 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Phase Reconstruction via DNN-based Phase Differences Estimation
Nov 12, 2022



This paper presents a two-stage online phase reconstruction framework using causal deep neural networks (DNNs). Phase reconstruction is a task of recovering phase of the short-time Fourier transform (STFT) coefficients only from the corresponding magnitude. However, phase is sensitive to waveform shifts and not easy to estimate from the magnitude even with a DNN. To overcome this problem, we propose to use DNNs for estimating differences of phase between adjacent time-frequency bins. We show that convolutional neural networks are suitable for phase difference estimation, according to the theoretical relation between partial derivatives of STFT phase and magnitude. The estimated phase differences are used for reconstructing phase by solving a weighted least squares problem in a frame-by-frame manner. In contrast to existing DNN-based phase reconstruction methods, the proposed framework is causal and does not require any iterative procedure. The experiments showed that the proposed method outperforms existing online methods and a DNN-based method for phase reconstruction.
WaveFit: An Iterative and Non-autoregressive Neural Vocoder based on Fixed-Point Iteration
Oct 03, 2022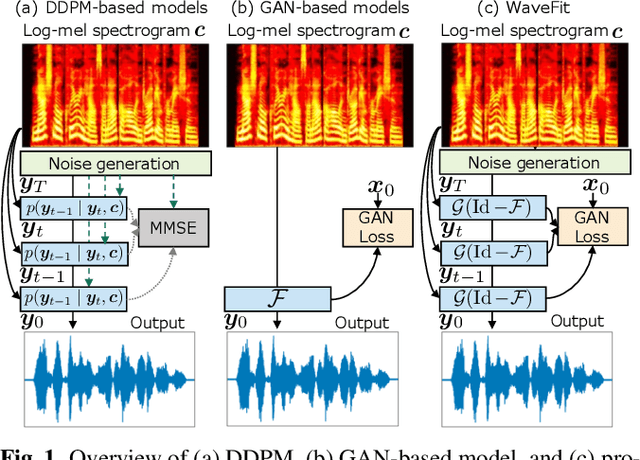
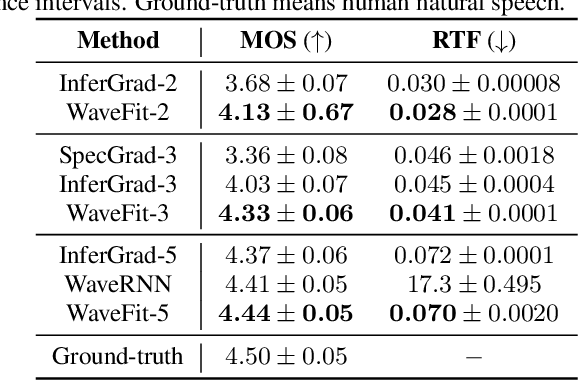
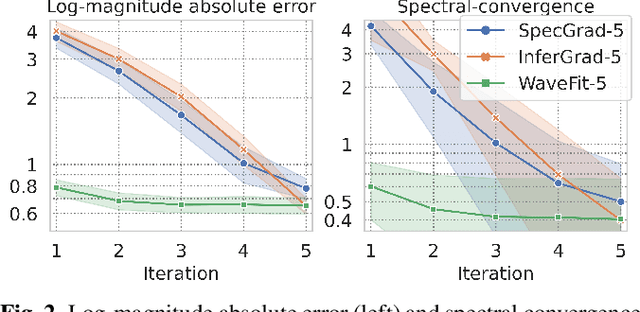
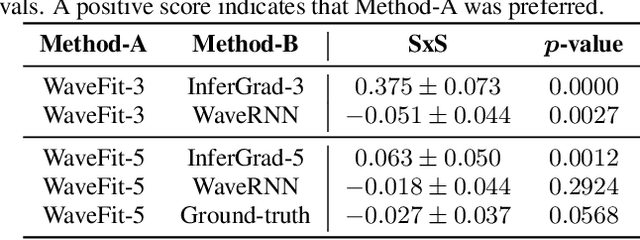
Denoising diffusion probabilistic models (DDPMs) and generative adversarial networks (GANs) are popular generative models for neural vocoders. The DDPMs and GANs can be characterized by the iterative denoising framework and adversarial training, respectively. This study proposes a fast and high-quality neural vocoder called \textit{WaveFit}, which integrates the essence of GANs into a DDPM-like iterative framework based on fixed-point iteration. WaveFit iteratively denoises an input signal, and trains a deep neural network (DNN) for minimizing an adversarial loss calculated from intermediate outputs at all iterations. Subjective (side-by-side) listening tests showed no statistically significant differences in naturalness between human natural speech and those synthesized by WaveFit with five iterations. Furthermore, the inference speed of WaveFit was more than 240 times faster than WaveRNN. Audio demos are available at \url{google.github.io/df-conformer/wavefit/}.
