 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image Spatial Grounding with Semantic Sampling
Mar 15, 2026Vision language models (VLMs) have shown significant promise in visual grounding for images as well as videos. In medical imaging research, VLMs represent a bridge between object detection and segmentation, and report understanding and generation. However, spatial grounding of anatomical structures in the three-dimensional space of medical images poses many unique challenges. In this study, we examine image modalities, slice directions, and coordinate systems as differentiating factors for vision components of VLMs, and the use of anatomical, directional, and relational terminology as factors for the language components. We then demonstrate that visual and textual prompting systems such as labels, bounding boxes, and mask overlays have varying effects on the spatial grounding ability of VLMs. To enable measurement and reproducibility, we introduce \textbf{MIS-Ground}, a benchmark that comprehensively tests a VLM for vulnerabilities against specific modes of \textbf{M}edical \textbf{I}mage \textbf{S}patial \textbf{Ground}ing. We release MIS-Ground to the public at \href{https://anonymous.4open.science/r/mis-ground}{\texttt{anonymous.4open.science/r/mis-ground}}. In addition, we present \textbf{MIS-SemSam}, a low-cost, inference-time, and model-agnostic optimization of VLMs that improve their spatial grounding ability with the use of \textbf{Sem}antic \textbf{Sam}pling. We find that MIS-SemSam improves the accuracy of Qwen3-VL-32B on MIS-Ground by 13.06\%.
OpenKBP-Opt: An international and reproducible evaluation of 76 knowledge-based planning pipelines
Feb 16, 2022

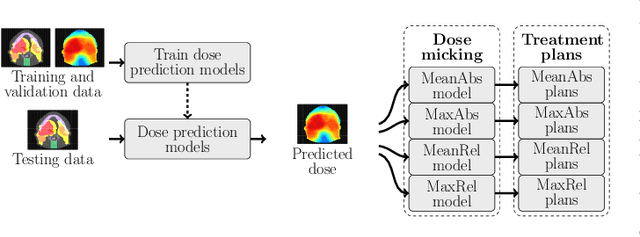
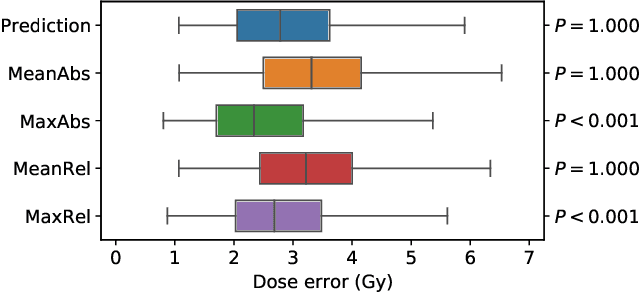
We establish an open framework for developing plan optimization models for knowledge-based planning (KBP) in radiotherapy. Our framework includes reference plans for 100 patients with head-and-neck cancer and high-quality dose predictions from 19 KBP models that were developed by different research groups during the OpenKBP Grand Challenge. The dose predictions were input to four optimization models to form 76 unique KBP pipelines that generated 7600 plans. The predictions and plans were compared to the reference plans via: dose score, which is the average mean absolute voxel-by-voxel difference in dose a model achieved; the deviation in dose-volume histogram (DVH) criterion; and the frequency of clinical planning criteria satisfaction. We also performed a theoretical investigation to justify our dose mimicking models. The range in rank order correlation of the dose score between predictions and their KBP pipelines was 0.50 to 0.62, which indicates that the quality of the predictions is generally positively correlated with the quality of the plans. Additionally, compared to the input predictions, the KBP-generated plans performed significantly better (P<0.05; one-sided Wilcoxon test) on 18 of 23 DVH criteria. Similarly, each optimization model generated plans that satisfied a higher percentage of criteria than the reference plans. Lastly, our theoretical investigation demonstrated that the dose mimicking models generated plans that are also optimal for a conventional planning model. This was the largest international effort to date for evaluating the combination of KBP prediction and optimization models. In the interest of reproducibility, our data and code is freely available at https://github.com/ababier/open-kbp-opt.
