 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Knee OA Severity with CNN attention-based end-to-end architectures
Aug 23, 2019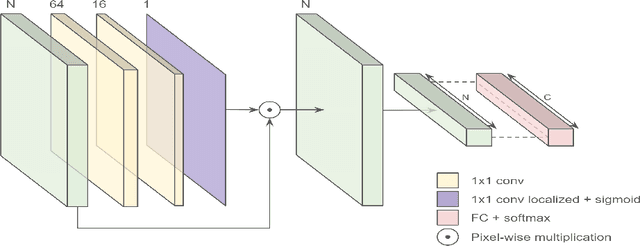
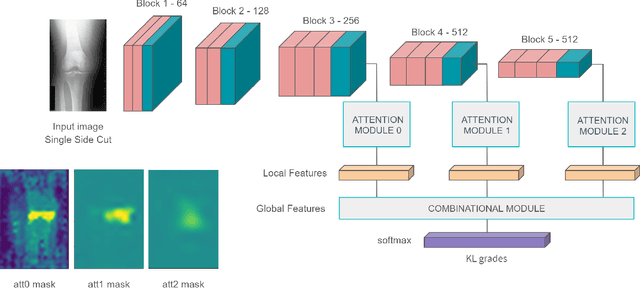

This work proposes a novel end-to-end convolutional neural network (CNN) architecture to automatically quantify the severity of knee osteoarthritis (OA) using X-Ray images, which incorporates trainable attention modules acting as unsupervised fine-grained detectors of the region of interest (ROI). The proposed attention modules can be applied at different levels and scales across any CNN pipeline helping the network to learn relevant attention patterns over the most informative parts of the image at different resolutions. We test the proposed attention mechanism on existing state-of-the-art CNN architectures as our base models, achieving promising results on the benchmark knee OA datasets from the osteoarthritis initiative (OAI) and multicenter osteoarthritis study (MOST). All code from our experiments will be publicly available on the github repository: https://github.com/marc-gorriz/KneeOA-CNNAttention
* Proceedings of the 2nd International Conference on Medical Imaging with Deep Learning
Feature Learning to Automatically Assess Radiographic Knee Osteoarthritis Severity
Aug 23, 2019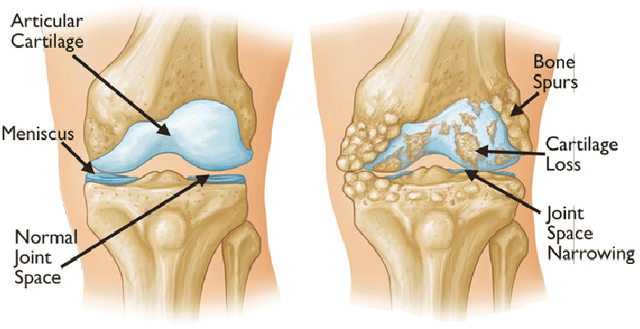
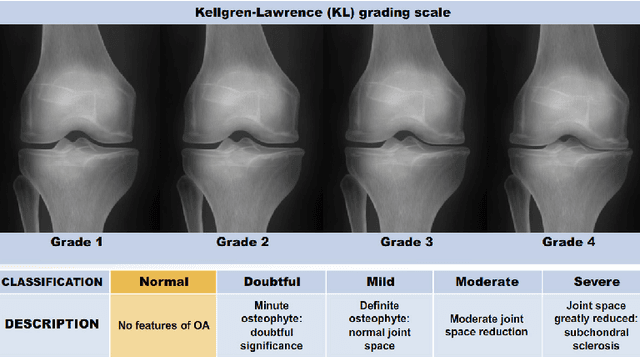
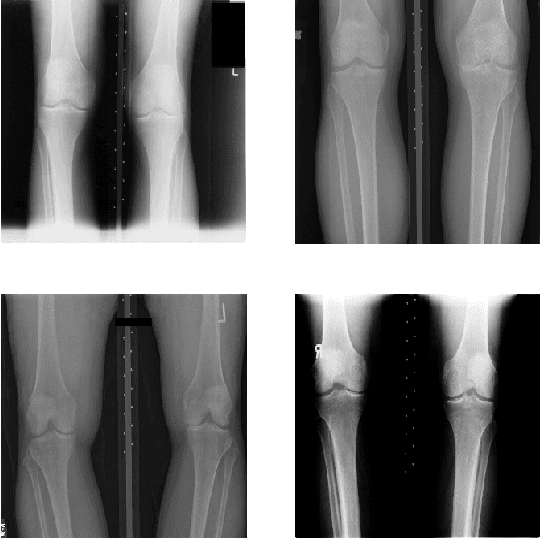
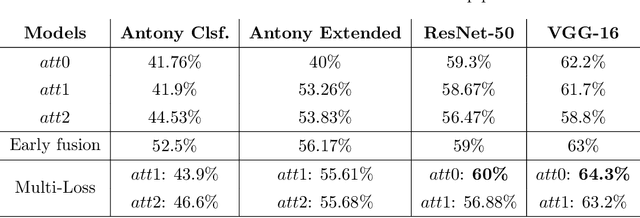
This chapter presents the investigations and the results of feature learning using convolutional neural networks to automatically assess knee osteoarthritis (OA) severity and the associated clinical and diagnostic features of knee OA from X-ray images. Also, this chapter demonstrates that feature learning in a supervised manner is more effective than