 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUIT-HWDB: Using Transferring Method to Construct A Novel Benchmark for Evaluating Unconstrained Handwriting Image Recognition in Vietnamese
Nov 10, 2022



Recognizing handwriting images is challenging due to the vast variation in writing style across many people and distinct linguistic aspects of writing languages. In Vietnamese, besides the modern Latin characters, there are accent and letter marks together with characters that draw confusion to state-of-the-art handwriting recognition methods. Moreover, as a low-resource language, there are not many datasets for researching handwriting recognition in Vietnamese, which makes handwriting recognition in this language have a barrier for researchers to approach. Recent works evaluated offline handwriting recognition methods in Vietnamese using images from an online handwriting dataset constructed by connecting pen stroke coordinates without further processing. This approach obviously can not measure the ability of recognition methods effectively, as it is trivial and may be lack of features that are essential in offline handwriting images. Therefore, in this paper, we propose the Transferring method to construct a handwriting image dataset that associates crucial natural attributes required for offline handwriting images. Using our method, we provide a first high-quality synthetic dataset which is complex and natural for efficiently evaluating handwriting recognition methods. In addition, we conduct experiments with various state-of-the-art methods to figure out the challenge to reach the solution for handwriting recognition in Vietnamese.
SMTCE: A Social Media Text Classification Evaluation Benchmark and BERTology Models for Vietnamese
Sep 21, 2022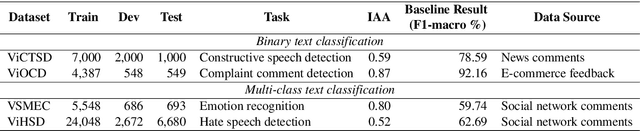
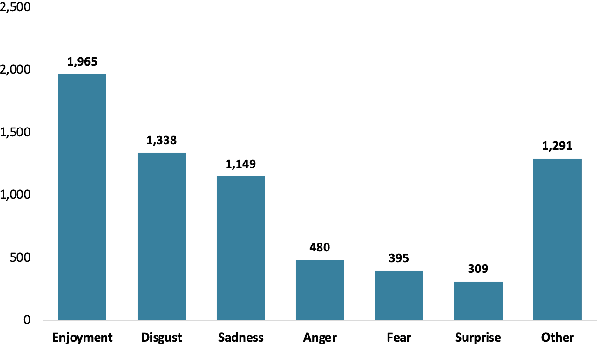
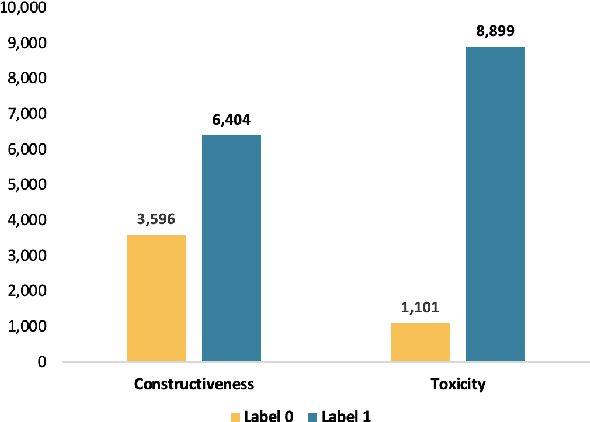
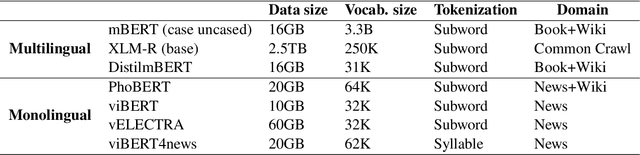
Text classification is a typical natural language processing or computational linguistics task with various interesting applications. As the number of users on social media platforms increases, data acceleration promotes emerging studies on Social Media Text Classification (SMTC) or social media text mining on these valuable resources. In contrast to English, Vietnamese, one of the low-resource languages, is still not concentrated on and exploited thoroughly. Inspired by the success of the GLUE, we introduce the Social Media Text Classification Evaluation (SMTCE) benchmark, as a collection of datasets and models across a diverse set of SMTC tasks. With the proposed benchmark, we implement and analyze the effectiveness of a variety of multilingual BERT-based models (mBERT, XLM-R, and DistilmBERT) and monolingual BERT-based models (PhoBERT, viBERT, vELECTRA, and viBERT4news) for tasks in the SMTCE benchmark. Monolingual models outperform multilingual models and achieve state-of-the-art results on all text classification tasks. It provides an objective assessment of multilingual and monolingual BERT-based models on the benchmark, which will benefit future studies about BERTology in the Vietnamese language.