Measuring pitch extractors' response to frequency-modulated multi-component signals
Apr 02, 2022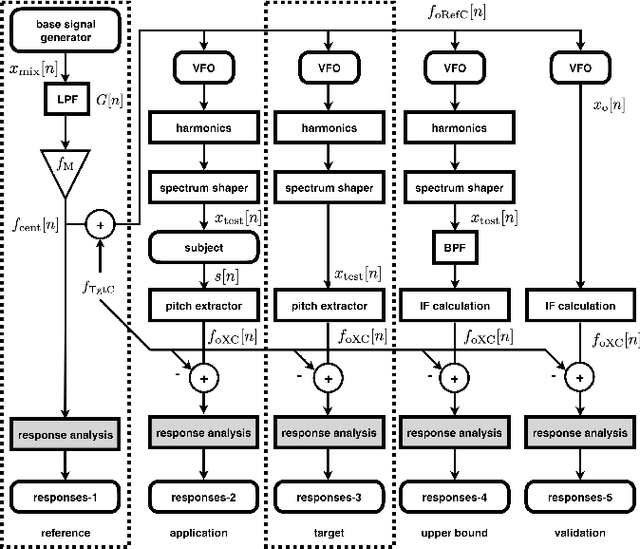
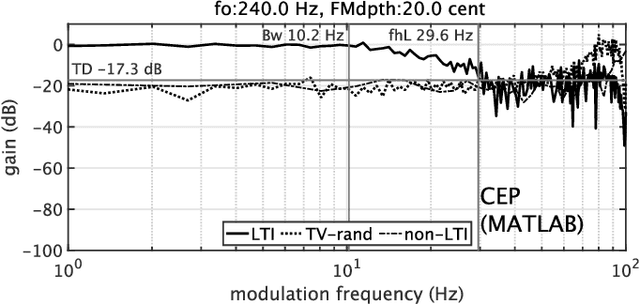
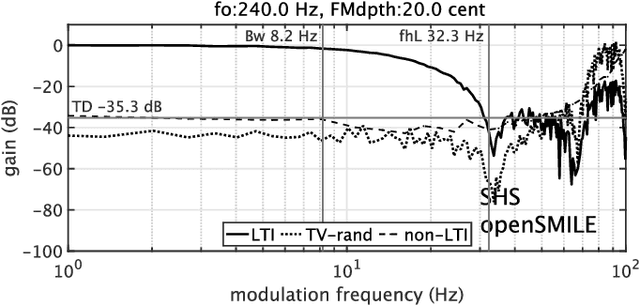
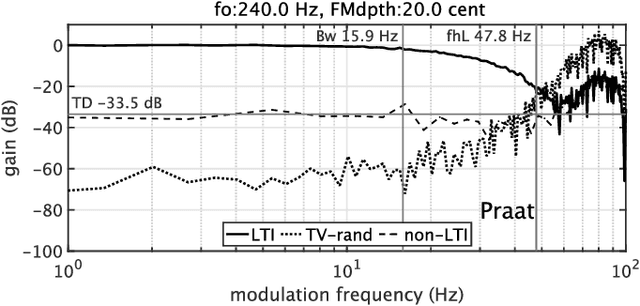
This article focuses on the research tool for investigating the fundamental frequencies of voiced sounds. We introduce an objective and informative measurement method of pitch extractors' response to frequency-modulated tones. The method uses a new test signal for acoustic system analysis. The test signal enables simultaneous measurement of the extractors' responses. They are the modulation frequency response and the total distortion, including intermodulation distortions. We applied this method to various pitch extractors and placed them on several performance maps. We used the proposed method to fine-tune one of the extractors to make it the best fit tool for scientific research of voice fundamental frequencies.