using conventional handcrafted features for automatic detection of knee joints and fine-grained knee OA image classification. In the general machine learning approach to automatically assess knee OA severity, the first step is to localize the region of interest that is to detect and extract the knee joint regions from the radiographs, and the next step is to classify the localized knee joints based on a radiographic classification scheme such as Kellgren and Lawrence grades. First, the existing approaches for detecting (or localizing) the knee joint regions based on handcrafted features are reviewed and outlined. Next, three new approaches are introduced: 1) to automatically detect the knee joint region using a fully convolutional network, 2) to automatically assess the radiographic knee OA using CNNs trained from scratch for classification and regression of knee joint images to predict KL grades in ordinal and continuous scales, and 3) to quantify the knee OA severity optimizing a weighted ratio of two loss functions: categorical cross entropy and mean-squared error using multi-objective convolutional learning and ordinal regression. Two public datasets: the OAI and the MOST are used to evaluate the approaches with promising results that outperform existing approaches. In summary, this work primarily contributes to the field of automated methods for localization (automatic detection) and quantification (image classification) of radiographic knee OA.
Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning
Aug 09, 2019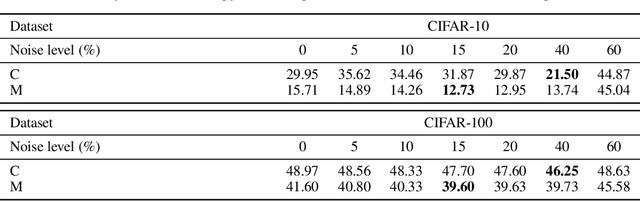
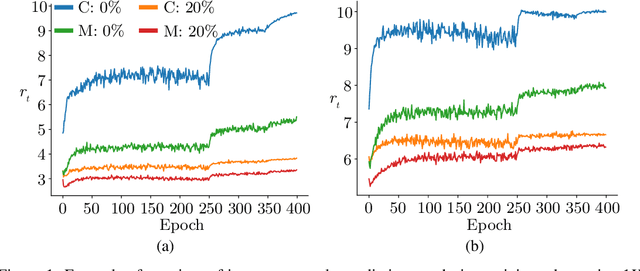
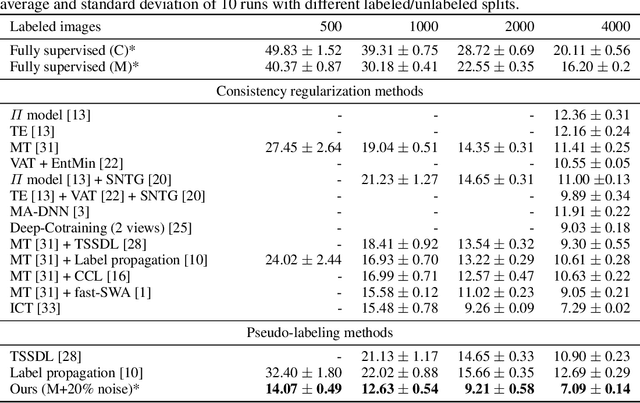
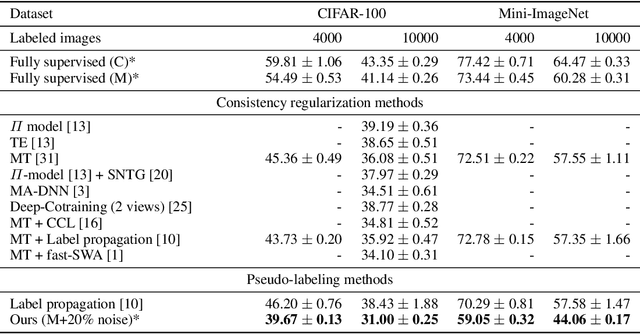
