 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting Collision Sound Sources in Egocentric Videos
Nov 17, 2025Humans excel at multisensory perception and can often recognise object properties from the sound of their interactions. Inspired by this, we propose the novel task of Collision Sound Source Segmentation (CS3), where we aim to segment the objects responsible for a collision sound in visual input (i.e. video frames from the collision clip), conditioned on the audio. This task presents unique challenges. Unlike isolated sound events, a collision sound arises from interactions between two objects, and the acoustic signature of the collision depends on both. We focus on egocentric video, where sounds are often clear, but the visual scene is cluttered, objects are small, and interactions are brief. To address these challenges, we propose a weakly-supervised method for audio-conditioned segmentation, utilising foundation models (CLIP and SAM2). We also incorporate egocentric cues, i.e. objects in hands, to find acting objects that can potentially be collision sound sources. Our approach outperforms competitive baselines by $3\times$ and $4.7\times$ in mIoU on two benchmarks we introduce for the CS3 task: EPIC-CS3 and Ego4D-CS3.
Beyond Mono to Binaural: Generating Binaural Audio from Mono Audio with Depth and Cross Modal Attention
Nov 15, 2021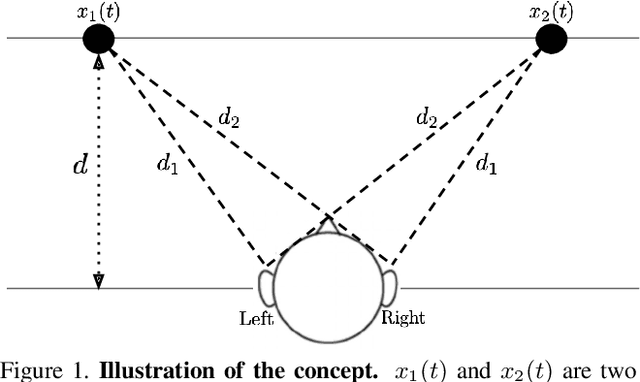
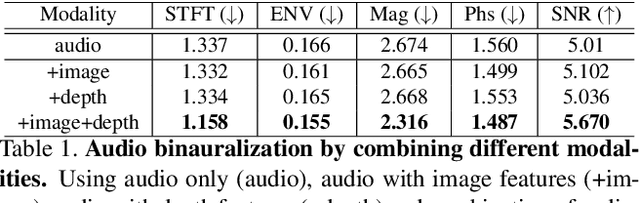
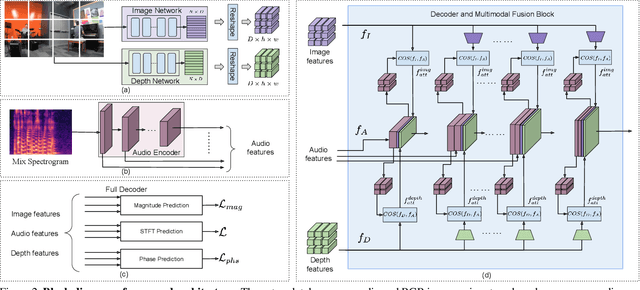
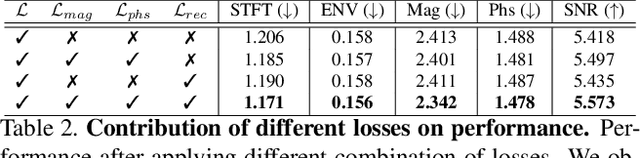
Binaural audio gives the listener an immersive experience and can enhance augmented and virtual reality. However, recording binaural audio requires specialized setup with a dummy human head having microphones in left and right ears. Such a recording setup is difficult to build and setup, therefore mono audio has become the preferred choice in common devices. To obtain the same impact as binaural audio, recent efforts have been directed towards lifting mono audio to binaural audio conditioned on the visual input from the scene. Such approaches have not used an important cue for the task: the distance of different sound producing objects from the microphones. In this