 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental evidence of progressive ChatGPT models self-convergence
Mar 16, 2026Large Language Models (LLMs) that undergo recursive training on synthetically generated data are susceptible to model collapse, a phenomenon marked by the generation of meaningless output. Existing research has examined this issue from either theoretical or empirical perspectives, often focusing on a single model trained recursively on its own outputs. While prior studies have cautioned against the potential degradation of LLM output quality under such conditions, no longitudinal investigation has yet been conducted to assess this effect over time. In this study, we employ a text similarity metric to evaluate different ChatGPT models' capacity to generate diverse textual outputs. Our findings indicate a measurable decline of recent ChatGPT releases' ability to produce varied text, even when explicitly prompted to do so, by setting the temperature parameter to one. The observed reduction in output diversity may be attributed to the influence of the amounts of synthetic data incorporated within their training datasets as the result of internet infiltration by LLM generated data. The phenomenon is defined as model self-convergence because of the gradual increase of similarities of produced texts among different ChatGPT versions.
Data Curves Clustering Using Common Patterns Detection
Jan 05, 2020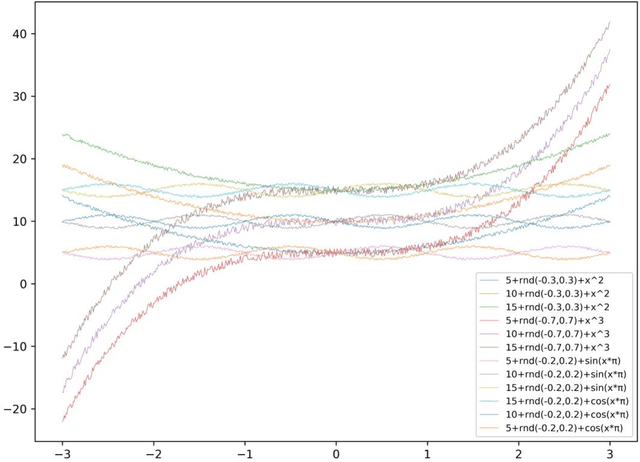



For the past decades we have experienced an enormous expansion of the accumulated data that humanity produces. Daily a numerous number of smart devices, usually interconnected over internet, produce vast, real-values datasets. Time series representing datasets from completely irrelevant domains such as finance, weather, medical applications, traffic control etc. become more and more crucial in human day life. Analyzing and clustering these time series, or in general any kind of curves, could be critical for several human activities. In the current paper, the new Curves Clustering Using Common Patterns (3CP) methodology is introduced, which applies a repeated pattern detection algorithm in order to cluster sequences according to their shape and the similarities of common patterns between time series, data curves and eventually any kind of discrete sequences. For this purpose, the Longest Expected Repeated Pattern Reduced Suffix Array (LERP-RSA) data structure has been used in combination with the All Repeated Patterns Detection (ARPaD) algorithm in order to perform highly accurate and efficient detection of similarities among data curves that can be used for clustering purposes and which also provides additional flexibility and features.