Semi-supervised learning, i.e. jointly learning from labeled an unlabeled samples, is an active research topic due to its key role on relaxing human annotation constraints. In the context of image classification, recent advances to learn from unlabeled samples are mainly focused on consistency regularization methods that encourage invariant predictions for different perturbations of unlabeled samples. We, conversely, propose to learn from unlabeled data by generating soft pseudo-labels using the network predictions. We show that a naive pseudo-labeling overfits to incorrect pseudo-labels due to the so-called confirmation bias and demonstrate that label noise and mixup augmentation are effective regularization techniques for reducing it. The proposed approach achieves state-of-the-art results in CIFAR-10/100 and Mini-Imaget despite being much simpler than other state-of-the-art. These results demonstrate that pseudo-labeling can outperform consistency regularization methods, while the opposite was supposed in previous work. Source code is available at \url{https://git.io/fjQsC}.
Simple vs complex temporal recurrences for video saliency prediction
Jul 16, 2019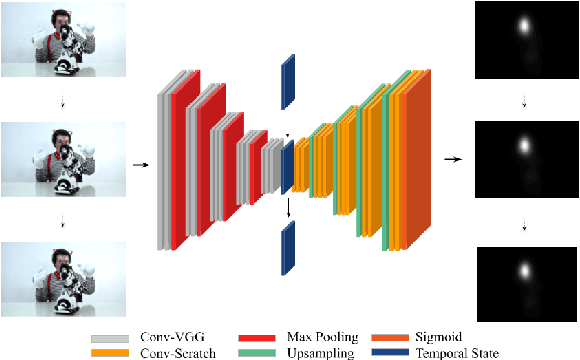
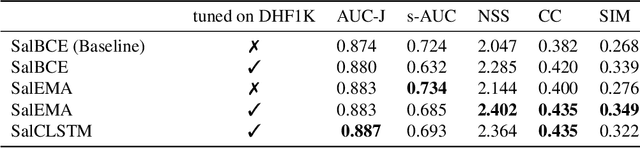
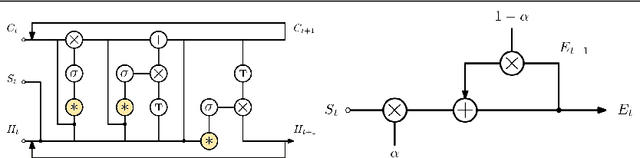
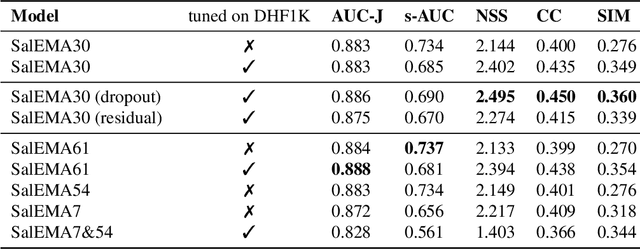
This paper investigates modifying an existing neural network architecture for static saliency prediction using two types of recurrences that integrate information from the temporal domain. The first modification is the addition of a ConvLSTM within the architecture, while the second is a conceptually simple exponential moving average of an internal convolutional state. We use weights pre-trained on the SALICON dataset and fine-tune our model on DHF1K. Our results show that both modifications achieve state-of-the-art results and produce similar saliency maps. Source code is available at https://git.io/fjPiB.