work, we argue that depth map of the scene can act as a proxy for inducing distance information of different objects in the scene, for the task of audio binauralization. We propose a novel encoder-decoder architecture with a hierarchical attention mechanism to encode image, depth and audio feature jointly. We design the network on top of state-of-the-art transformer networks for image and depth representation. We show empirically that the proposed method outperforms state-of-the-art methods comfortably for two challenging public datasets FAIR-Play and MUSIC-Stereo. We also demonstrate with qualitative results that the method is able to focus on the right information required for the task. The project details are available at \url{https://krantiparida.github.io/projects/bmonobinaural.html}
Depth Infused Binaural Audio Generation using Hierarchical Cross-Modal Attention
Aug 10, 2021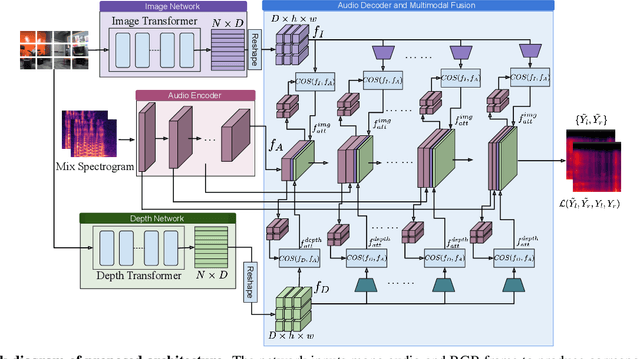
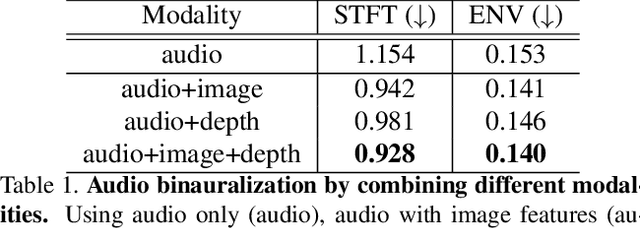
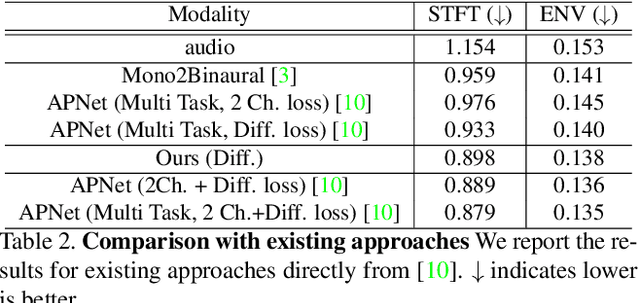

Binaural audio gives the listener the feeling of being in the recording place and enhances the immersive experience if coupled with AR/VR. But the problem with binaural audio recording is that it requires a specialized setup which is not possible to fabricate within handheld devices as compared to traditional mono audio that can be recorded with a single microphone. In order to overcome this drawback, prior works have tried to uplift the mono recorded audio to binaural audio as a post processing step conditioning on the visual input. But all the prior approaches missed other most important information required for the task, i.e. distance of different sound producing objects from the recording setup. In this work, we argue that the depth map of the scene can act as a proxy for encoding distance information of objects in the scene and show that adding depth features along with image features improves the performance both qualitatively and quantitatively. We propose a novel encoder-decoder architecture, where we use a hierarchical attention mechanism to encode the image and depth feature extracted from individual transformer backbone, with audio features at each layer of the decoder.
