 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Optimisation of Collaborative Question Answering over Knowledge Graphs
Aug 14, 2019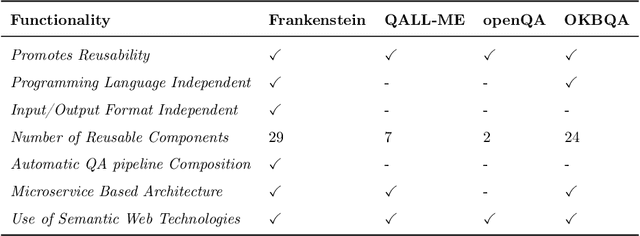
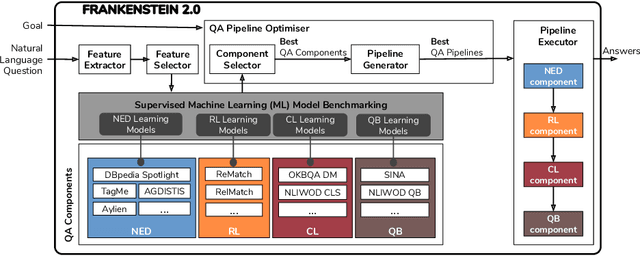
Collaborative Question Answering (CQA) frameworks for knowledge graphs aim at integrating existing question answering (QA) components for implementing sequences of QA tasks (i.e. QA pipelines). The research community has paid substantial attention to CQAs since they support reusability and scalability of the available components in addition to the flexibility of pipelines. CQA frameworks attempt to build such pipelines automatically by solving two optimisation problems: 1) local collective performance of QA components per QA task and 2) global performance of QA pipelines. In spite offering several advantages over monolithic QA systems, the effectiveness and efficiency of CQA frameworks in answering questions is limited. In this paper, we tackle the problem of local optimisation of CQA frameworks and propose a three fold approach, which applies feature selection techniques with supervised machine learning approaches in order to identify the best performing components efficiently. We have empirically evaluated our approach over existing benchmarks and compared to existing automatic CQA frameworks. The observed