Unsupervised Label Noise Modeling and Loss Correction
Jun 05, 2019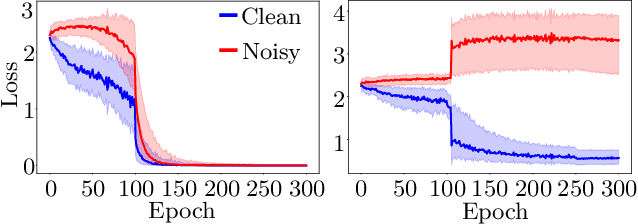
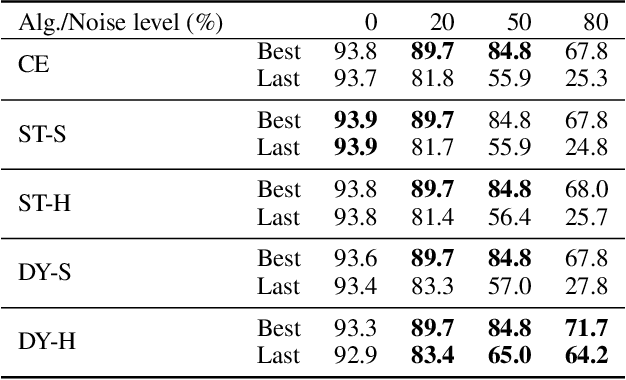
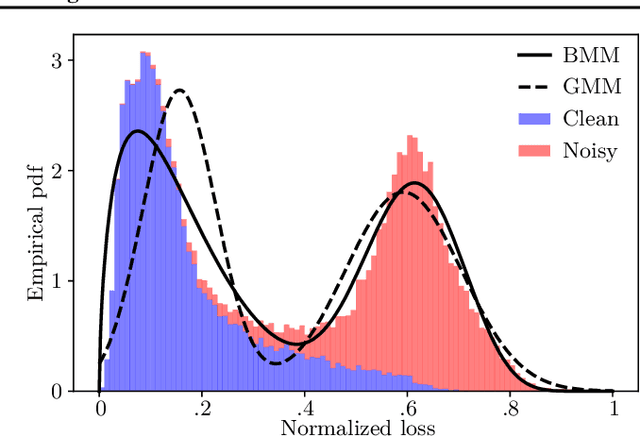
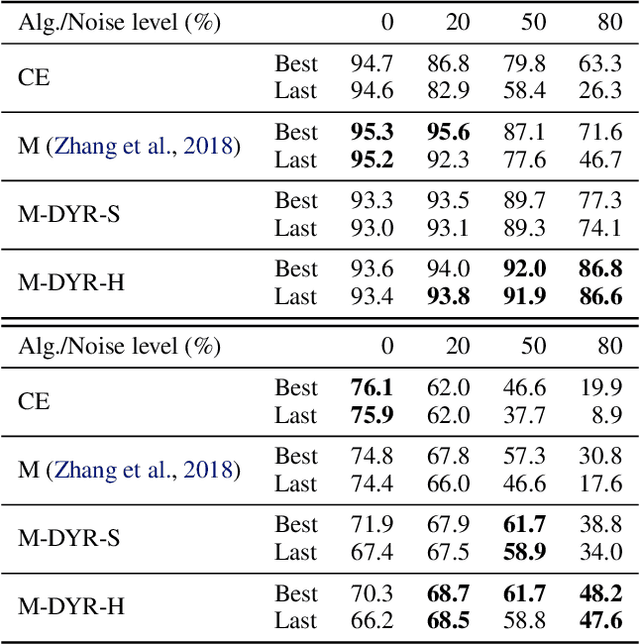
Despite being robust to small amounts of label noise, convolutional neural networks trained with stochastic gradient methods have been shown to easily fit random labels. When there are a mixture of correct and mislabelled targets, networks tend to fit the former before the latter. This suggests using a suitable two-component mixture model as an unsupervised generative model of sample loss values during training to allow online estimation of the probability that a sample is mislabelled. Specifically, we propose a beta mixture to estimate this probability and correct the loss by relying on the network prediction (the so-called bootstrapping loss). We further adapt mixup augmentation to drive our approach a step further. Experiments on CIFAR-10/100 and TinyImageNet demonstrate a robustness to label noise that substantially outperforms recent state-of-the-art. Source code is available at https://git.io/fjsvE
On guiding video object segmentation