The International Workshop on Osteoarthritis Imaging Knee MRI Segmentation Challenge: A Multi-Institute Evaluation and Analysis Framework on a Standardized Dataset
May 26, 2020
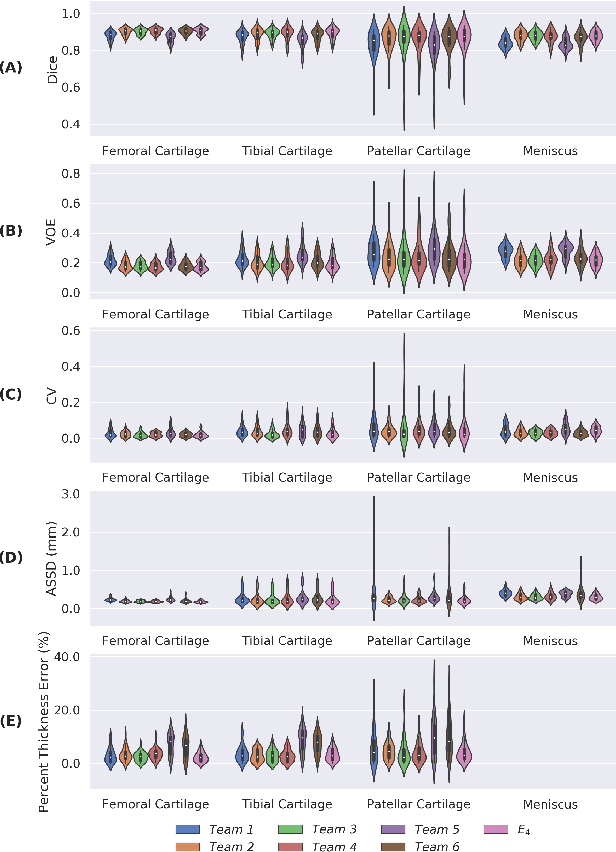
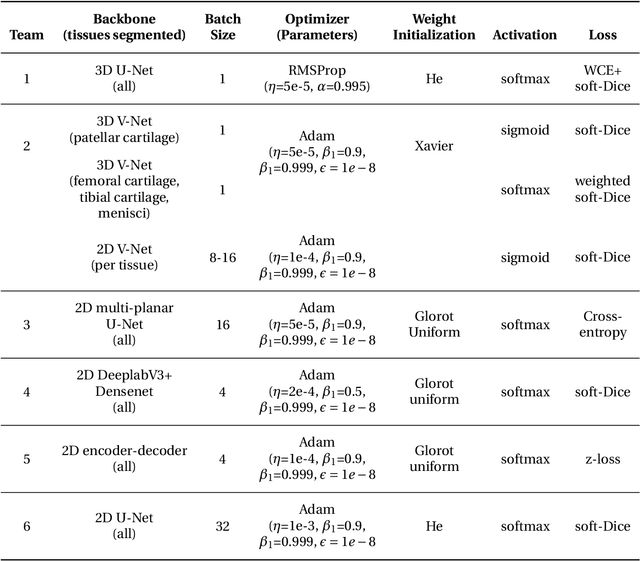
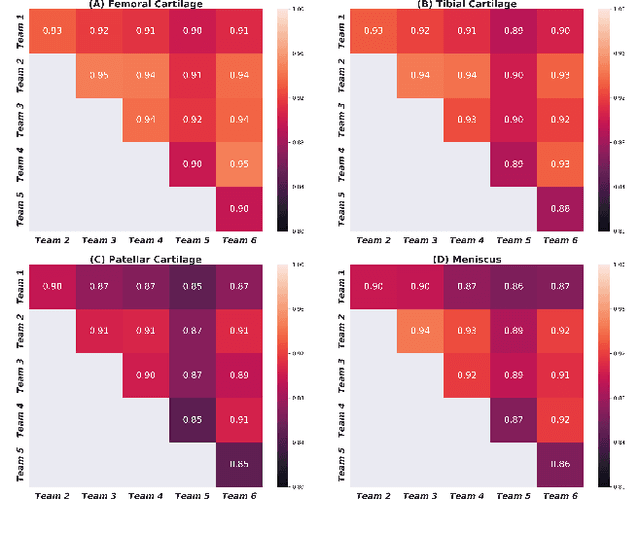
Purpose: To organize a knee MRI segmentation challenge for characterizing the semantic and clinical efficacy of automatic segmentation methods relevant for monitoring osteoarthritis progression. Methods: A dataset partition consisting of 3D knee MRI from 88 subjects at two timepoints with ground-truth articular (femoral, tibial, patellar) cartilage and meniscus segmentations was standardized. Challenge submissions and a majority-vote ensemble were evaluated using Dice score, average symmetric surface distance, volumetric overlap error, and coefficient of variation on a hold-out test set. Similarities in network segmentations were evaluated using pairwise Dice correlations. Articular cartilage thickness was computed per-scan and longitudinally. Correlation between thickness error and segmentation metrics was measured using Pearson's coefficient. Two empirical upper bounds for ensemble performance were computed using combinations of model outputs that consolidated true positives and true negatives. Results: Six teams (T1-T6) submitted entries for the challenge. No significant differences were observed across all segmentation metrics for all tissues (p=1.0) among the four top-performing networks (T2, T3, T4, T6). Dice correlations between network pairs were high (>0.85). Per-scan thickness errors were negligible among T1-T4 (p=0.99) and longitudinal changes showed minimal bias (<0.03mm). Low correlations (<0.41) were observed between segmentation metrics and thickness error. The majority-vote ensemble was comparable to top performing networks (p=1.0). Empirical upper bound performances were similar for both combinations (p=1.0). Conclusion: Diverse networks learned to segment the knee similarly where high segmentation accuracy did not correlate to cartilage thickness accuracy. Voting ensembles did not outperform individual networks but may help regularize individual models.