An objective test tool for pitch extractors' response attributes
Apr 02, 2022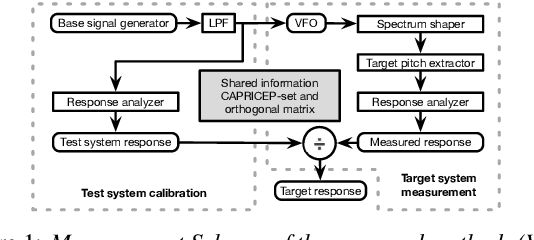
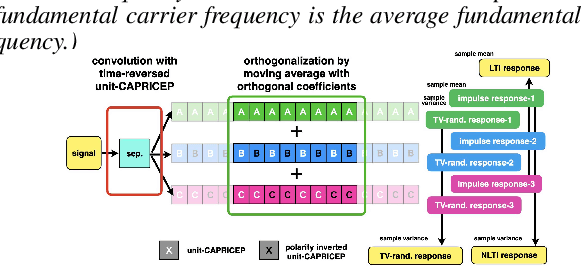
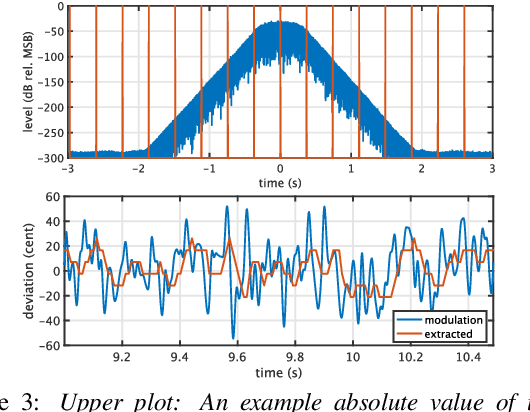
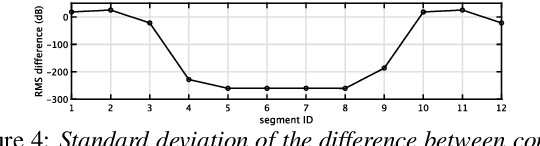
We propose an objective measurement method for pitch extractors' responses to frequency-modulated signals. It enables us to evaluate different pitch extractors with unified criteria. The method uses extended time-stretched pulses combined by binary orthogonal sequences. It provides simultaneous measurement results consisting of the linear and the non-linear time-invariant responses and random and time-varying responses. We tested representative pitch extractors using fundamental frequencies spanning 80~Hz to 400~Hz with 1/48 octave steps and produced more than 1000 modulation frequency response plots. We found that making scientific visualization by animating these plots enables us to understand different pitch extractors' behavior at once. Such efficient and effortless inspection is impossible by inspecting all individual plots. The proposed measurement method with visualization leads to further improvement of the performance of one of the extractors mentioned above. In other words, our procedure turns the specific pitch extractor into the best reliable measuring equipment that is crucial for scientific research. We open-sourced MATLAB codes of the proposed objective measurement method and visualization procedure.