Apr 25, 2019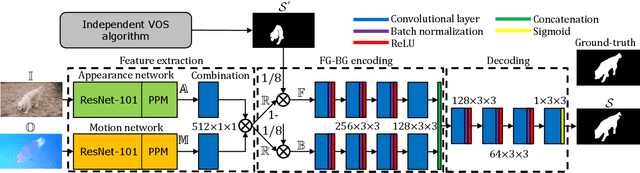
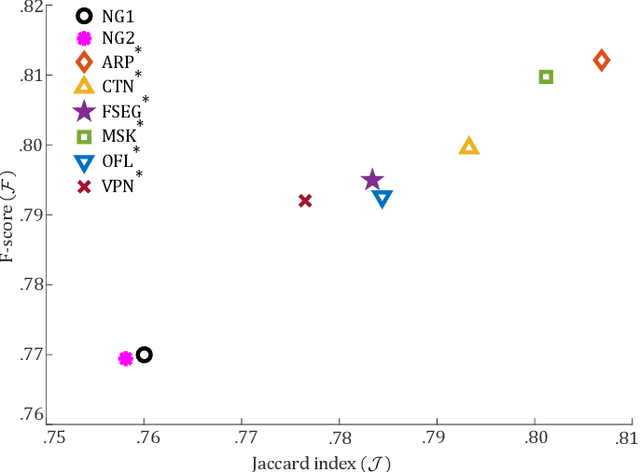

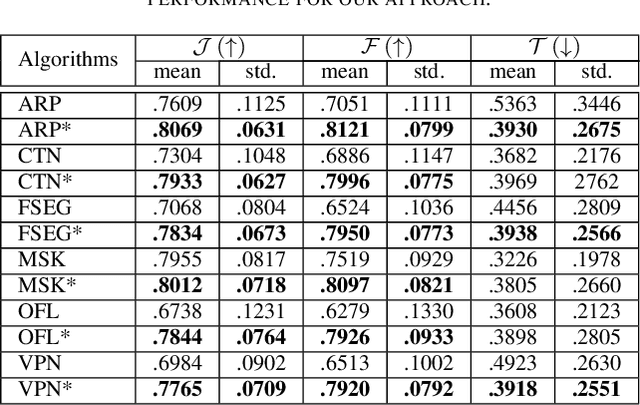
This paper presents a novel approach for segmenting moving objects in unconstrained environments using guided convolutional neural networks. This guiding process relies on foreground masks from independent algorithms (i.e. state-of-the-art algorithms) to implement an attention mechanism that incorporates the spatial location of foreground and background to compute their separated representations. Our approach initially extracts two kinds of features for each frame using colour and optical flow information. Such features are combined following a multiplicative scheme to benefit from their complementarity. These unified colour and motion features are later processed to obtain the separated foreground and background representations. Then, both independent representations are concatenated and decoded to perform foreground segmentation. Experiments conducted on the challenging DAVIS 2016 dataset demonstrate that our guided representations not only outperform non-guided, but also recent and top-performing video object segmentation algorithms.
