 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Tailed Anomaly Detection with Learnable Class Names
Mar 29, 2024



Anomaly detection (AD) aims to identify defective images and localize their defects (if any). Ideally, AD models should be able to detect defects over many image classes; without relying on hard-coded class names that can be uninformative or inconsistent across datasets; learn without anomaly supervision; and be robust to the long-tailed distributions of real-world applications. To address these challenges, we formulate the problem of long-tailed AD by introducing several datasets with different levels of class imbalance and metrics for performance evaluation. We then propose a novel method, LTAD, to detect defects from multiple and long-tailed classes, without relying on dataset class names. LTAD combines AD by reconstruction and semantic AD modules. AD by reconstruction is implemented with a transformer-based reconstruction module. Semantic AD is implemented with a binary classifier, which relies on learned pseudo class names and a pretrained foundation model. These modules are learned over two phases. Phase 1 learns the pseudo-class names and a variational autoencoder (VAE) for feature synthesis that augments the training data to combat long-tails. Phase 2 then learns the parameters of the reconstruction and classification modules of LTAD. Extensive experiments using the proposed long-tailed datasets show that LTAD substantially outperforms the state-of-the-art methods for most forms of dataset imbalance. The long-tailed dataset split is available at https://zenodo.org/records/10854201 .
Tensor Factorization for Leveraging Cross-Modal Knowledge in Data-Constrained Infrared Object Detection
Sep 28, 2023The primary bottleneck towards obtaining good recognition performance in IR images is the lack of sufficient labeled training data, owing to the cost of acquiring such data. Realizing that object detection methods for the RGB modality are quite robust (at least for some commonplace classes, like person, car, etc.), thanks to the giant training sets that exist, in this work we seek to leverage cues from the RGB modality to scale object detectors to the IR modality, while preserving model performance in the RGB modality. At the core of our method, is a novel tensor decomposition method called TensorFact which splits the convolution kernels of a layer of a Convolutional Neural Network (CNN) into low-rank factor matrices, with fewer parameters than the original CNN. We first pretrain these factor matrices on the RGB modality, for which plenty of training data are assumed to exist and then augment only a few trainable parameters for training on the IR modality to avoid over-fitting, while encouraging them to capture complementary cues from those trained only on the RGB modality. We validate our approach empirically by first assessing how well our TensorFact decomposed network performs at the task of detecting objects in RGB images vis-a-vis the original network and then look at how well it adapts to IR images of the FLIR ADAS v1 dataset. For the latter, we train models under scenarios that pose challenges stemming from data paucity. From the experiments, we observe that: (i) TensorFact shows performance gains on RGB images; (ii) further, this pre-trained model, when fine-tuned, outperforms a standard state-of-the-art object detector on the FLIR ADAS v1 dataset by about 4% in terms of mAP 50 score.
Are Deep Neural Networks SMARTer than Second Graders?
Jan 05, 2023



Recent times have witnessed an increasing number of applications of deep neural networks towards solving tasks that require superior cognitive abilities, e.g., playing Go, generating art, question answering (such as ChatGPT), etc. Such a dramatic progress raises the question: how generalizable are neural networks in solving problems that demand broad skills? To answer this question, we propose SMART: a Simple Multimodal Algorithmic Reasoning Task and the associated SMART-101 dataset, for evaluating the abstraction, deduction, and generalization abilities of neural networks in solving visuo-linguistic puzzles designed specifically for children in the 6-8 age group. Our dataset consists of 101 unique puzzles; each puzzle comprises a picture and a question, and their solution needs a mix of several elementary skills, including arithmetic, algebra, and spatial reasoning, among others. To scale our dataset towards training deep neural networks, we programmatically generate entirely new instances for each puzzle while retaining their solution algorithm. To benchmark the performance on the SMART-101 dataset, we propose a vision and language meta-learning model using varied state-of-the-art backbone neural networks. Our experiments reveal that while powerful deep models offer reasonable performances on puzzles that they are trained on, they are not better than random accuracy when analyzed for generalization. We also evaluate the recent ChatGPT large language model on a subset of our dataset and find that while ChatGPT produces convincing reasoning abilities, the answers are often incorrect.