Beyond Image to Depth: Improving Depth Prediction using Echoes
Apr 03, 2021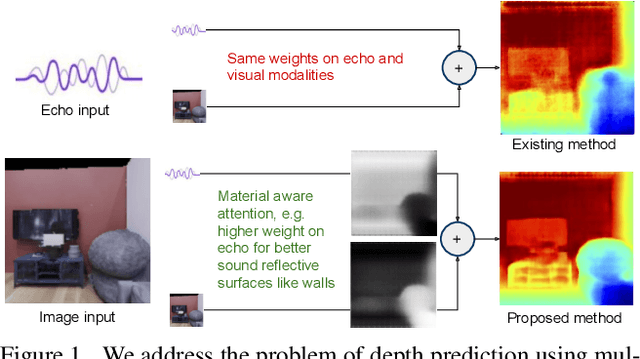
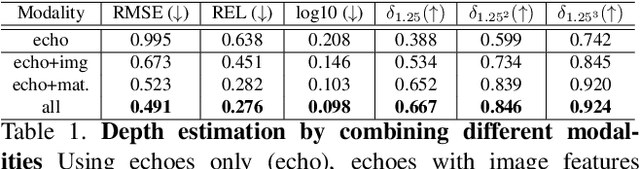
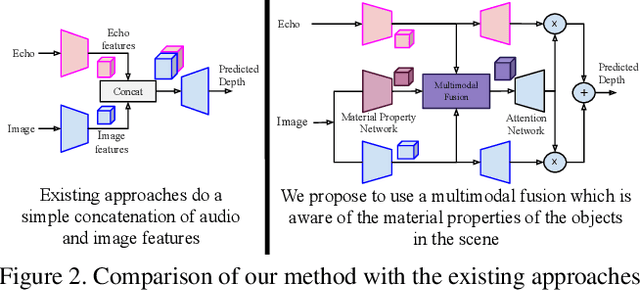
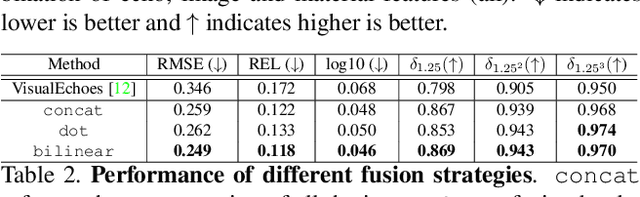
We address the problem of estimating depth with multi modal audio visual data. Inspired by the ability of animals, such as bats and dolphins, to infer distance of objects with echolocation, some recent methods have utilized echoes for depth estimation. We propose an end-to-end deep learning based pipeline utilizing RGB images, binaural echoes and estimated material properties of various objects within a scene. We argue that the relation between image, echoes and depth, for different scene elements, is greatly influenced by the properties of those elements, and a method designed to leverage this information can lead to significantly improved depth estimation from audio visual inputs. We propose a novel multi modal fusion technique, which incorporates the material properties explicitly while combining audio (echoes) and visual modalities to predict the scene depth. We show empirically, with experiments on Replica dataset, that the proposed method obtains 28% improvement in RMSE compared to the state-of-the-art audio-visual depth prediction method. To demonstrate the effectiveness of our method on larger dataset, we report competitive performance on Matterport3D, proposing to use it as a multimodal depth prediction benchmark with echoes for the first time. We also analyse the proposed method with exhaustive ablation experiments and qualitative results. The code and models are available at https://krantiparida.github.io/projects/bimgdepth.html
Discriminative Semantic Transitive Consistency for Cross-Modal Learning
Mar 25, 2021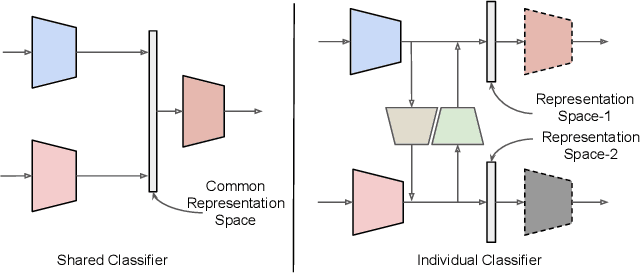
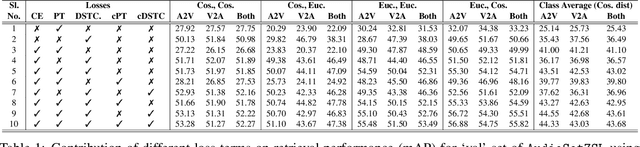
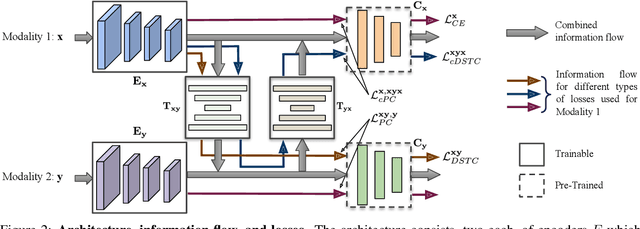
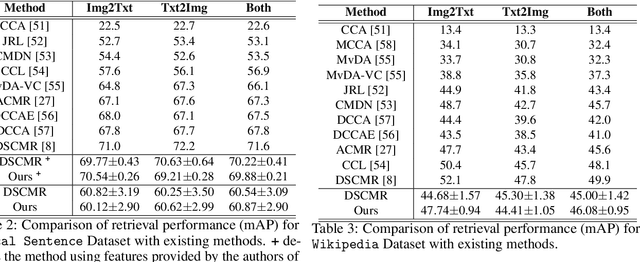
Cross-modal retrieval is generally performed by projecting and aligning the data from two different modalities onto a shared representation space. This shared space often also acts as a bridge for translating the modalities. We address the problem of learning such representation space by proposing and exploiting the property of Discriminative Semantic Transitive Consistency -- ensuring that the data points are correctly classified even after being transferred to the other modality. Along with semantic transitive consistency, we also enforce the traditional distance minimizing constraint which makes the projections of the corresponding data points from both the modalities to come closer in the representation space. We analyze and compare the contribution of both the loss terms and their interaction, for the task. In addition, we incorporate semantic cycle-consistency for each of the modality. We empirically demonstrate better performance owing to the different components with clear ablation studies. We also provide qualitative results to support the proposals.