SPBERTQA: A Two-Stage Question Answering System Based on Sentence Transformers for Medical Texts
Jun 20, 2022

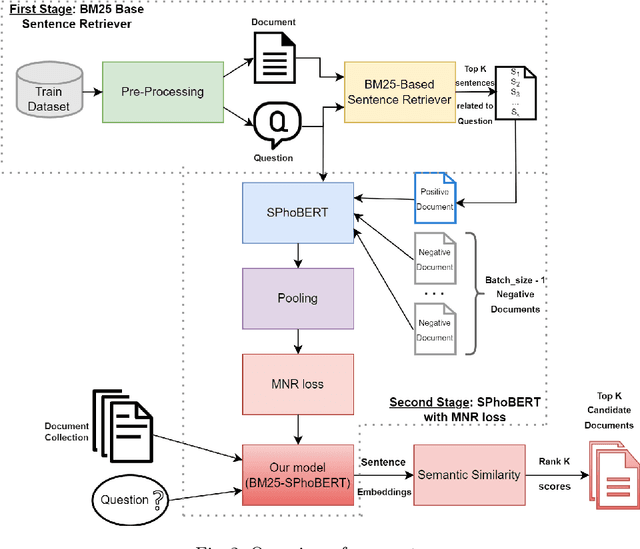
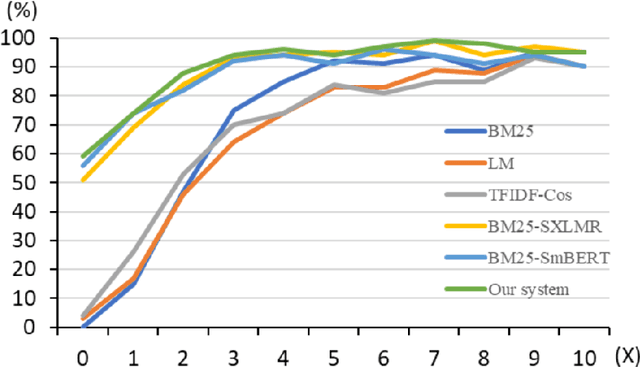
Question answering (QA) systems have gained explosive attention in recent years. However, QA tasks in Vietnamese do not have many datasets. Significantly, there is mostly no dataset in the medical domain. Therefore, we built a Vietnamese Healthcare Question Answering dataset (ViHealthQA), including 10,015 question-answer passage pairs for this task, in which questions from health-interested users were asked on prestigious health websites and answers from highly qualified experts. This paper proposes a two-stage QA system based on Sentence-BERT (SBERT) using multiple negatives ranking (MNR) loss combined with BM25. Then, we conduct diverse experiments with many bag-of-words models to assess our system's performance. With the obtained results, this system achieves better performance than traditional methods.