Cross-Domain Video Anomaly Detection without Target Domain Adaptation
Dec 14, 2022Most cross-domain unsupervised Video Anomaly Detection (VAD) works assume that at least few task-relevant target domain training data are available for adaptation from the source to the target domain. However, this requires laborious model-tuning by the end-user who may prefer to have a system that works ``out-of-the-box." To address such practical scenarios, we identify a novel target domain (inference-time) VAD task where no target domain training data are available. To this end, we propose a new `Zero-shot Cross-domain Video Anomaly Detection (zxvad)' framework that includes a future-frame prediction generative model setup. Different from prior future-frame prediction models, our model uses a novel Normalcy Classifier module to learn the features of normal event videos by learning how such features are different ``relatively" to features in pseudo-abnormal examples. A novel Untrained Convolutional Neural Network based Anomaly Synthesis module crafts these pseudo-abnormal examples by adding foreign objects in normal video frames with no extra training cost. With our novel relative normalcy feature learning strategy, zxvad generalizes and learns to distinguish between normal and abnormal frames in a new target domain without adaptation during inference. Through evaluations on common datasets, we show that zxvad outperforms the state-of-the-art (SOTA), regardless of whether task-relevant (i.e., VAD) source training data are available or not. Lastly, zxvad also beats the SOTA methods in inference-time efficiency metrics including the model size, total parameters, GPU energy consumption, and GMACs.
Cross-Modal Knowledge Transfer Without Task-Relevant Source Data
Sep 08, 2022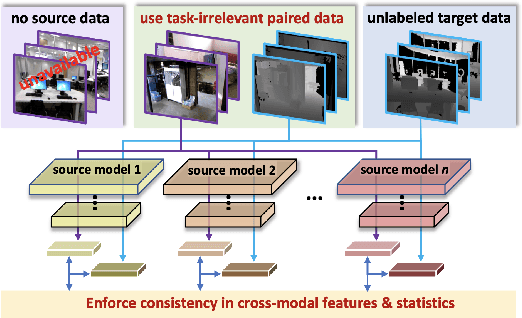

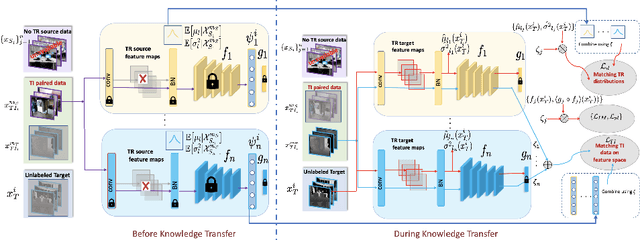

Cost-effective depth and infrared sensors as alternatives to usual RGB sensors are now a reality, and have some advantages over RGB in domains like autonomous navigation and remote sensing. As such, building computer vision and deep learning systems for depth and infrared data are crucial. However, large labeled datasets for these modalities are still lacking. In such cases, transferring knowledge from a neural network trained on a well-labeled large dataset in the source modality (RGB) to a neural network that works on a target modality (depth, infrared, etc.) is of great value. For reasons like memory and privacy, it may not be possible to access the source data, and knowledge transfer needs to work with only the source models. We describe an effective solution, SOCKET: SOurce-free Cross-modal KnowledgE Transfer for this challenging task of transferring knowledge from one source modality to a different target modality without access to task-relevant source data. The framework reduces the modality gap using paired task-irrelevant data, as well as by matching the mean and variance of the target features with the batch-norm statistics that are present in the source models. We show through extensive experiments that our method significantly outperforms existing source-free methods for classification tasks which do not account for the modality gap.