SpecGrad: Diffusion Probabilistic Model based Neural Vocoder with Adaptive Noise Spectral Shaping
Mar 31, 2022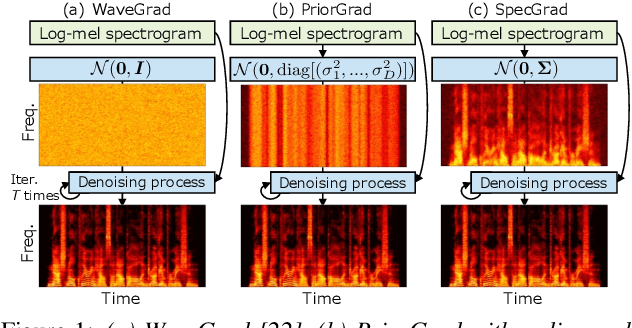
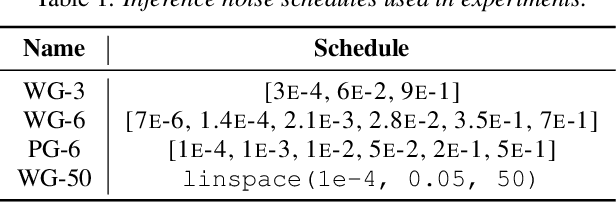
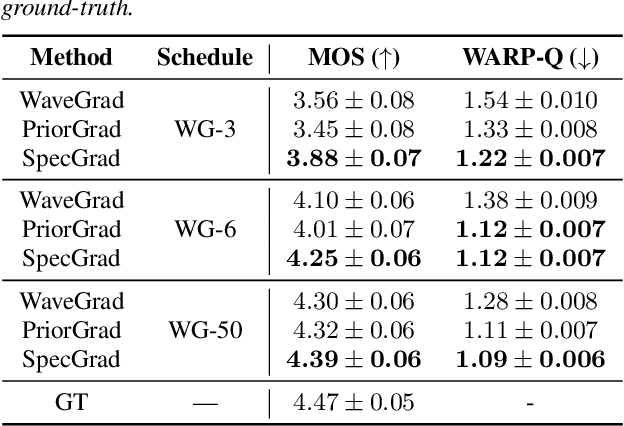
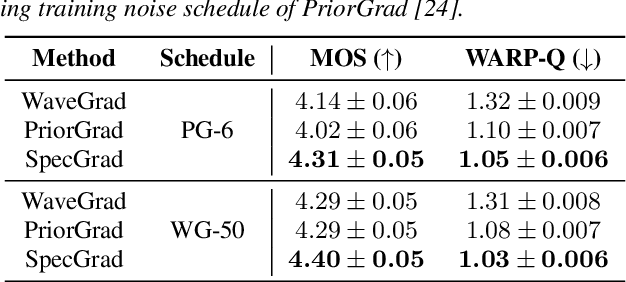
Neural vocoder using denoising diffusion probabilistic model (DDPM) has been improved by adaptation of the diffusion noise distribution to given acoustic features. In this study, we propose SpecGrad that adapts the diffusion noise so that its time-varying spectral envelope becomes close to the conditioning log-mel spectrogram. This adaptation by time-varying filtering improves the sound quality especially in the high-frequency bands. It is processed in the time-frequency domain to keep the computational cost almost the same as the conventional DDPM-based neural vocoders. Experimental results showed that SpecGrad generates higher-fidelity speech waveform than conventional DDPM-based neural vocoders in both analysis-synthesis and speech enhancement scenarios. Audio demos are available at wavegrad.github.io/specgrad/.
Wearable SELD dataset: Dataset for sound event localization and detection using wearable devices around head
Feb 17, 2022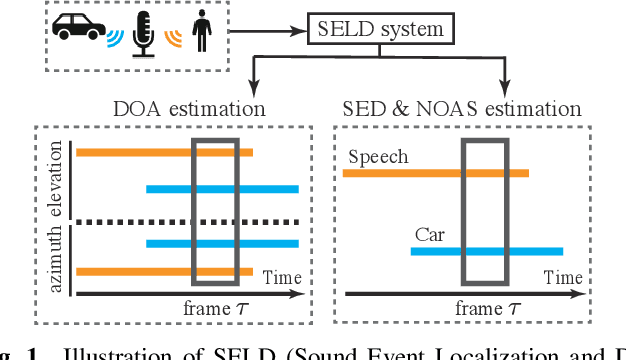
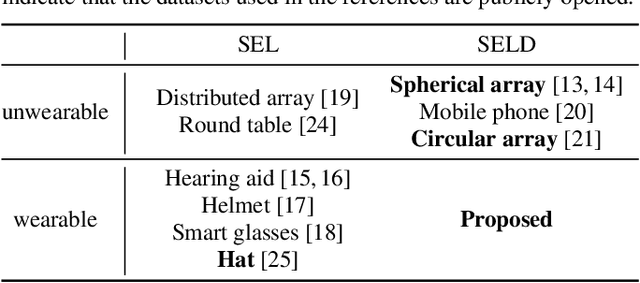
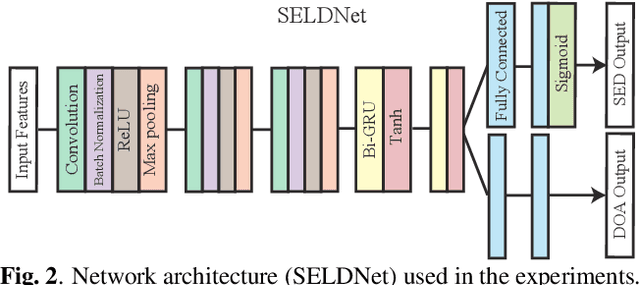
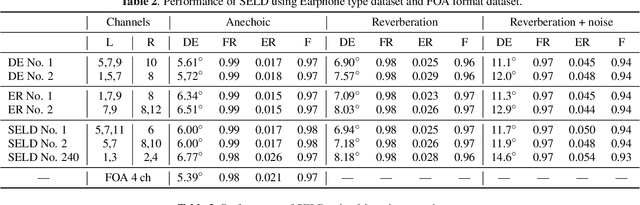
Sound event localization and detection (SELD) is a combined task of identifying the sound event and its direction. Deep neural networks (DNNs) are utilized to associate them with the sound signals observed by a microphone array. Although ambisonic microphones are popular in the literature of SELD, they might limit the range of applications due to their predetermined geometry. Some applications (including