 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOops I Took A Gradient: Scalable Sampling for Discrete Distributions
Feb 08, 2021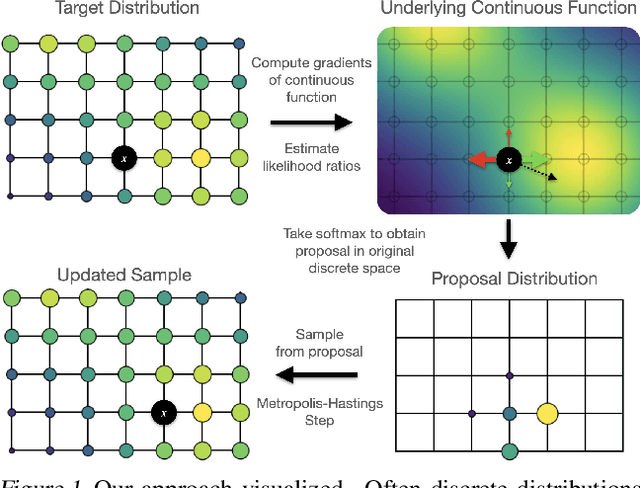

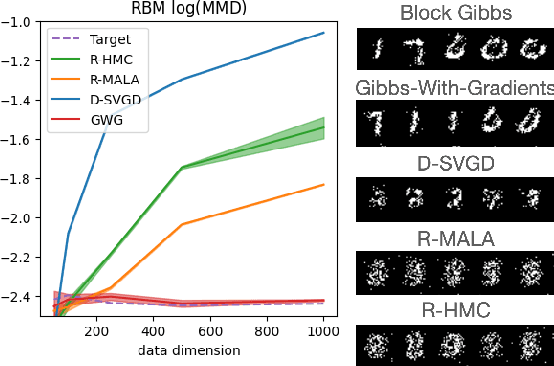
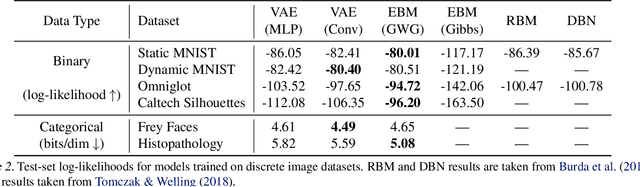
We propose a general and scalable approximate sampling strategy for probabilistic models with discrete variables. Our approach uses gradients of the likelihood function with respect to its discrete inputs to propose updates in a Metropolis-Hastings sampler. We show empirically that this approach outperforms generic samplers in a number of difficult settings including Ising models, Potts models, restricted Boltzmann machines, and factorial hidden Markov models. We also demonstrate the use of our improved sampler for training deep energy-based models on high dimensional discrete data. This approach outperforms variational auto-encoders and existing energy-based models. Finally, we give bounds showing that our approach is near-optimal in the class of samplers which propose local updates.
Apollo: Transferable Architecture Exploration
Feb 02, 2021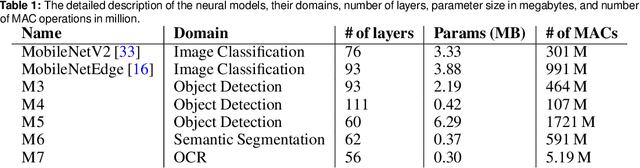
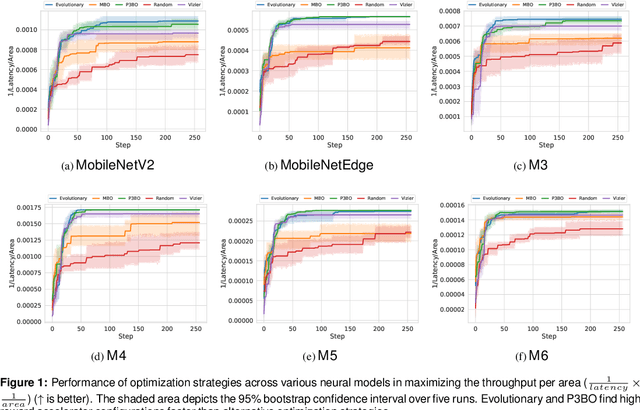

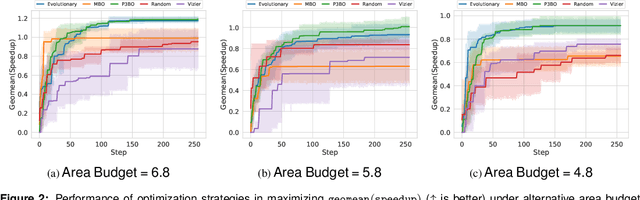
The looming end of Moore's Law and ascending use of deep learning drives the design of custom accelerators that are optimized for specific neural architectures. Architecture exploration for such accelerators forms a challenging constrained optimization problem over a complex, high-dimensional, and structured input space with a costly to evaluate objective function. Existing approaches for accelerator design are sample-inefficient and do not transfer knowledge between related optimizations tasks with different design constraints, such as area and/or latency budget, or neural architecture configurations. In this work, we propose a transferable architecture exploration framework, dubbed Apollo, that leverages recent advances in black-box function optimization for sample-efficient accelerator design. We use this framework to optimize accelerator configurations of a diverse set of neural architectures with alternative design constraints. We show that our framework finds high