AVGZSLNet: Audio-Visual Generalized Zero-Shot Learning by Reconstructing Label Features from Multi-Modal Embeddings
May 27, 2020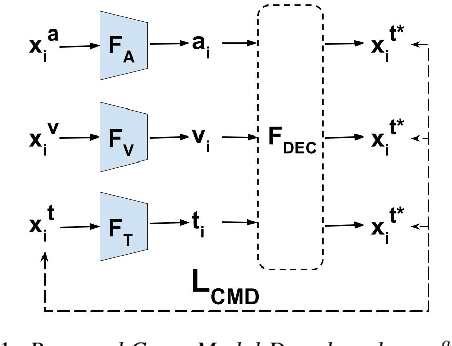
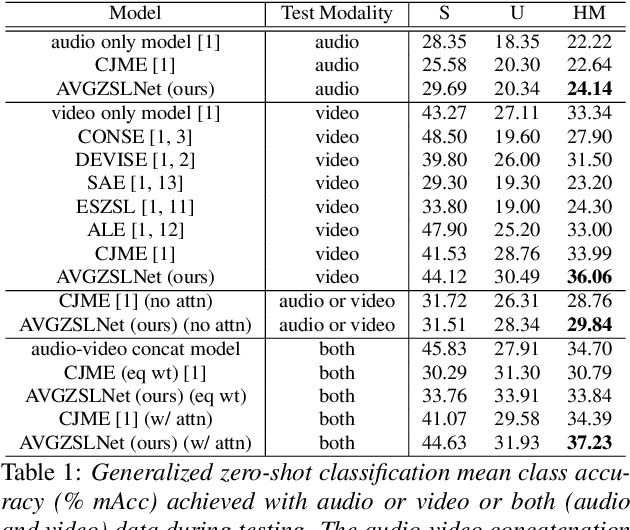
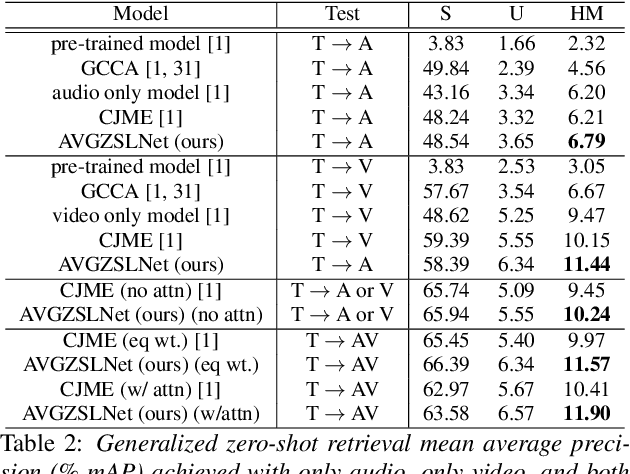

In this paper, we solve for the problem of generalized zero-shot learning in a multi-modal setting, where we have novel classes of audio/video during testing that were not seen during training. We demonstrate that projecting the audio and video embeddings to the class label text feature space allows us to use the semantic relatedness of text embeddings as a means for zero-shot learning. Importantly, our multi-modal zero-shot learning approach works even if a modality is missing at test time. Our approach makes use of a cross-modal decoder which enforces the constraint that the class label text features can be reconstructed from the audio and video embeddings of data points in order to perform better on the multi-modal zero-shot learning task. We further minimize the gap between audio and video embedding distributions using KL-Divergence loss. We test our approach on the zero-shot classification and retrieval tasks, and it performs better than other models in the presence of a single modality as well as in the presence of multiple modalities.