Vietnamese Hate and Offensive Detection using PhoBERT-CNN and Social Media Streaming Data
Jun 01, 2022

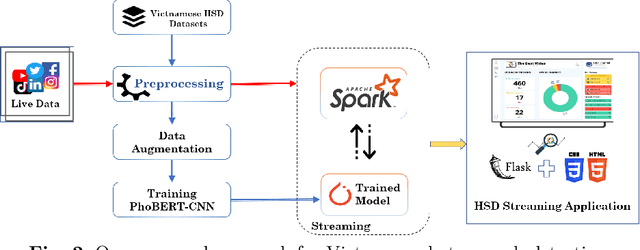

Society needs to develop a system to detect hate and offense to build a healthy and safe environment. However, current research in this field still faces four major shortcomings, including deficient pre-processing techniques, indifference to data imbalance issues, modest performance models, and lacking practical applications. This paper focused on developing an intelligent system capable of addressing these shortcomings. Firstly, we proposed an efficient pre-processing technique to clean comments collected from Vietnamese social media. Secondly, a novel hate speech detection (HSD) model, which is the combination of a pre-trained PhoBERT model and a Text-CNN model, was proposed for solving tasks in Vietnamese. Thirdly, EDA techniques are applied to deal with imbalanced data to improve the performance of classification models. Besides, various experiments were conducted as baselines to compare and investigate the proposed model's performance against state-of-the-art methods. The experiment results show that the proposed PhoBERT-CNN model outperforms SOTA methods and achieves an F1-score of 67,46% and 98,45% on two benchmark datasets, ViHSD and HSD-VLSP, respectively. Finally, we also built a streaming HSD application to demonstrate the practicality of our proposed system.
XLMRQA: Open-Domain Question Answering on Vietnamese Wikipedia-based Textual Knowledge Source
Apr 14, 2022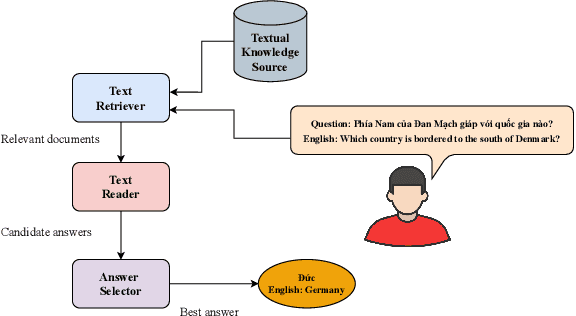
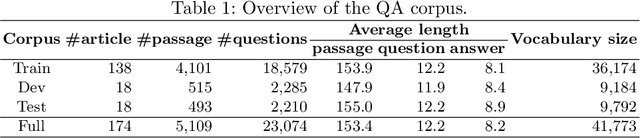
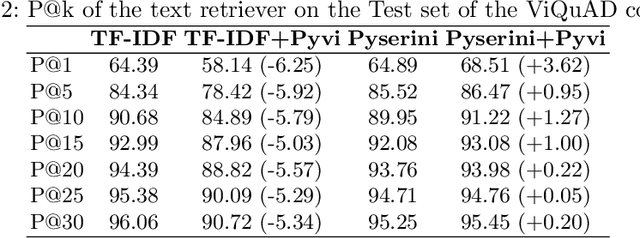
Question answering (QA) is a natural language understanding task within the fields of information retrieval and information extraction that has attracted much attention from the computational linguistics and artificial intelligence research community in recent years because of the strong development of machine reading comprehension-based models. A reader-based QA system is a high-level search engine that can find correct answers to queries or questions in open-domain or domain-specific texts using machine reading comprehension (MRC) techniques. The majority of advancements in data resources and machine-learning approaches in the MRC and QA systems, on the other hand, especially in two resource-rich languages such as English and Chinese. A low-resource language like Vietnamese has witnessed a scarcity of research on QA systems. This paper presents XLMRQA, the first Vietnamese QA system using a supervised transformer-based reader on the Wikipedia-based textual knowledge source (using the UIT-ViQuAD corpus), outperforming the two robust QA systems using deep neural network models: DrQA and BERTserini with 24.46% and 6.28%, respectively. From the results obtained on the three systems, we analyze the influence of question types on the performance of the QA systems.