Towards To-a-T Spatio-Temporal Focus for Skeleton-Based Action Recognition
Feb 04, 2022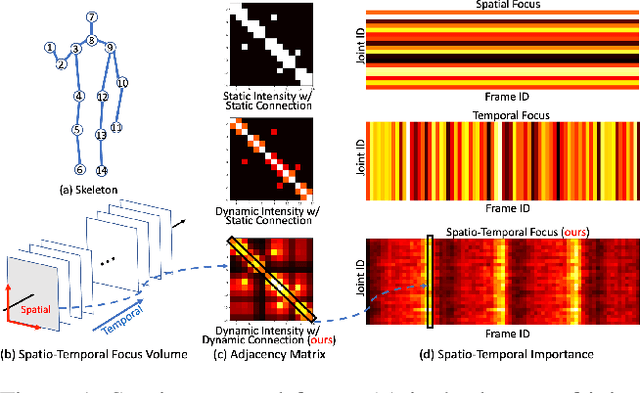

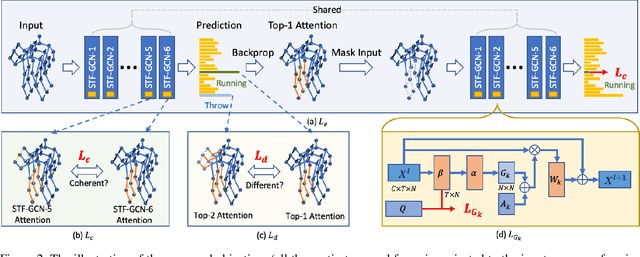
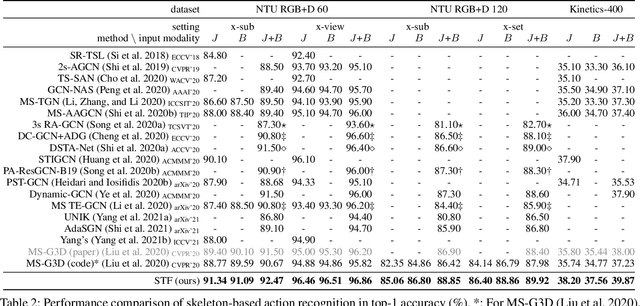
Graph Convolutional Networks (GCNs) have been widely used to model the high-order dynamic dependencies for skeleton-based action recognition. Most existing approaches do not explicitly embed the high-order spatio-temporal importance to joints' spatial connection topology and intensity, and they do not have direct objectives on their attention module to jointly learn when and where to focus on in the action sequence. To address these problems, we propose the To-a-T Spatio-Temporal Focus (STF), a skeleton-based action recognition framework that utilizes the spatio-temporal gradient to focus on relevant spatio-temporal features. We first propose the STF modules with learnable gradient-enforced and instance-dependent adjacency matrices to model the high-order spatio-temporal dynamics. Second, we propose three loss terms defined on the gradient-based spatio-temporal focus to explicitly guide the classifier when and where to look at, distinguish confusing classes, and optimize the stacked STF modules. STF outperforms the state-of-the-art methods on the NTU RGB+D 60, NTU RGB+D 120, and Kinetics Skeleton 400 datasets in all 15 settings over different views, subjects, setups, and input modalities, and STF also shows better accuracy on scarce data and dataset shifting settings.
Iterative Self Knowledge Distillation -- From Pothole Classification to Fine-Grained and COVID Recognition
Feb 04, 2022
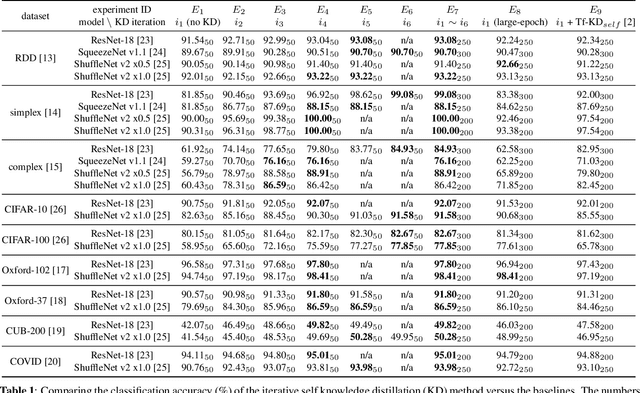
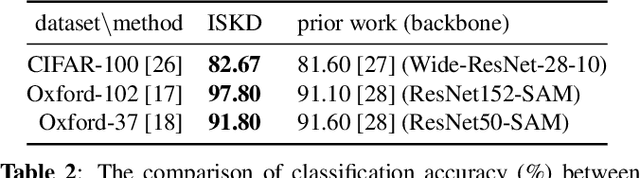
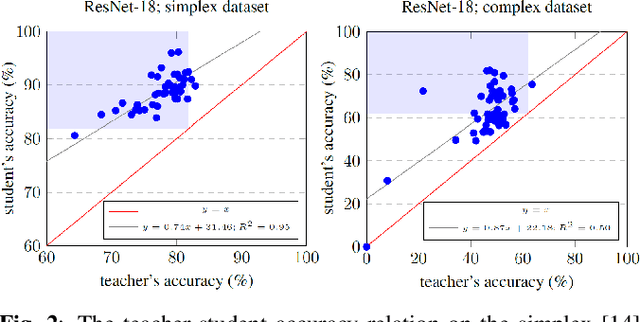