those for pedestrians that perform SELD while walking) require a wearable microphone array whose geometry can be designed to suit the task. In this paper, for the development of such a wearable SELD, we propose a dataset named Wearable SELD dataset. It consists of data recorded by 24 microphones placed on a head and torso simulators (HATS) with some accessories mimicking wearable devices (glasses, earphones, and headphones). We also provide experimental results of SELD using the proposed dataset and SELDNet to investigate the effect of microphone configuration.
APPLADE: Adjustable Plug-and-play Audio Declipper Combining DNN with Sparse Optimization
Feb 16, 2022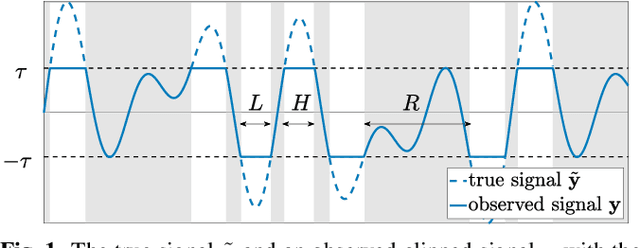
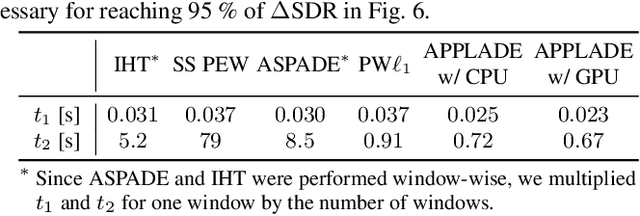
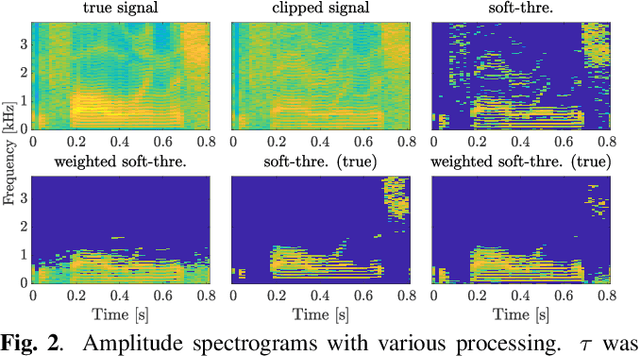
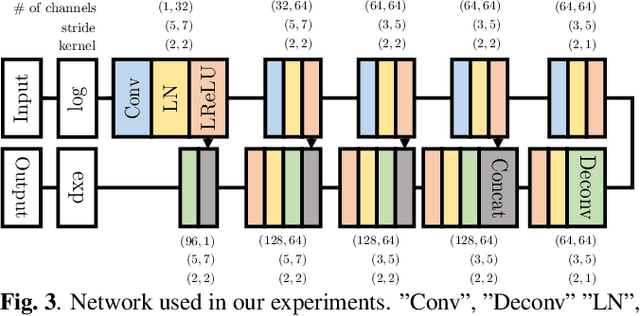
In this paper, we propose an audio declipping method that takes advantages of both sparse optimization and deep learning. Since sparsity-based audio declipping methods have been developed upon constrained optimization, they are adjustable and well-studied in theory. However, they always uniformly promote sparsity and ignore the individual properties of a signal. Deep neural network (DNN)-based methods can learn the properties of target signals and use them for audio declipping. Still, they cannot perform well if the training data have mismatches and/or constraints in the time domain are not imposed. In the proposed method, we use a DNN in an optimization algorithm. It is inspired by an idea called plug-and-play (PnP) and enables us to promote sparsity based on the learned information of data, considering constraints in the time domain. Our experiments confirmed that the proposed method is stable and robust to mismatches between training and test data.