VLSP 2021 - ViMRC Challenge: Vietnamese Machine Reading Comprehension
Apr 04, 2022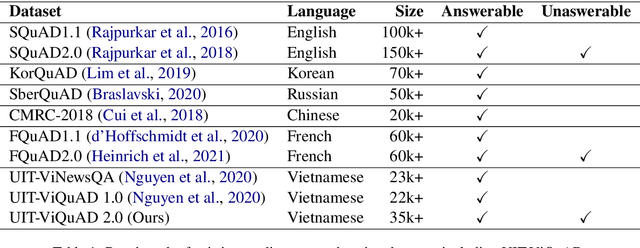
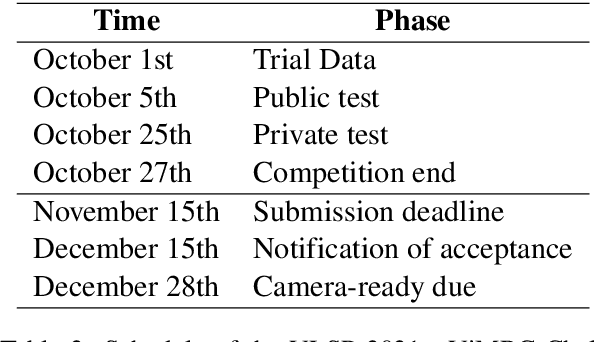
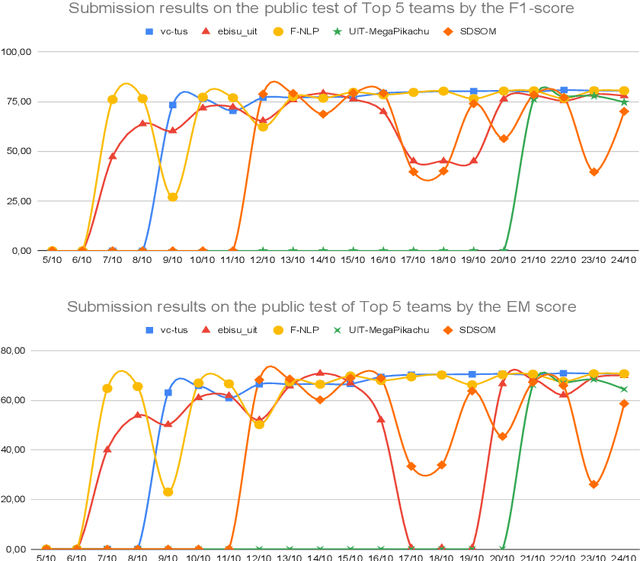

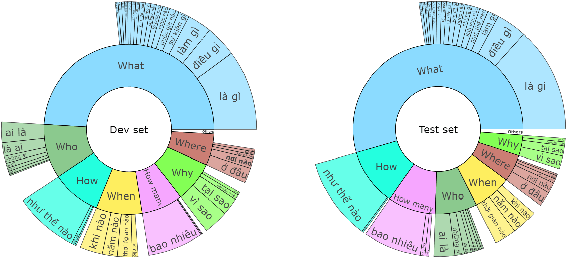
One of the emerging research trends in natural language understanding is machine reading comprehension (MRC) which is the task to find answers to human questions based on textual data. Existing Vietnamese datasets for MRC research concentrate solely on answerable questions. However, in reality, questions can be unanswerable for which the correct answer is not stated in the given textual data. To address the weakness, we provide the research community with a benchmark dataset named UIT-ViQuAD 2.0 for evaluating the MRC task and question answering systems for the Vietnamese language. We use UIT-ViQuAD 2.0 as a benchmark dataset for the challenge on Vietnamese MRC at the Eighth Workshop on Vietnamese Language and Speech Processing (VLSP 2021). This task attracted 77 participant teams from 34 universities and other organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 77.24% in F1-score and 67.43% in Exact Match on the private test set. The Vietnamese MRC systems proposed by the top 3 teams use XLM-RoBERTa, a powerful pre-trained language model based on the transformer architecture. The UIT-ViQuAD 2.0 dataset motivates researchers to further explore the Vietnamese machine reading comprehension task and related tasks such as question answering, question generation, and natural language inference.