Pothole classification has become an important task for road inspection vehicles to save drivers from potential car accidents and repair bills. Given the limited computational power and fixed number of training epochs, we propose iterative self knowledge distillation (ISKD) to train lightweight pothole classifiers. Designed to improve both the teacher and student models over time in knowledge distillation, ISKD outperforms the state-of-the-art self knowledge distillation method on three pothole classification datasets across four lightweight network architectures, which supports that self knowledge distillation should be done iteratively instead of just once. The accuracy relation between the teacher and student models shows that the student model can still benefit from a moderately trained teacher model. Implying that better teacher models generally produce better student models, our results justify the design of ISKD. In addition to pothole classification, we also demonstrate the efficacy of ISKD on six additional datasets associated with generic classification, fine-grained classification, and medical imaging application, which supports that ISKD can serve as a general-purpose performance booster without the need of a given teacher model and extra trainable parameters.
ViewSynth: Learning Local Features from Depth using View Synthesis
Nov 22, 2019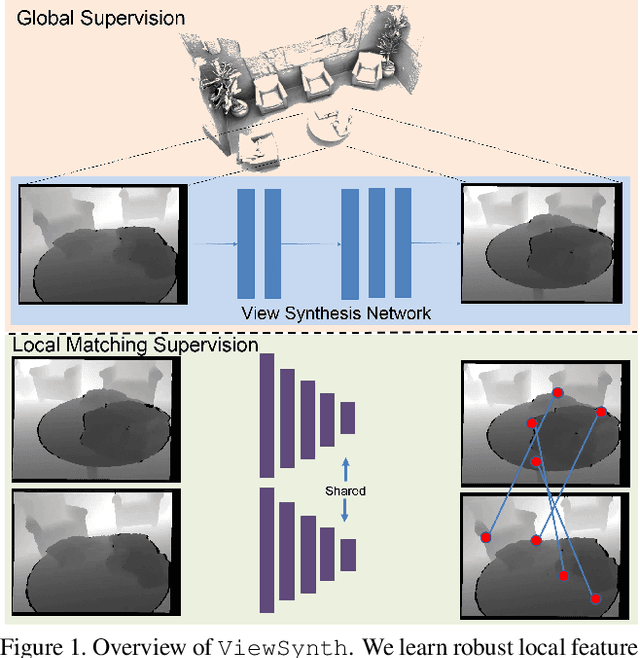

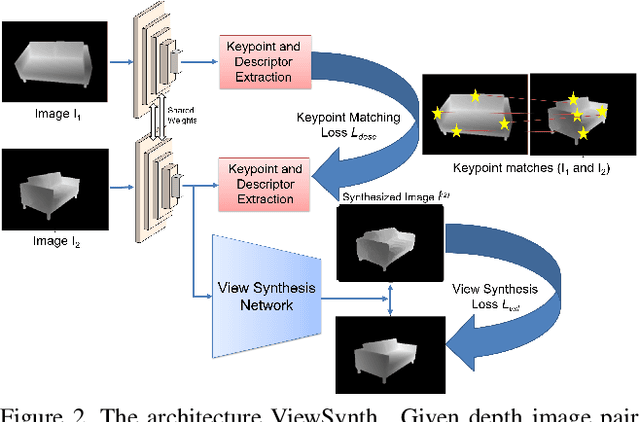
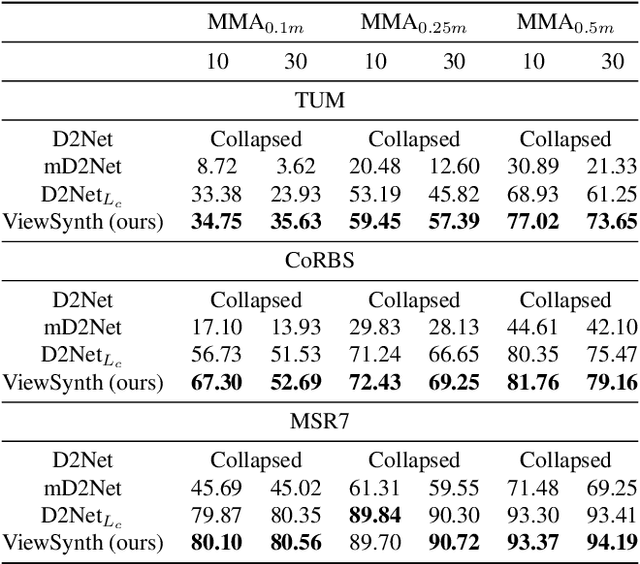
We address the problem of jointly detecting keypoints and learning descriptors in depth data with challenging viewpoint changes. Despite great improvements in recent RGB based local feature learning methods, we show that these methods cannot be directly transferred to the depth image modality. These methods also do not utilize the 2.5D information present in depth images. We propose a framework ViewSynth, designed