reward design configurations (up to 24.6% speedup) more sample-efficiently than a baseline black-box optimization approach. We further show that by transferring knowledge between target architectures with different design constraints, Apollo is able to find optimal configurations faster and often with better objective value (up to 25% improvements). This encouraging outcome portrays a promising path forward to facilitate generating higher quality accelerators.
Human 3D keypoints via spatial uncertainty modeling
Dec 18, 2020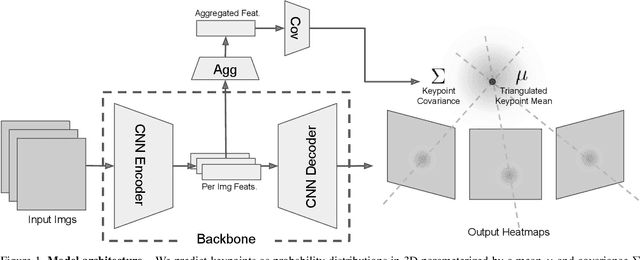
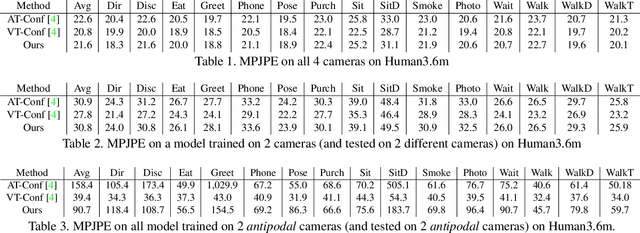

We introduce a technique for 3D human keypoint estimation that directly models the notion of spatial uncertainty of a keypoint. Our technique employs a principled approach to modelling spatial uncertainty inspired from techniques in robust statistics. Furthermore, our pipeline requires no 3D ground truth labels, relying instead on (possibly noisy) 2D image-level keypoints. Our method achieves near state-of-the-art performance on Human3.6m while being efficient to evaluate and straightforward to
No MCMC for me: Amortized sampling for fast and stable training of energy-based models
Oct 14, 2020
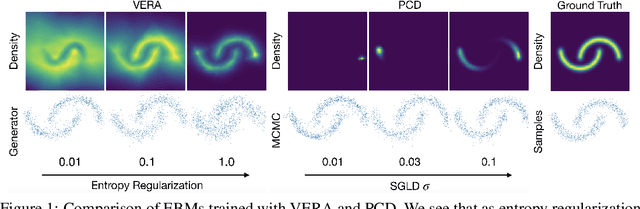


Energy-Based Models (EBMs) present a flexible and appealing way to represent uncertainty. Despite recent advances, training EBMs on high-dimensional data remains a challenging problem as the state-of-the-art approaches are costly, unstable, and require considerable tuning and domain expertise to apply successfully. In this work, we present a simple method for training EBMs at scale which uses an entropy-regularized generator to amortize the MCMC sampling typically used in EBM training. We improve upon prior MCMC-based entropy regularization methods with a fast variational approximation. We demonstrate the effectiveness of our approach by using it to train tractable likelihood models. Next, we apply our estimator to the recently proposed Joint Energy Model (JEM), where we match the original performance with faster and stable training. This allows us to extend JEM models to semi-supervised classification on tabular data from a variety of continuous domains.