Coordinated Joint Multimodal Embeddings for Generalized Audio-Visual Zeroshot Classification and Retrieval of Videos
Oct 19, 2019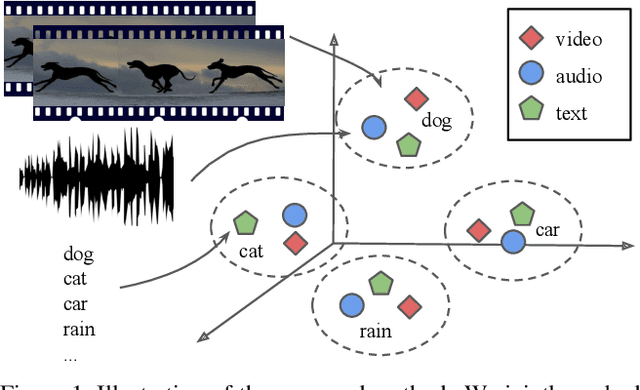
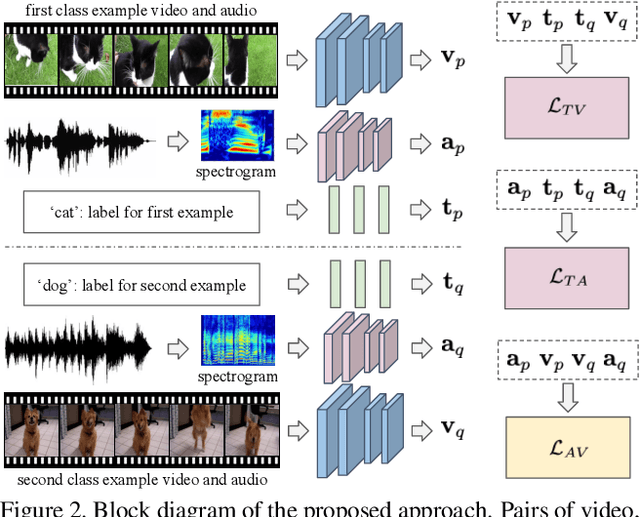
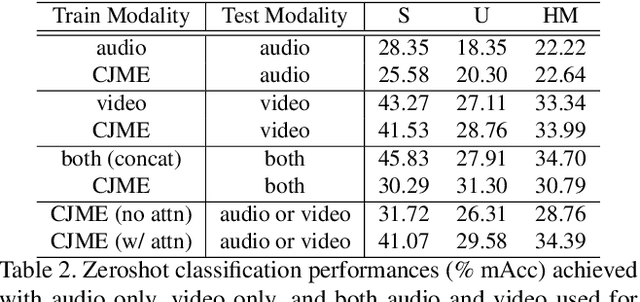
We present an audio-visual multimodal approach for the task of zeroshot learning (ZSL) for classification and retrieval of videos. ZSL has been studied extensively in the recent past but has primarily been limited to visual modality and to images. We demonstrate that both audio and visual modalities are important for ZSL for videos. Since a dataset to study the task is currently not available, we also construct an appropriate multimodal dataset with 33 classes containing 156,416 videos, from an existing large scale audio event dataset. We empirically show that the performance improves by adding audio modality for both tasks of zeroshot classification and retrieval, when using multimodal extensions of embedding learning methods. We also propose a novel method to predict the `dominant' modality using a jointly learned modality attention network. We learn the attention in a semi-supervised setting and thus do not require any additional explicit labelling for the modalities. We provide qualitative validation of the modality specific attention, which also successfully generalizes to unseen test classes.