results provide evidence that our approach answers a higher number of questions than the state of the art while reducing: i) the number of used features by 50% and ii) the number of components used by 76%.
No One is Perfect: Analysing the Performance of Question Answering Components over the DBpedia Knowledge Graph
Sep 26, 2018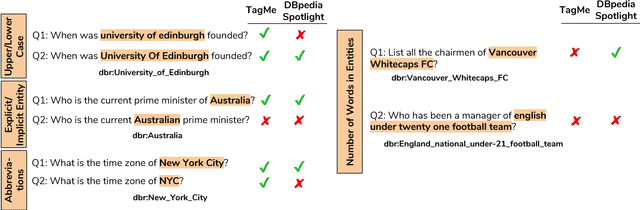

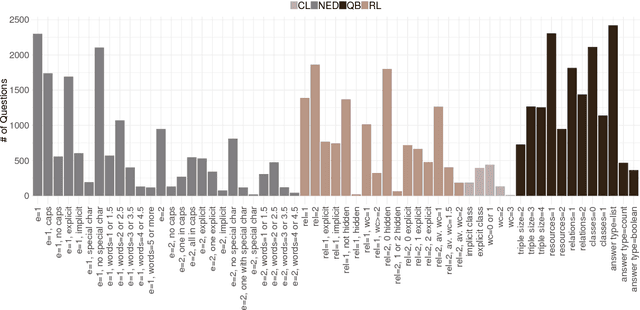
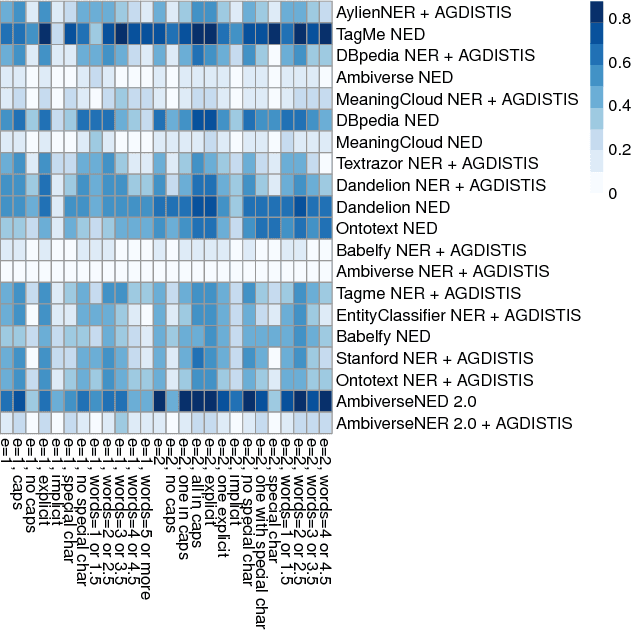
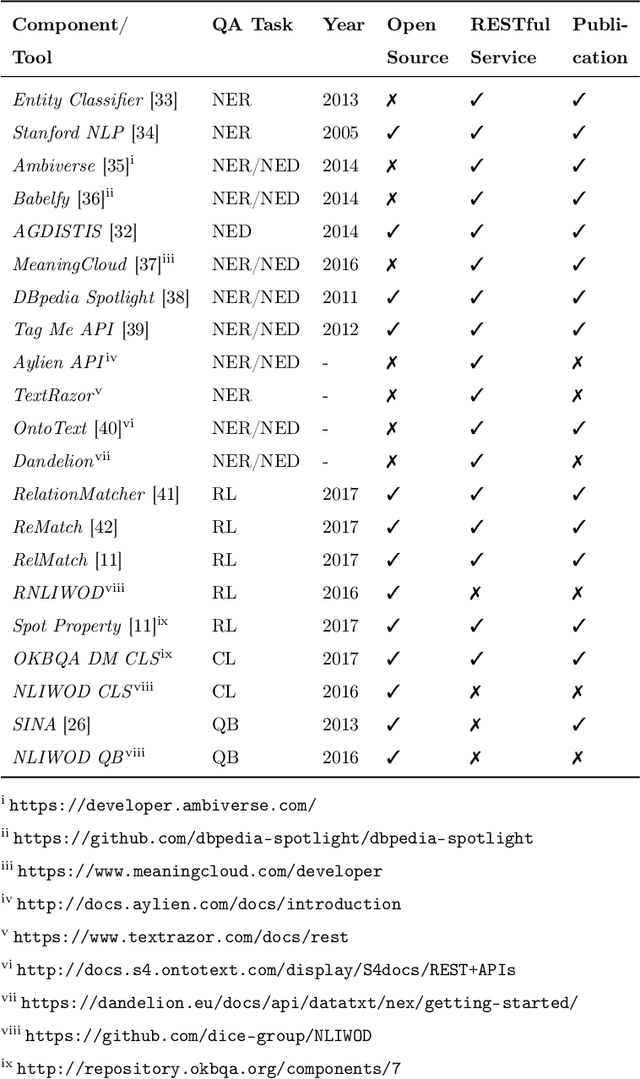
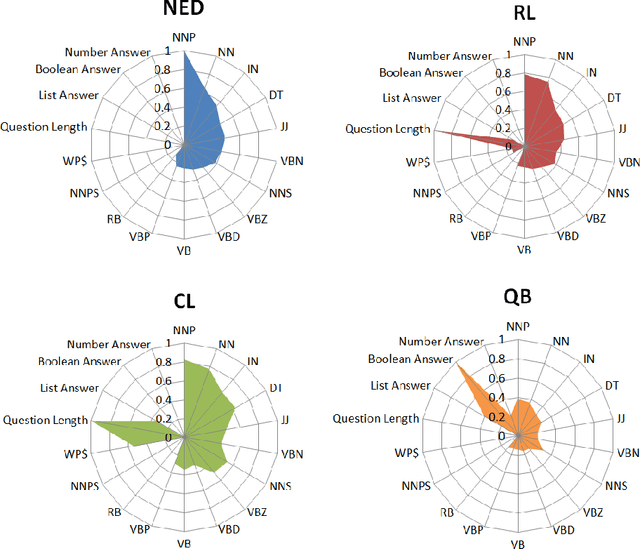
Question answering (QA) over knowledge graphs has gained significant momentum over the past five years due to the increasing availability of large knowledge graphs and the rising importance of question answering for user interaction. DBpedia has been the most prominently used knowledge graph in this setting and most approaches currently use a pipeline of processing steps connecting a sequence of components. In this article, we analyse and micro evaluate the behaviour of 29 available QA components for DBpedia knowledge graph that were released by the research community since 2010. As a result, we provide a perspective on collective failure cases, suggest characteristics of QA components that prevent them from performing better and provide future challenges and research directions for the field.