Learned Hardware/Software Co-Design of Neural Accelerators
Oct 05, 2020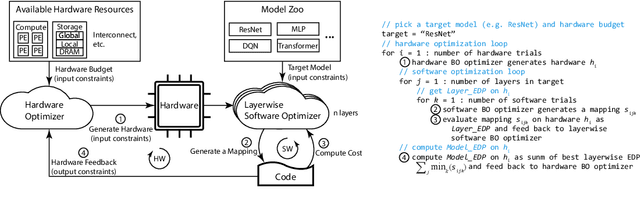
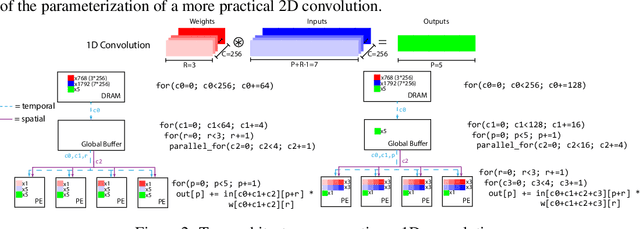
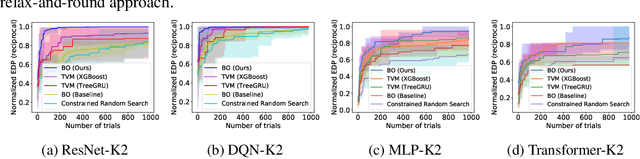
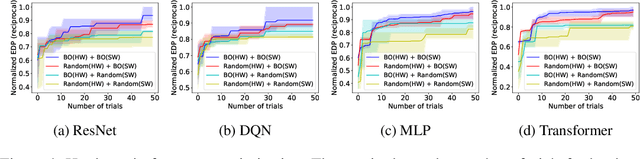
The use of deep learning has grown at an exponential rate, giving rise to numerous specialized hardware and software systems for deep learning. Because the design space of deep learning software stacks and hardware accelerators is diverse and vast, prior work considers software optimizations separately from hardware architectures, effectively reducing the search space. Unfortunately, this bifurcated approach means that many profitable design points are never explored. This paper instead casts the problem as hardware/software co-design, with the goal of automatically identifying desirable points in the joint design space. The key to our solution is a new constrained Bayesian optimization framework that avoids invalid solutions by exploiting the highly constrained features of this design space, which are semi-continuous/semi-discrete. We evaluate our optimization framework by applying it to a variety of neural models, improving the energy-delay product by 18% (ResNet) and 40% (DQN) over hand-tuned state-of-the-art systems, as well as demonstrating strong results on other neural network architectures, such as MLPs and Transformers.
Optimizing Long-term Social Welfare in Recommender Systems: A Constrained Matching Approach
Aug 18, 2020
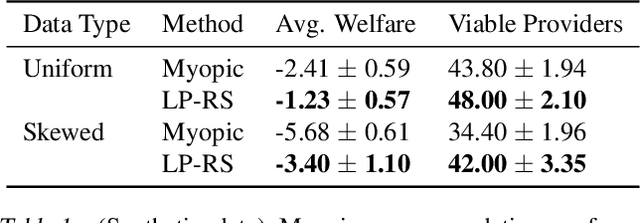
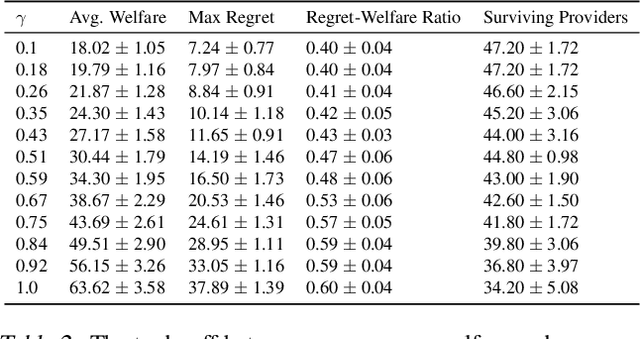
Most recommender systems (RS) research assumes that a user's utility can be maximized independently of the utility of the other agents (e.g., other users, content providers). In realistic settings, this is often not true---the dynamics of an RS ecosystem couple the long-term utility of all agents. In this work, we explore settings in which content providers cannot remain viable unless they receive a certain level of user engagement. We formulate the recommendation problem in this setting as one of equilibrium selection in the induced dynamical system, and show that it can be solved as an optimal constrained matching problem. Our model ensures the system reaches an equilibrium with maximal social welfare supported by a sufficiently diverse set of viable providers. We demonstrate that even in a simple, stylized dynamical RS model, the standard myopic approach to recommendation---always matching a user to the best provider---performs poorly. We develop several scalable techniques to solve the matching problem, and also draw connections to various notions of user regret and fairness, arguing that these outcomes are fairer in a utilitarian sense.