Safeguarding test signals for acoustic measurement using arbitrary sounds
Dec 21, 2021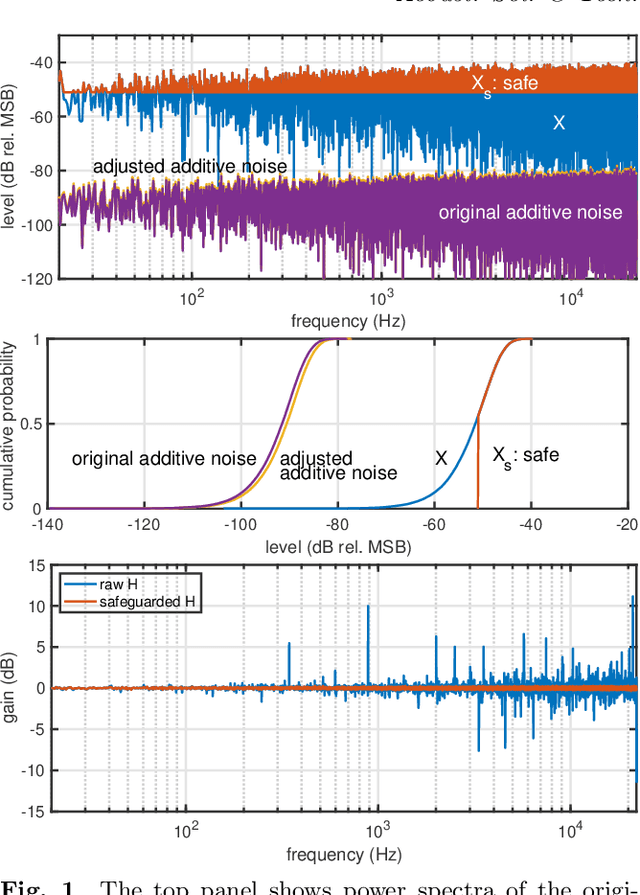
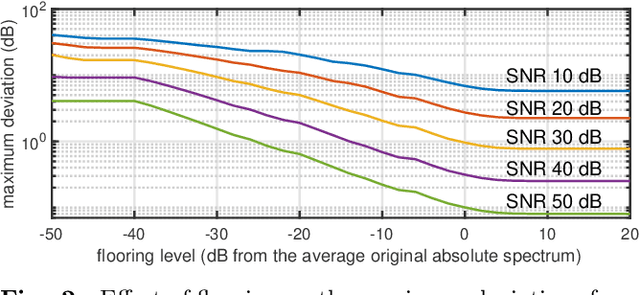
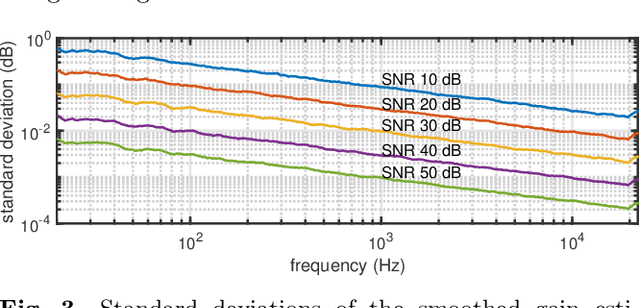
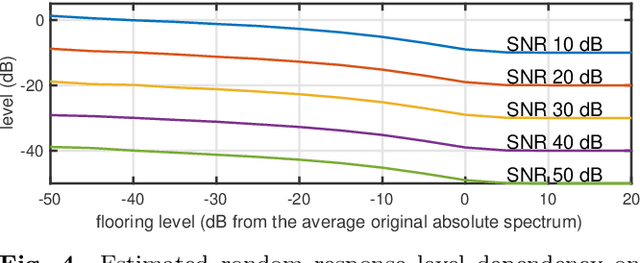
We propose a simple method to measure acoustic responses using any sounds by converting them suitable for measurement. This method enables us to use music pieces for measuring acoustic conditions. It is advantageous to measure such conditions without annoying test sounds to listeners. In addition, applying the underlying idea of simultaneous measurement of multiple paths provides practically valuable features. For example, it is possible to measure deviations (temporally stable, random, and time-varying) and the impulse response while reproducing slightly modified contents under target conditions. The key idea of the proposed method is to add relatively small deterministic signals that sound like noise to the original sounds. We call the converted sounds safeguarded test signals.