An Efficient Approximate kNN Graph Method for Diffusion on Image Retrieval
Apr 18, 2019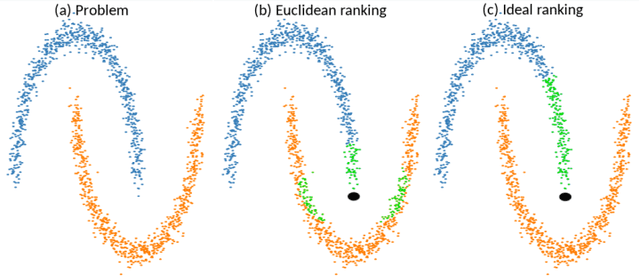
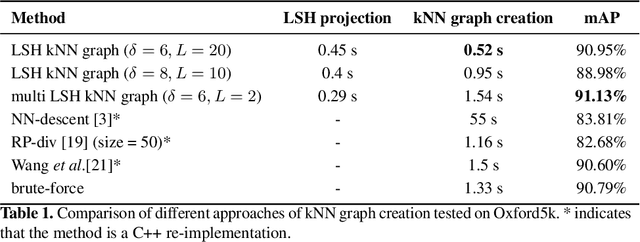
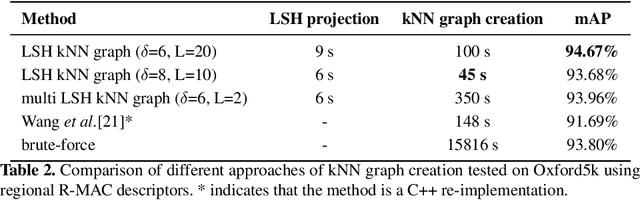

The application of the diffusion in many computer vision and artificial intelligence projects has been shown to give excellent improvements in performance. One of the main bottlenecks of this technique is the quadratic growth of the kNN graph size due to the high-quantity of new connections between nodes in the graph, resulting in long computation times. Several strategies have been proposed to address this, but none are effective and efficient. Our novel technique, based on LSH projections, obtains the same performance as the exact kNN graph after diffusion, but in less time (approximately 18 times faster on a dataset of a hundred thousand images). The proposed method was validated and compared with other state-of-the-art on several public image datasets, including Oxford5k, Paris6k, and Oxford105k.
Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
Mar 25, 2019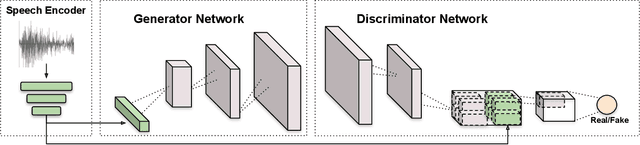


Speech is a rich biometric signal that contains information about the identity, gender and emotional state of the speaker. In this work, we explore its potential to generate face images of a speaker by conditioning a Generative Adversarial Network (GAN) with raw speech input. We propose a deep neural network that is trained from scratch in an end-to-end fashion, generating a face directly from the raw speech waveform without any additional identity information (e.g reference image or one-hot encoding). Our model is trained in a self-supervised approach by exploiting the audio and visual signals naturally aligned in videos. With the purpose of training from video data, we present a novel dataset collected for this work, with high-quality videos of youtubers with notable expressiveness in both the speech and visual signals.
PathGAN: Visual Scanpath Prediction with Generative Adversarial Networks
