 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Chinese Named Entity Recognition by Search Engine Augmentation
Oct 23, 2022Compared with English, Chinese suffers from more grammatical ambiguities, like fuzzy word boundaries and polysemous words. In this case, contextual information is not sufficient to support Chinese named entity recognition (NER), especially for rare and emerging named entities. Semantic augmentation using external knowledge is a potential way to alleviate this problem, while how to obtain and leverage external knowledge for the NER task remains a challenge. In this paper, we propose a neural-based approach to perform semantic augmentation using external knowledge from search engine for Chinese NER. In particular, a multi-channel semantic fusion model is adopted to generate the augmented input representations, which aggregates external related texts retrieved from the search engine. Experiments have shown the superiority of our model across 4 NER datasets, including formal and social media language contexts, which further prove the effectiveness of our approach.
MFE-NER: Multi-feature Fusion Embedding for Chinese Named Entity Recognition
Sep 16, 2021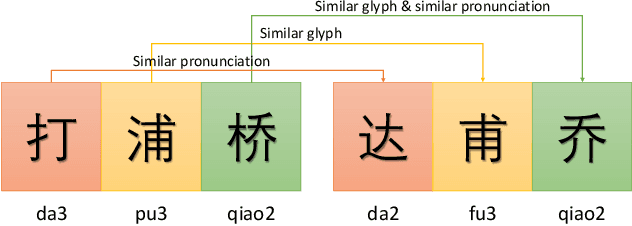
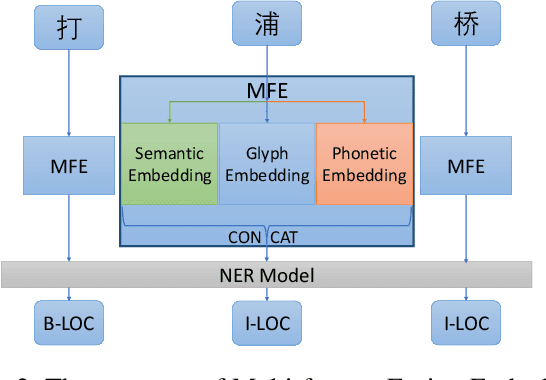
Pre-trained language models lead Named Entity Recognition (NER) into a new era, while some more knowledge is needed to improve their performance in specific problems. In Chinese NER, character substitution is a complicated linguistic phenomenon. Some Chinese characters are quite similar for sharing the same components or having similar pronunciations. People replace characters in a named entity with similar characters to generate a new collocation but referring to the same object. It becomes even more common in the Internet age and is often used to avoid Internet censorship or just for fun. Such character substitution is not friendly to those pre-trained language models because the new collocations are occasional. As a result, it always leads to unrecognizable or recognition errors in the NER task. In this paper, we propose a new method, Multi-Feature Fusion Embedding for Chinese Named Entity Recognition (MFE-NER), to strengthen the language pattern of Chinese and handle the character substitution problem in Chinese Named Entity Recognition. MFE fuses semantic, glyph, and phonetic features together. In the glyph domain, we disassemble Chinese characters into components to denote structure features so that characters with similar structures can have close embedding space representation. Meanwhile, an improved phonetic system is also proposed in our work, making it reasonable to calculate phonetic similarity among Chinese characters. Experiments demonstrate that our method improves the overall performance of Chinese NER and especially performs well in informal language environments.