to jointly learn 3D structure aware depth image representation, and local features from that representation. ViewSynth consists of `View Synthesis Network' (VSN), trained to synthesize depth image views given a depth image representation and query viewpoints. ViewSynth framework includes joint learning of keypoints and feature descriptor, paired with our view synthesis loss, which guides the model to propose keypoints robust to viewpoint changes. We demonstrate the effectiveness of our formulation on several depth image datasets, where learned local features using our proposed ViewSynth framework outperforms the state-of-the-art methods in keypoint matching and camera localization tasks.
Attention Guided Anomaly Detection and Localization in Images
Nov 19, 2019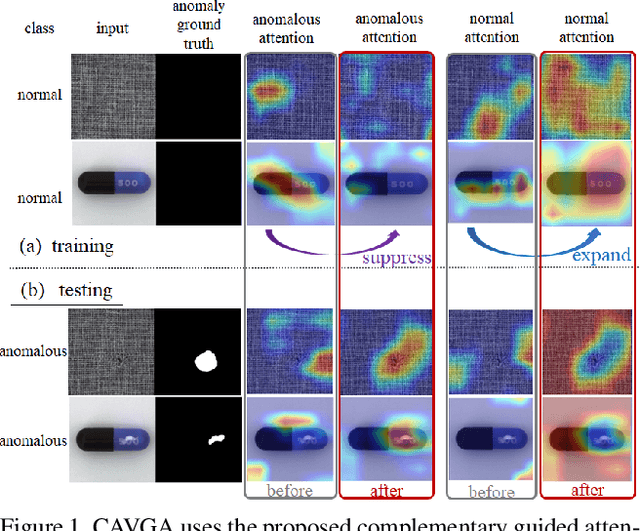

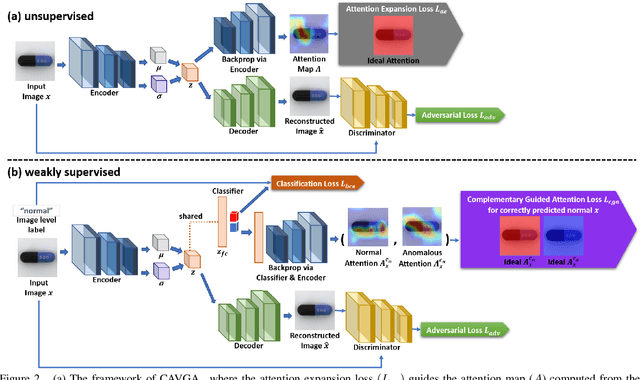
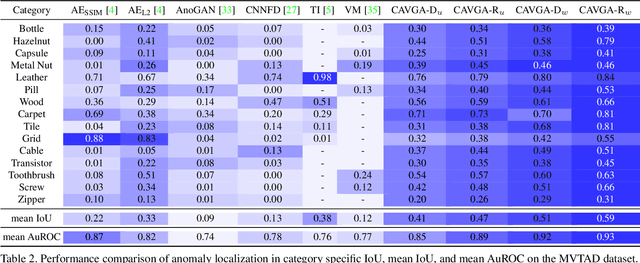
Anomaly detection and localization is a popular computer vision problem involving detecting anomalous images and localizing anomalies within them. However, this task is challenging due to the small sample size and pixel coverage of the anomaly in real-world scenarios. Prior works need to use anomalous training images to compute a threshold to detect and localize anomalies. To remove this need, we propose Convolutional Adversarial Variational autoencoder with Guided Attention (CAVGA), which localizes the anomaly with a convolutional latent variable to preserve the spatial information. In the unsupervised setting, we propose an attention expansion loss, where we encourage CAVGA to focus on all normal regions in the image without using any anomalous training image. Furthermore, using only 2% anomalous images in the weakly supervised setting we propose a complementary guided attention loss, where we encourage the normal