Objective measurement of pitch extractors' responses to frequency modulated sounds and two reference pitch extraction methods for analyzing voice pitch responses to auditory stimulation
Nov 05, 2021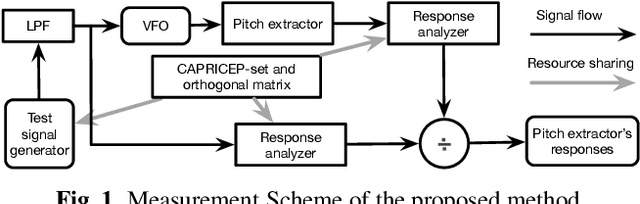
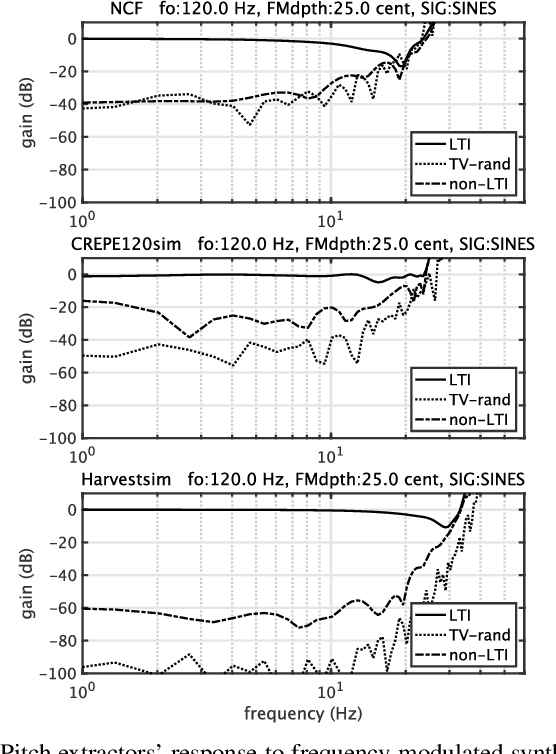
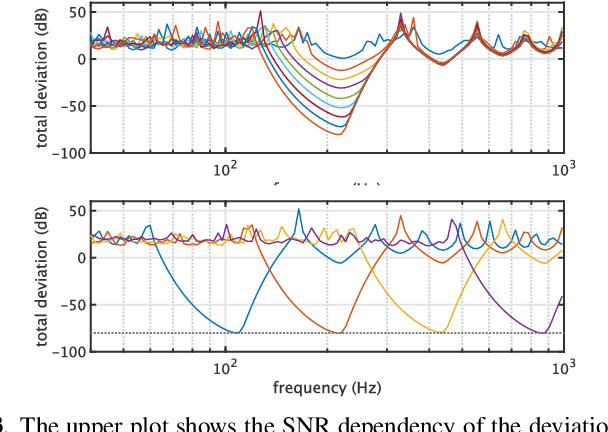
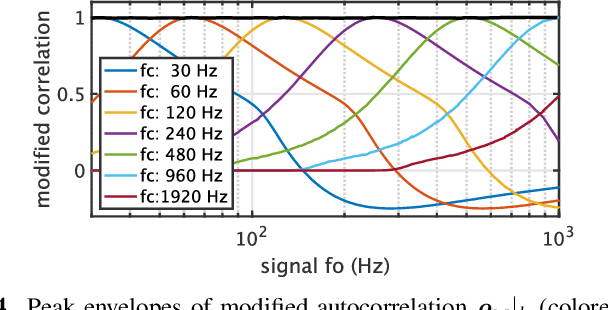
We propose an objective measurement method for pitch extractors' responses to frequency-modulated signals. The method simultaneously measures the linear and the non-linear time-invariant responses and random and time-varying responses. It uses extended time-stretched pulses combined by binary orthogonal sequences. Our recent finding of involuntary voice pitch response to auditory stimulation while voicing motivated this proposal. The involuntary voice pitch response provides means to investigate voice chain subsystems individually and objectively. This response analysis requires reliable and precise pitch extraction. We found that existing pitch extractors failed to correctly analyze signals used for auditory stimulation by using the proposed method. Therefore, we propose two reference pitch extractors based on the instantaneous frequency analysis and multi-resolution power spectrum analysis. The proposed extractors correctly analyze the test signals. We open-sourced MATLAB codes to measure pitch extractors and codes for conducting the voice pitch response experiment on our GitHub repository.
