners or by employing different strategies for using the available knowledge. We present three different modes of passing knowledge and five different models of using knowledge including the standard BERT MCQ model. We also propose a novel architecture to deal with situations where information to answer the MCQ question is scattered over multiple knowledge sentences. We take 200 predictions from each of our best models and analyze how often the given knowledge is useful, how many times the given knowledge is useful but system failed to use it and some other metrices to see the scope of further improvements.
Careful Selection of Knowledge to solve Open Book Question Answering
Jul 24, 2019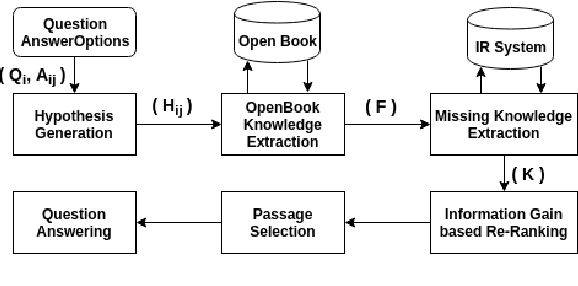

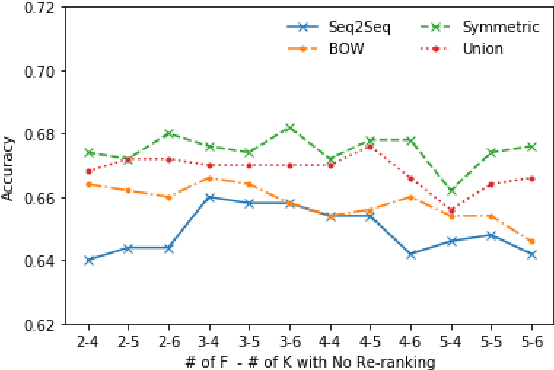
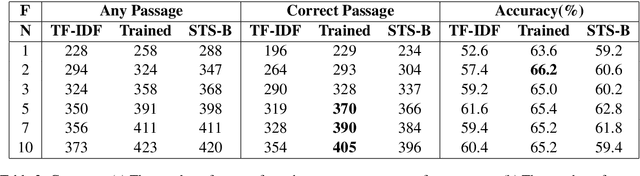
Open book question answering is a type of natural language based QA (NLQA) where questions are expected to be answered with respect to a given set of open book facts, and common knowledge about a topic. Recently a challenge involving such QA, OpenBookQA, has been proposed. Unlike most other NLQA tasks that focus on linguistic understanding, OpenBookQA requires deeper reasoning involving linguistic understanding as well as reasoning with common knowledge. In this paper we address QA with respect to the OpenBookQA dataset and combine state of the art language models with abductive information retrieval (IR), information gain based re-ranking, passage selection and weighted scoring to achieve 72.0% accuracy, an 11.6% improvement over the current state of the art.