Sep 03, 2018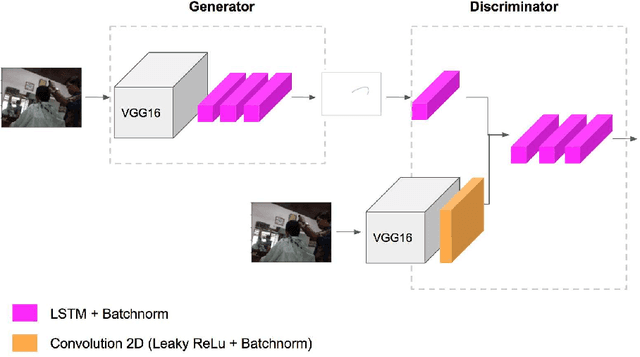

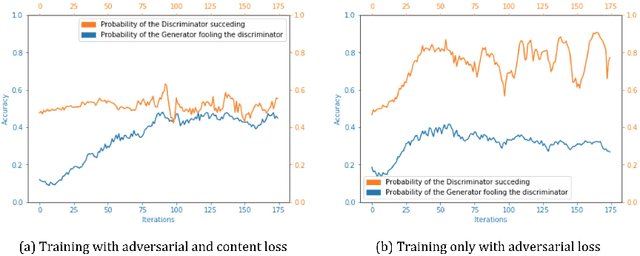
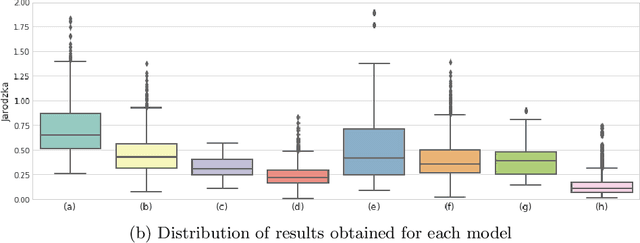
We introduce PathGAN, a deep neural network for visual scanpath prediction trained on adversarial examples. A visual scanpath is defined as the sequence of fixation points over an image defined by a human observer with its gaze. PathGAN is composed of two parts, the generator and the discriminator. Both parts extract features from images using off-the-shelf networks, and train recurrent layers to generate or discriminate scanpaths accordingly. In scanpath prediction, the stochastic nature of the data makes it very difficult to generate realistic predictions using supervised learning strategies, but we adopt adversarial training as a suitable alternative. Our experiments prove how PathGAN improves the state of the art of visual scanpath prediction on the iSUN and Salient360! datasets. Source code and models are available at https://imatge-upc.github.io/pathgan/
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
Jul 01, 2018
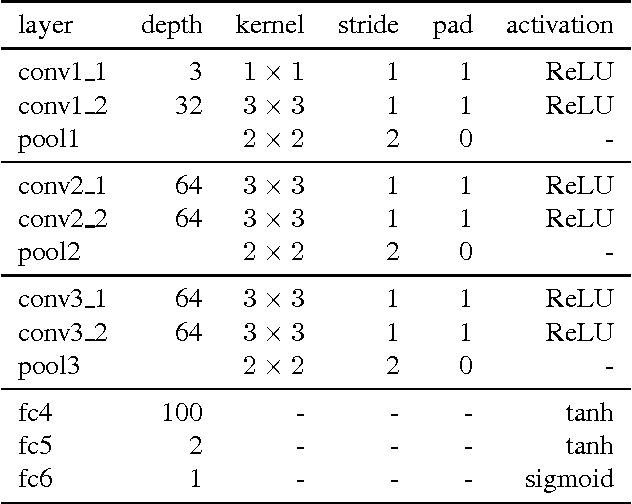
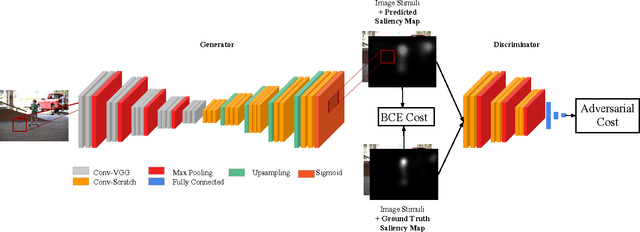
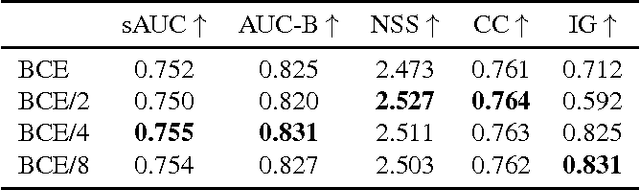
We introduce SalGAN, a deep convolutional neural network for visual saliency prediction trained with adversarial examples. The first stage of the network consists of a generator model whose weights are learned by back-propagation computed from a binary cross entropy (BCE) loss over downsampled versions of the saliency maps. The resulting prediction is processed by a discriminator network trained to solve a binary classification task between the saliency maps generated by the generative stage and the ground truth ones. Our experiments show how adversarial training allows reaching state-of-the-art performance across different metrics when combined with a widely-used loss function like BCE. Our results can be reproduced with the source code and trained models available at https://imatge-upc.github.io/saliency-salgan-2017/.