An Imitation Learning Approach for Cache Replacement
Jul 09, 2020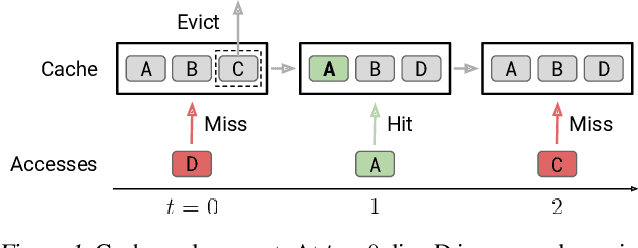
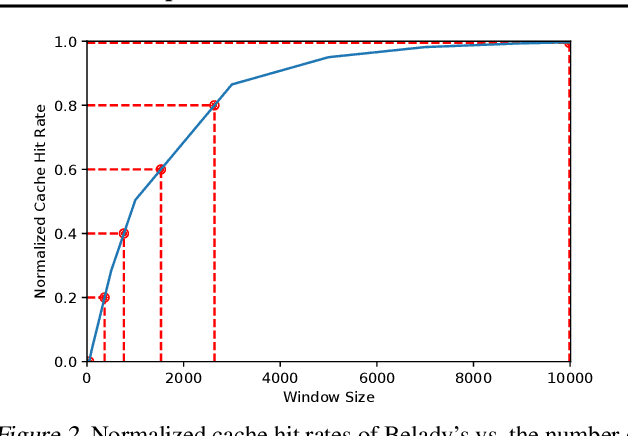
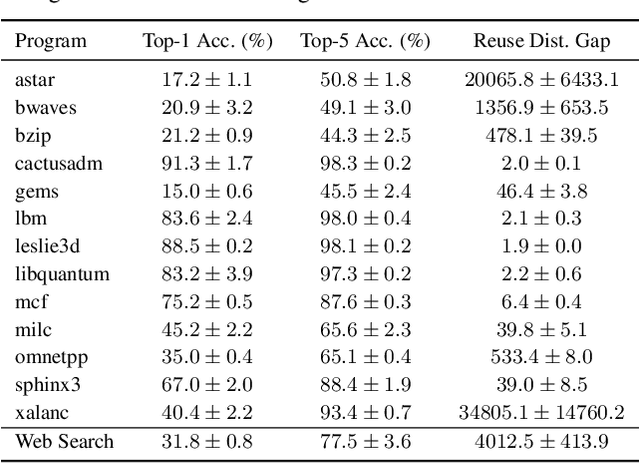
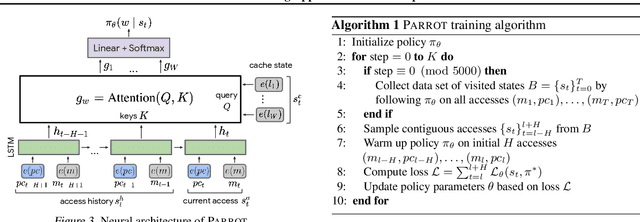
Program execution speed critically depends on increasing cache hits, as cache hits are orders of magnitude faster than misses. To increase cache hits, we focus on the problem of cache replacement: choosing which cache line to evict upon inserting a new line. This is challenging because it requires planning far ahead and currently there is no known practical solution. As a result, current replacement policies typically resort to heuristics designed for specific common access patterns, which fail on more diverse and complex access patterns. In contrast, we propose an imitation learning approach to automatically learn cache access patterns by leveraging Belady's, an oracle policy that computes the optimal eviction decision given the future cache accesses. While directly applying Belady's is infeasible since the future is unknown, we train a policy conditioned only on past accesses that accurately approximates Belady's even on diverse and complex access patterns, and call this approach Parrot. When evaluated on 13 of the most memory-intensive SPEC applications, Parrot increases cache miss rates by 20% over the current state of the art. In addition, on a large-scale web search benchmark, Parrot increases cache hit rates by 61% over a conventional LRU policy. We release a Gym environment to facilitate research in this area, as data is plentiful, and further advancements can have significant real-world impact.
