 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbstract Meaning Representation for Multi-Document Summarization
Jun 14, 2018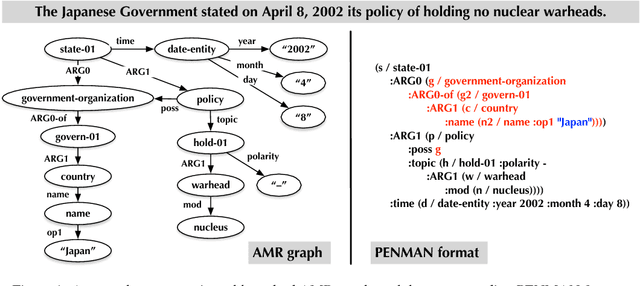
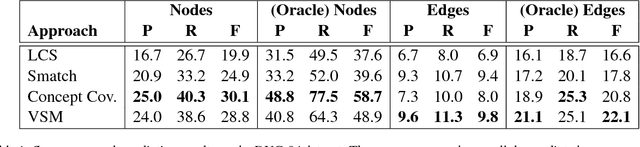
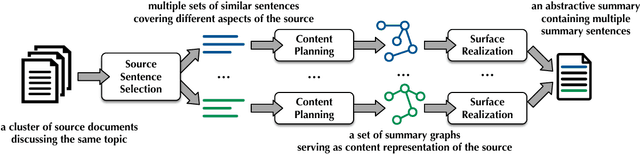
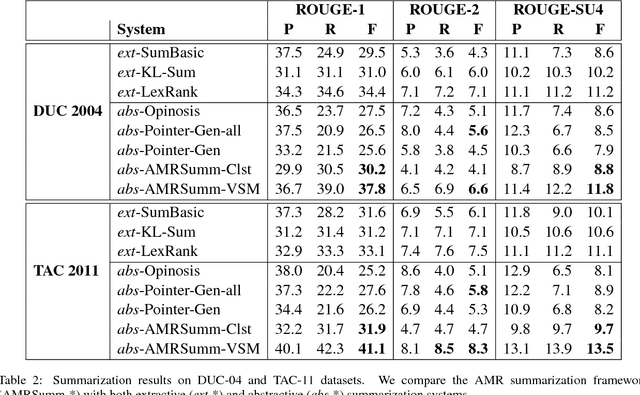
Generating an abstract from a collection of documents is a desirable capability for many real-world applications. However, abstractive approaches to multi-document summarization have not been thoroughly investigated. This paper studies the feasibility of using Abstract Meaning Representation (AMR), a semantic representation of natural language grounded in linguistic theory, as a form of content representation. Our approach condenses source documents to a set of summary graphs following the AMR formalism. The summary graphs are then transformed to a set of summary sentences in a surface realization step. The framework is fully data-driven and flexible. Each component can be optimized independently using small-scale, in-domain training data. We perform experiments on benchmark summarization datasets and report promising results. We also describe opportunities and challenges for advancing this line of research.
Modeling Language Vagueness in Privacy Policies using Deep Neural Networks
May 25, 2018
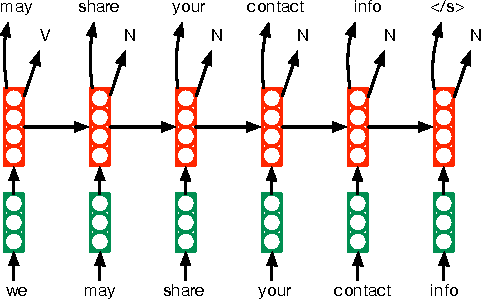
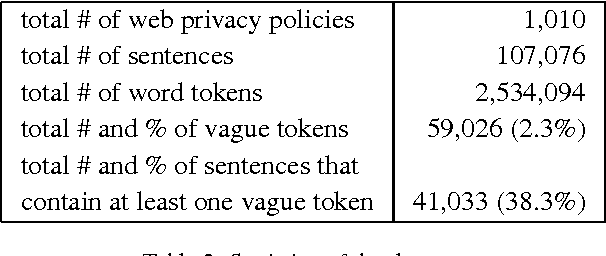
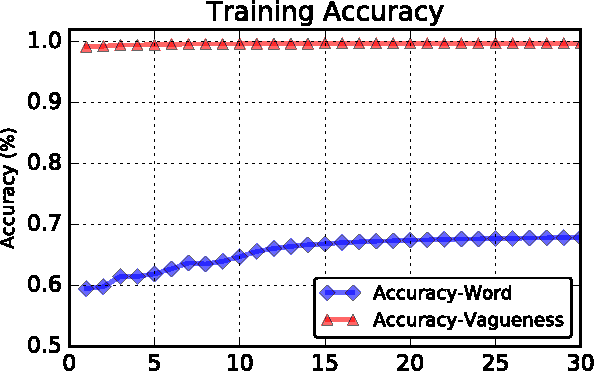
Website privacy policies are too long to read and difficult to understand. The over-sophisticated language makes privacy notices to be less effective than they should be. People become even less willing to share their personal information when they perceive the privacy policy as vague. This paper focuses on decoding vagueness from a natural language processing perspective. While thoroughly identifying the vague terms and their linguistic scope remains an elusive challenge, in this work we seek to learn vector representations of words in privacy policies using deep neural networks. The vector representations are fed to an interactive visualization tool (LSTMVis) to test on their ability to discover syntactically and semantically related vague terms. The approach holds promise for modeling and understanding language vagueness.