attention to focus on all normal regions while minimizing the regions covered by the anomalous attention in the normal image. CAVGA outperforms the state-of-the-art (SOTA) anomaly detection methods on the MNIST, CIFAR-10, Fashion-MNIST, MVTec Anomaly Detection (MVTAD), and modified ShanghaiTech Campus (mSTC) datasets. CAVGA also outperforms the SOTA anomaly localization methods on the MVTAD and mSTC datasets.
Learning without Memorizing
Nov 20, 2018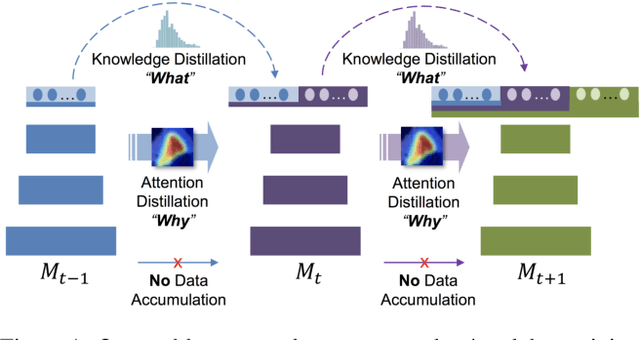


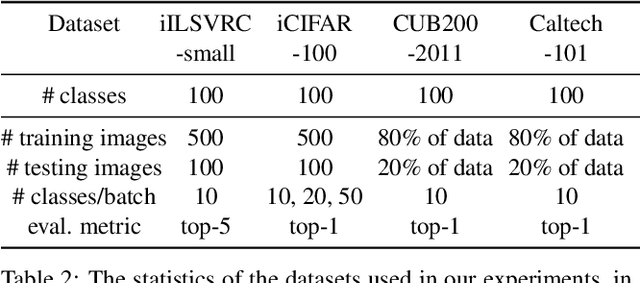
Incremental learning (IL) is an important task aimed to increase the capability of a trained model, in terms of the number of classes recognizable by the model. The key problem in this task is the requirement of storing data (e.g. images) associated with existing classes, while training the classifier to learn new classes. However, this is impractical as it increases the memory requirement at every incremental step, which makes it impossible to implement IL algorithms on the edge devices with limited memory. Hence, we propose a novel approach, called "Learning without Memorizing (LwM)", to preserve the information with respect to existing (base) classes, without storing any of their data, while making the classifier progressively learn the new classes. In LwM, we present an information preserving penalty: Attention Distillation Loss, and demonstrate that penalizing the changes in classifiers' attention maps helps to retain information of the base classes, as new classes are added. We show that adding Attention Distillation Loss to the distillation loss which is an existing information preserving loss consistently outperforms the state-of-the-art performance in the iILSVRC-small and iCIFAR-100 datasets in terms of the overall accuracy of base and incrementally learned classes.