 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Heterogeneous Mixtures of Normalising Flows for Robust Variational Inference
Oct 02, 2025



Normalising-flow variational inference (VI) can approximate complex posteriors, yet single-flow models often behave inconsistently across qualitatively different distributions. We propose Adaptive Mixture Flow Variational Inference (AMF-VI), a heterogeneous mixture of complementary flows (MAF, RealNVP, RBIG) trained in two stages: (i) sequential expert training of individual flows, and (ii) adaptive global weight estimation via likelihood-driven updates, without per-sample gating or architectural changes. Evaluated on six canonical posterior families of banana, X-shape, two-moons, rings, a bimodal, and a five-mode mixture, AMF-VI achieves consistently lower negative log-likelihood than each single-flow baseline and delivers stable gains in transport metrics (Wasserstein-2) and maximum mean discrepancy (MDD), indicating improved robustness across shapes and modalities. The procedure is efficient and architecture-agnostic, incurring minimal overhead relative to standard flow training, and demonstrates that adaptive mixtures of diverse flows provide a reliable route to robust VI across diverse posterior families whilst preserving each expert's inductive bias.
Gradient Weighted Superpixels for Interpretability in CNNs
Aug 16, 2019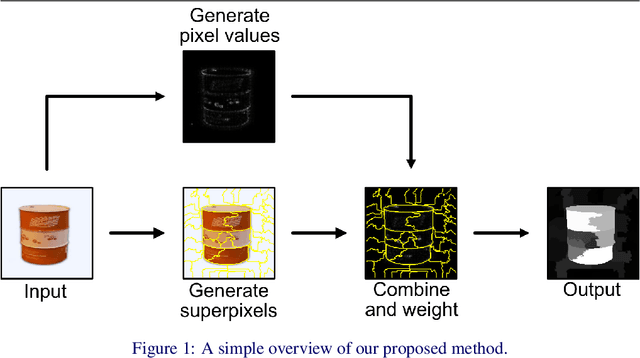
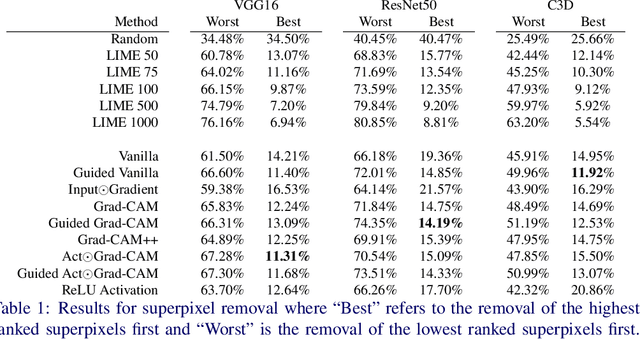
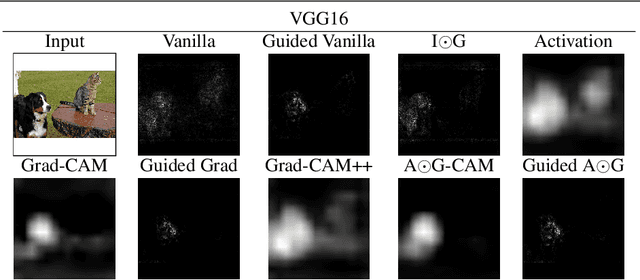
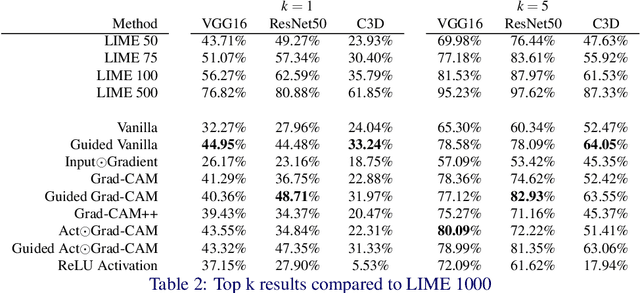
As Convolutional Neural Networks embed themselves into our everyday lives, the need for them to be interpretable increases. However, there is often a trade-off between methods that are efficient to compute but produce an explanation that is difficult to interpret, and those that are slow to compute but provide a more interpretable result. This is particularly challenging in problem spaces that require a large input volume, especially video which combines both spatial and temporal dimensions. In this work we introduce the idea of scoring superpixels through the use of gradient based pixel scoring techniques. We show qualitatively and quantitatively that this is able to approximate LIME, in a fraction of the time. We investigate our techniques using both image classification, and action recognition networks on large scale datasets (ImageNet and Kinetics-400 respectively).
Weakly-Supervised Temporal Localization via Occurrence Count Learning
May 17, 2019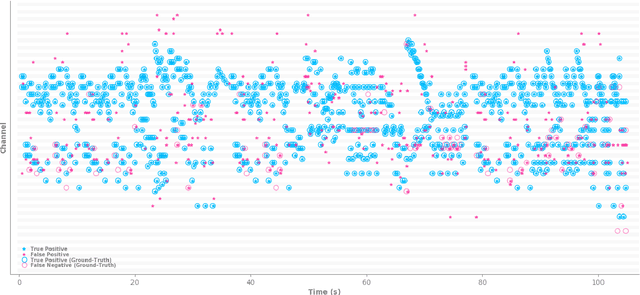
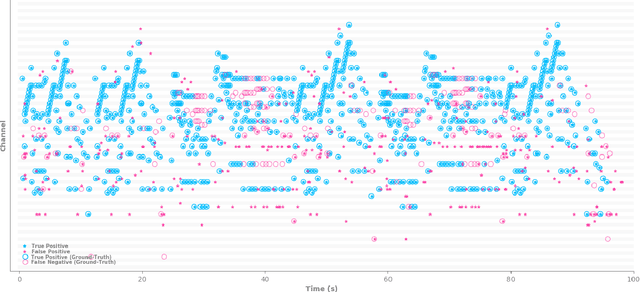
We propose a novel model for temporal detection and localization which allows the training of deep neural networks using only counts of event occurrences as training labels. This powerful weakly-supervised framework alleviates the burden of the imprecise and time-consuming process of annotating event locations in temporal data. Unlike existing methods, in which localization is explicitly achieved by design, our model learns localization implicitly as a byproduct of learning to count instances. This unique feature is a direct consequence of the model's theoretical properties. We validate the effectiveness of our approach in a number of experiments (drum hit and piano onset detection in audio, digit detection in images) and demonstrate performance comparable to that of fully-supervised state-of-the-art methods, despite much weaker training requirements.