Design of Tight Minimum-Sidelobe Windows by Riemannian Newton's Method
Nov 02, 2021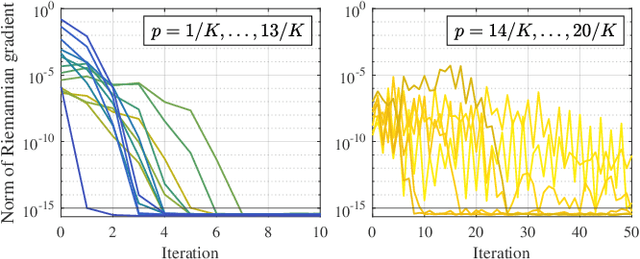
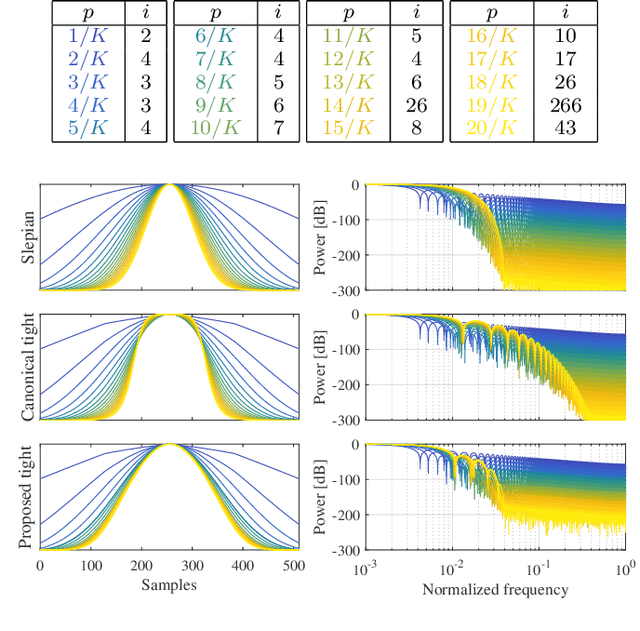
The short-time Fourier transform (STFT), or the discrete Gabor transform (DGT), has been extensively used in signal analysis and processing. Their properties are characterized by a window function, and hence window design is a significant topic up to date. For signal processing, designing a pair of analysis and synthesis windows is important because results of processing in the time-frequency domain are affected by both of them. A tight window is a special window that can perfectly reconstruct a signal by using it for both analysis and synthesis. It is known to make time-frequency-domain processing robust to error, and therefore designing a better tight window is desired. In this paper, we propose a method of designing tight windows that minimize the sidelobe energy. It is formulated as an optimization problem on an oblique manifold, and a Riemannian Newton algorithm on this manifold is derived to efficiently obtain a solution.