Neural Execution Engines: Learning to Execute Subroutines
Jun 23, 2020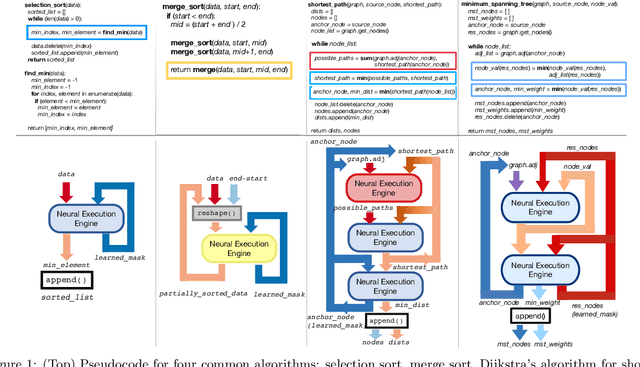
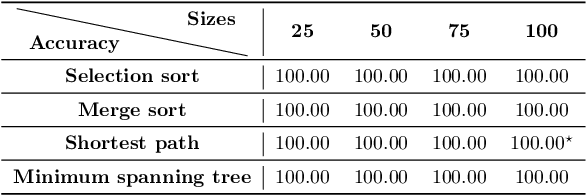
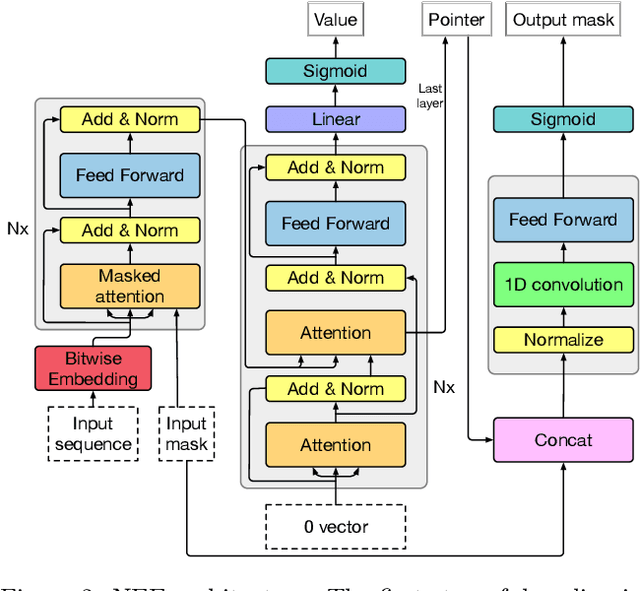
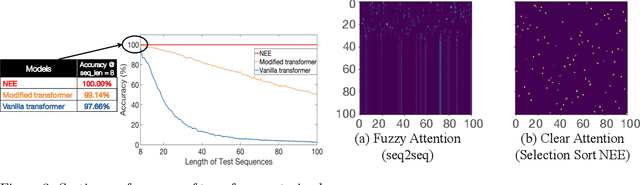
A significant effort has been made to train neural networks that replicate algorithmic reasoning, but they often fail to learn the abstract concepts underlying these algorithms. This is evidenced by their inability to generalize to data distributions that are outside of their restricted training sets, namely larger inputs and unseen data. We study these generalization issues at the level of numerical subroutines that comprise common algorithms like sorting, shortest paths, and minimum spanning trees. First, we observe that transformer-based sequence-to-sequence models can learn subroutines like sorting a list of numbers, but their performance rapidly degrades as the length of lists grows beyond those found in the training set. We demonstrate that this is due to attention weights that lose fidelity with longer sequences, particularly when the input numbers are numerically similar. To address the issue, we propose a learned conditional masking mechanism, which enables the model to strongly generalize far outside of its training range with near-perfect accuracy on a variety of algorithms. Second, to generalize to unseen data, we show that encoding numbers with a binary representation leads to embeddings with rich structure once trained on downstream tasks like addition or multiplication. This allows the embedding to handle missing data by faithfully interpolating numbers not seen during training.