Robust Object Tracking with Crow Search Optimized Multi-cue Particle Filter
Jun 11, 2018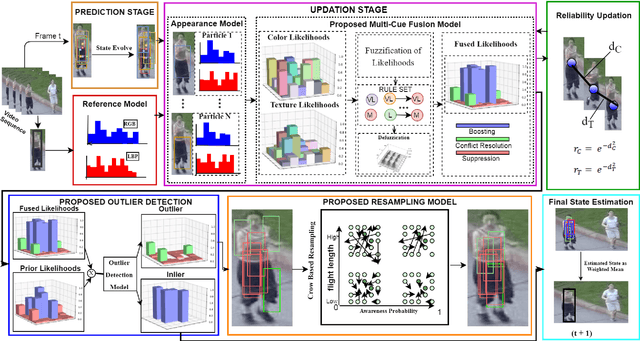
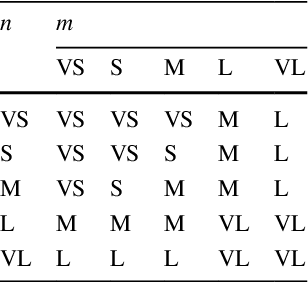
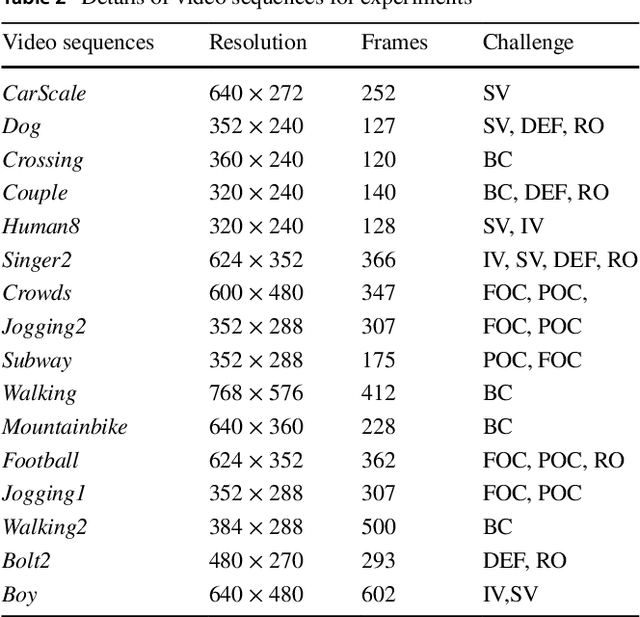

Particle Filter(PF) is used extensively for estimation of target Non-linear and Non-gaussian state. However, its performance suffers due to inherent problem of sample degeneracy and impoverishment. In order to address this, we propose a novel resampling method based upon Crow Search Optimization to overcome low performing particles detected as outlier. Proposed outlier detection mechanism with transductive reliability achieve faster convergence of proposed PF tracking framework. In addition, we present an adaptive fuzzy fusion model to integrate multi-cue extracted for each evaluated particle. Automatic boosting and suppression of particles using proposed fusion model not only enhances performance of resampling method but also achieve optimal state estimation. Performance of the proposed tracker is evaluated over 12 benchmark video sequences and compared with state-of-the-art solutions. Qualitative and quantitative results reveals that the proposed tracker not only outperforms existing solutions but also efficiently handle various tracking challenges. On average of outcome, we achieve CLE of 7.98 and F-measure of 0.734.