 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Overthink It: Inter-Rollout Action Agreement as a Free Adaptive-Compute Signal for LLM Agents
Apr 09, 2026Inference-time compute scaling has emerged as a powerful technique for improving the reliability of large language model (LLM) agents, but existing methods apply compute uniformly: every decision step receives the same budget regardless of its difficulty. We introduce TrACE (Trajectorical Adaptive Compute via agrEement), a training-free controller that allocates LLM calls adaptively across agent timesteps by measuring inter-rollout action agreement. At each step, TrACE samples a small set of candidate next actions and measures how consistently the model commits to the same action. High agreement signals an easy decision; the controller commits immediately. Low agreement signals uncertainty; the controller samples additional rollouts up to a configurable cap before committing to the plurality action. No learned components, no external verifier, and no human labels are required. We evaluate TrACE against greedy decoding and fixed-budget self-consistency (SC-4, SC-8) on two benchmarks spanning single-step reasoning (GSM8K, n=50) and multi-step household navigation (MiniHouse, n=30), using a Qwen 2.5 3B Instruct model running on CPU. TrACE-4 matches SC-4 accuracy while using 33% fewer LLM calls on GSM8K and 39% fewer on MiniHouse. TrACE-8 matches SC-8 accuracy with 55% fewer calls on GSM8K and 65% fewer on MiniHouse. We further show that inter-rollout agreement is a reliable signal of step-level success, validating the core hypothesis that the model's own output consistency encodes difficulty information that can be exploited without training. TrACE is the first training-free, per-timestep adaptive-compute controller for LLM agents to be evaluated on multi-step sequential decision tasks.
Low-Power Hardware-Based Deep-Learning Diagnostics Support Case Study
Sep 03, 2022
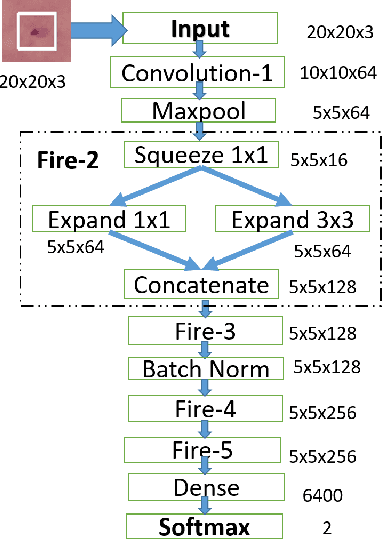
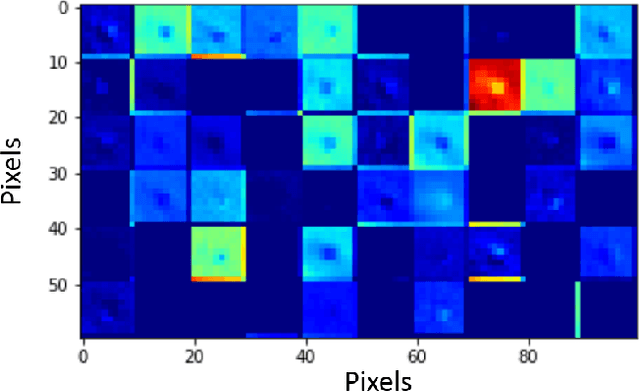

Deep learning research has generated widespread interest leading to emergence of a large variety of technological innovations and applications. As significant proportion of deep learning research focuses on vision based applications, there exists a potential for using some of these techniques to enable low-power portable health-care diagnostic support solutions. In this paper, we propose an embedded-hardware-based implementation of microscopy diagnostic support system for PoC case study on: (a) Malaria in thick blood smears, (b) Tuberculosis in sputum samples, and (c) Intestinal parasite infection in stool samples. We use a Squeeze-Net based model to reduce the network size and computation time. We also utilize the Trained Quantization technique to further reduce memory footprint of the learned models. This enables microscopy-based detection of pathogens that classifies with laboratory expert level accuracy as a standalone embedded hardware platform. The proposed implementation is 6x more power-efficient compared to conventional CPU-based implementation and has an inference time of $\sim$ 3 ms/sample.
DRAGON : A suite of Hardware Simulation and Optimization tools for Modern Workloads
Apr 25, 2022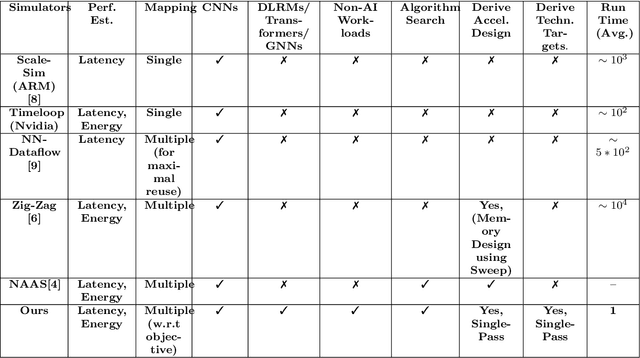
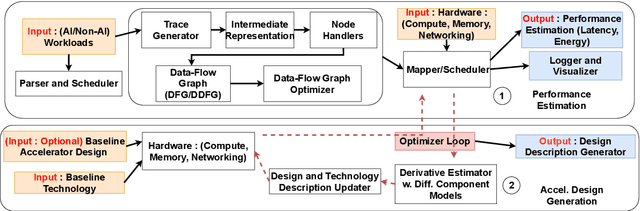
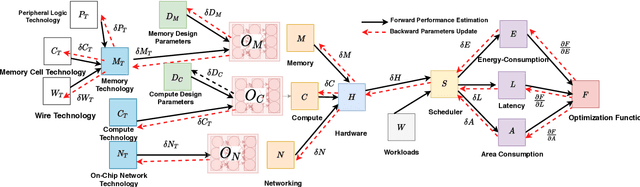
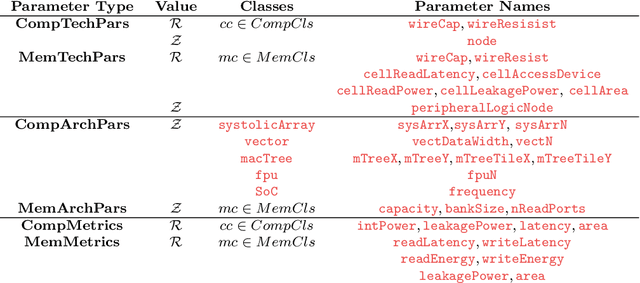
We introduce DRAGON, an open-source, fast and explainable toolchain hardware simulation and optimization enables hardware architects to simulate hardware designs, and to optimize hardware designs to efficiently execute workloads. The DRAGON toolchain provides the following tools: Hardware Model Generator (DGen), Hardware Simulator (DSim) and Hardware Optimizer (DOpt). DSim provides the simulation of running algorithms (represented as data-flow graphs) on hardware described. DGen describes the hardware in detail, with user input architectures/technology (represented in a custom description language). A novel methodology of gradient descent from the simulation allows us optimize the hardware model (giving the directions for improvements in technology parameters and design parameters), provided by Dopt. DRAGON framework (DSim) is much faster than previously avaible works for simulation, which is possible through performance-first code writing practices, mathematical formulas for common computing operations to avoid cycle-accurate simulation steps, efficient algorithms for mapping, and data-structure representations for hardware state. DRAGON framework (Dopt) generates architectures for both AI and Non-AI Workloads, compared to previously published works \cite{samajdar2018scale,yang2020interstellar} are 5x better and provides technology targets for improving these hardware designs to 100x-1000x better computing systems.