Big Self-Supervised Models are Strong Semi-Supervised Learners
Jun 17, 2020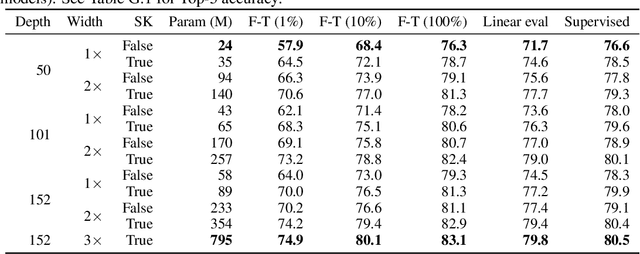
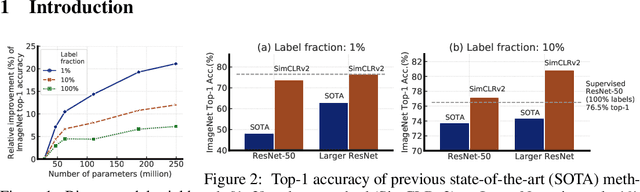
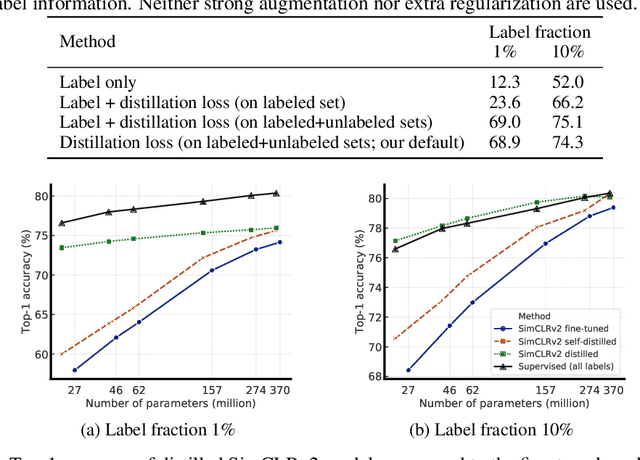
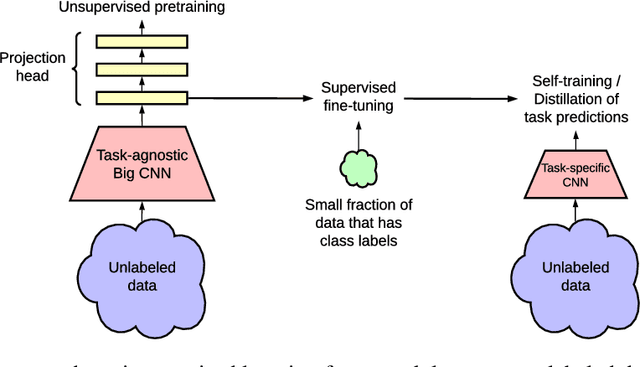
One paradigm for learning from few labeled examples while making best use of a large amount of unlabeled data is unsupervised pretraining followed by supervised fine-tuning. Although this paradigm uses unlabeled data in a task-agnostic way, in contrast to most previous approaches to semi-supervised learning for computer vision, we show that it is surprisingly effective for semi-supervised learning on ImageNet. A key ingredient of our approach is the use of a big (deep and wide) network during pretraining and fine-tuning. We find that, the fewer the labels, the more this approach (task-agnostic use of unlabeled data) benefits from a bigger network. After fine-tuning, the big network can be further improved and distilled into a much smaller one with little loss in classification accuracy by using the unlabeled examples for a second time, but in a task-specific way. The proposed semi-supervised learning algorithm can be summarized in three steps: unsupervised pretraining of a big ResNet model using SimCLRv2 (a modification of SimCLR), supervised fine-tuning on a few labeled examples, and distillation with unlabeled examples for refining and transferring the task-specific knowledge. This procedure achieves 73.9\% ImageNet top-1 accuracy with just 1\% of the labels ($\le$13 labeled images per class) using ResNet-50, a $10\times$ improvement in label efficiency over the previous state-of-the-art. With 10\% of labels, ResNet-50 trained with our method achieves 77.5\% top-1 accuracy, outperforming standard supervised training with all of the labels.