Joint Chinese Word Segmentation and Part-of-speech Tagging via Two-stage Span Labeling
Dec 17, 2021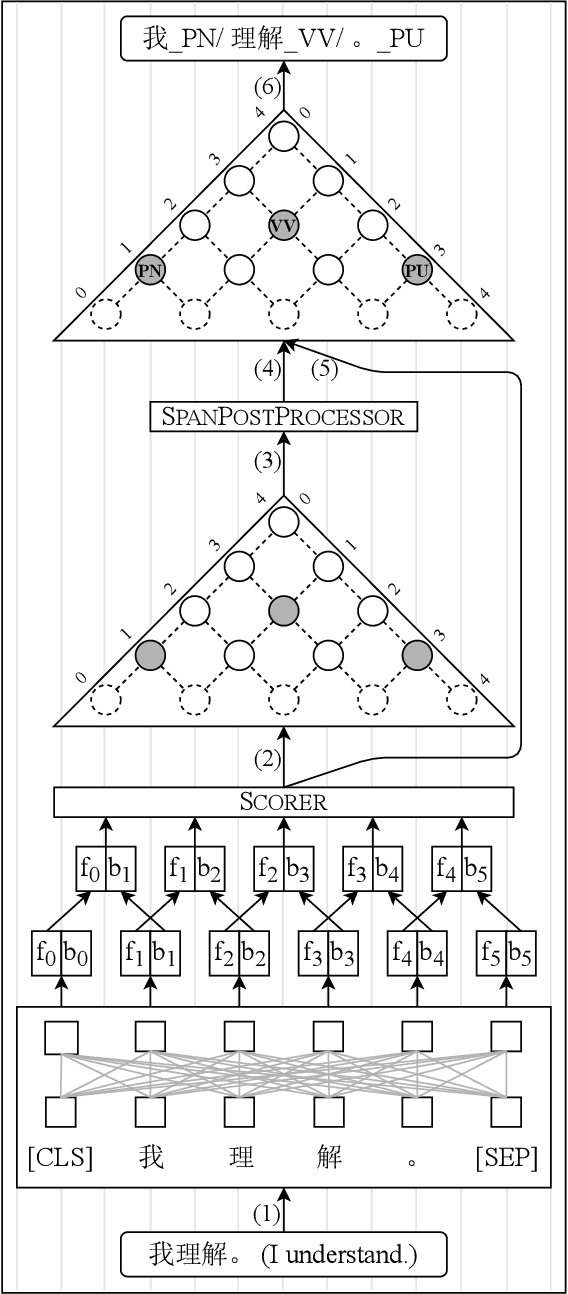
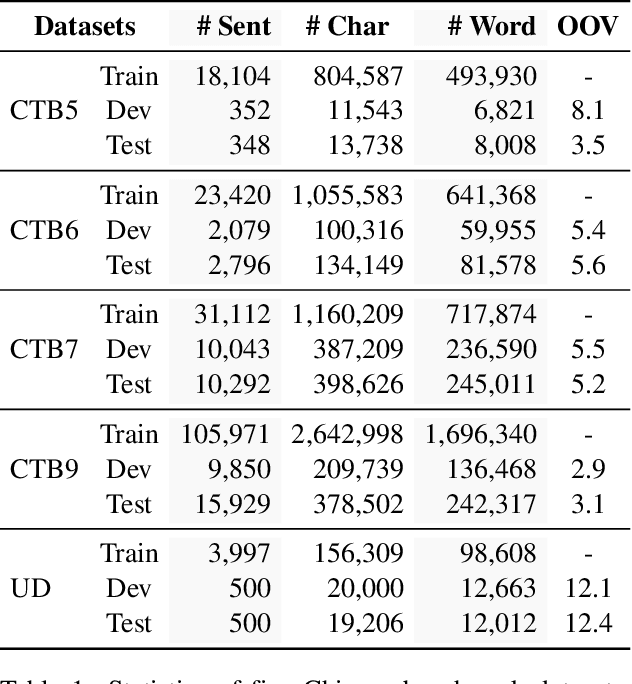
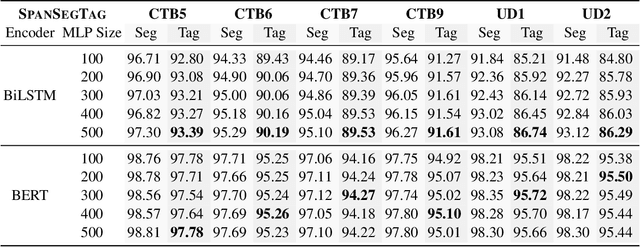
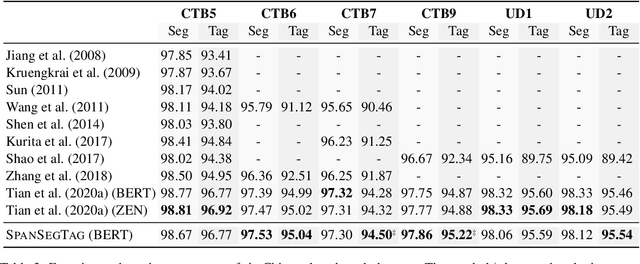
Chinese word segmentation and part-of-speech tagging are necessary tasks in terms of computational linguistics and application of natural language processing. Many re-searchers still debate the demand for Chinese word segmentation and part-of-speech tagging in the deep learning era. Nevertheless, resolving ambiguities and detecting unknown words are challenging problems in this field. Previous studies on joint Chinese word segmentation and part-of-speech tagging mainly follow the character-based tagging model focusing on modeling n-gram features. Unlike previous works, we propose a neural model named SpanSegTag for joint Chinese word segmentation and part-of-speech tagging following the span labeling in which the probability of each n-gram being the word and the part-of-speech tag is the main problem. We use the biaffine operation over the left and right boundary representations of consecutive characters to model the n-grams. Our experiments show that our BERT-based model SpanSegTag achieved competitive performances on the CTB5, CTB6, and UD, or significant improvements on CTB7 and CTB9 benchmark datasets compared with the current state-of-the-art method using BERT or ZEN encoders.
Span Detection for Aspect-Based Sentiment Analysis in Vietnamese
Oct 15, 2021



Aspect-based sentiment analysis plays an essential role in natural language processing and artificial intelligence. Recently, researchers only focused on aspect detection and sentiment classification but ignoring the sub-task of detecting user opinion span, which has enormous potential in practical applications. In this paper, we present a new Vietnamese dataset (UIT-ViSD4SA) consisting of 35,396 human-annotated spans on 11,122 feedback comments for evaluating the span detection in aspect-based sentiment analysis. Besides, we also propose a novel system using Bidirectional Long Short-Term Memory (BiLSTM) with a Conditional Random Field (CRF) layer (BiLSTM-CRF) for the span detection task in Vietnamese aspect-based sentiment analysis. The best result is a 62.76% F1 score (macro) for span detection using BiLSTM-CRF with embedding fusion of syllable embedding, character embedding, and contextual embedding from XLM-RoBERTa. In future work, span detection will be extended in many NLP tasks such as constructive detection, emotion recognition, complaint analysis, and opinion mining. Our dataset is freely available at https://github.com/kimkim00/UIT-ViSD4SA for research purposes.
Monolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization
Aug 31, 2021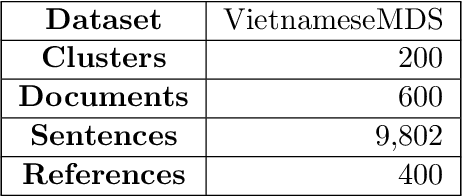
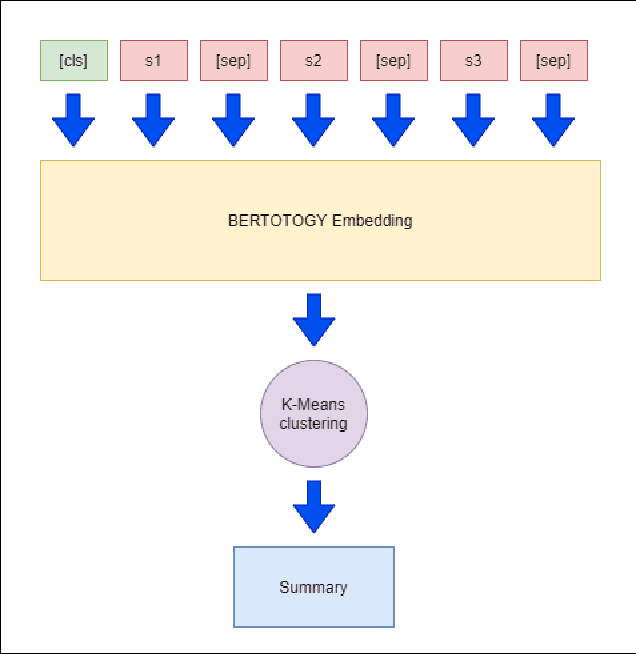
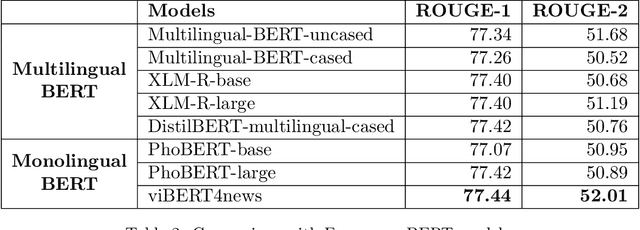
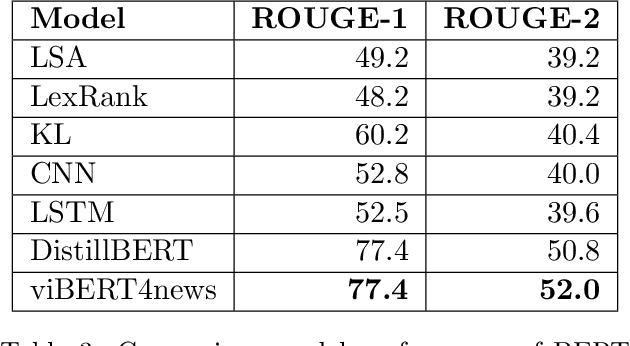
Recent researches have demonstrated that BERT shows potential in a wide range of natural language processing tasks. It is adopted as an encoder for many state-of-the-art automatic summarizing systems, which achieve excellent performance. However, so far, there is not much work done for Vietnamese. In this paper, we showcase how BERT can be implemented for extractive text summarization in Vietnamese. We introduce a novel comparison between different multilingual and monolingual BERT models. The experiment results indicate that monolingual models produce promising results compared to other multilingual models and previous text summarizing models for Vietnamese.
VinaFood21: A Novel Dataset for Evaluating Vietnamese Food Recognition
Aug 06, 2021Vietnam is such an attractive tourist destination with its stunning and pristine landscapes and its top-rated unique food and drink. Among thousands of Vietnamese dishes, foreigners and native people are interested in easy-to-eat tastes and easy-to-do recipes, along with reasonable prices, mouthwatering flavors, and popularity. Due to the diversity and almost all the dishes have significant similarities and the lack of quality Vietnamese food datasets, it is hard to implement an auto system to classify Vietnamese food, therefore, make people easier to discover Vietnamese food. This paper introduces a new Vietnamese food dataset named VinaFood21, which consists of 13,950 images corresponding to 21 dishes. We use 10,044 images for model training and 6,682 test images to classify each food in the VinaFood21 dataset and achieved an average accuracy of 74.81% when fine-tuning CNN EfficientNet-B0. (https://github.com/nguyenvd-uit/uit-together-dataset)