SentenceMIM: A Latent Variable Language Model
Mar 06, 2020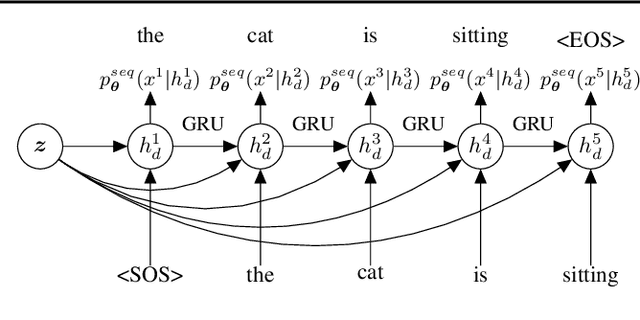
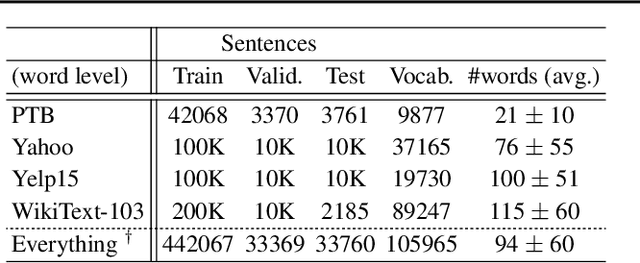

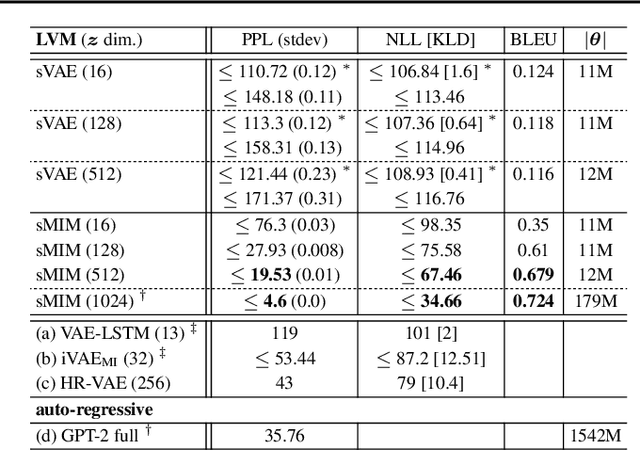
We introduce sentenceMIM, a probabilistic auto-encoder for language modelling, trained with Mutual Information Machine (MIM) learning. Previous attempts to learn variational auto-encoders for language data have had mixed success, with empirical performance well below state-of-the-art auto-regressive models, a key barrier being the occurrence of posterior collapse with VAEs. The recently proposed MIM framework encourages high mutual information between observations and latent variables, and is more robust against posterior collapse. This paper formulates a MIM model for text data, along with a corresponding learning algorithm. We demonstrate excellent perplexity (PPL) results on several datasets, and show that the framework learns a rich latent space, allowing for interpolation between sentences of different lengths with a fixed-dimensional latent representation. We also demonstrate the versatility of sentenceMIM by utilizing a trained model for question-answering, a transfer learning task, without fine-tuning. To the best of our knowledge, this is the first latent variable model (LVM) for text modelling that achieves competitive performance with non-LVM models.