 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Paraphrase Database to Compositional Paraphrase Model and Back
Aug 26, 2015The Paraphrase Database (PPDB; Ganitkevitch et al., 2013) is an extensive semantic resource, consisting of a list of phrase pairs with (heuristic) confidence estimates. However, it is still unclear how it can best be used, due to the heuristic nature of the confidences and its necessarily incomplete coverage. We propose models to leverage the phrase pairs from the PPDB to build parametric paraphrase models that score paraphrase pairs more accurately than the PPDB's internal scores while simultaneously improving its coverage. They allow for learning phrase embeddings as well as improved word embeddings. Moreover, we introduce two new, manually annotated datasets to evaluate short-phrase paraphrasing models. Using our paraphrase model trained using PPDB, we achieve state-of-the-art results on standard word and bigram similarity tasks and beat strong baselines on our new short phrase paraphrase tasks.
* 2015 TACL paper updated with an appendix describing new 300 dimensional embeddings. Submitted 1/2015. Accepted 2/2015. Published 6/2015
Predicting the NFL using Twitter
Oct 25, 2013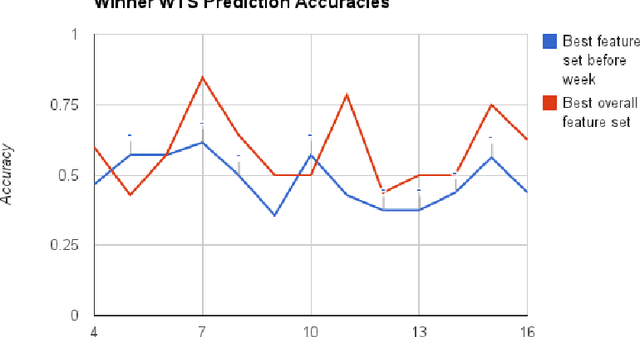
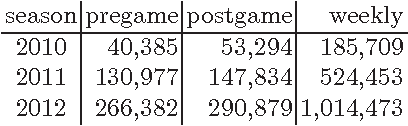
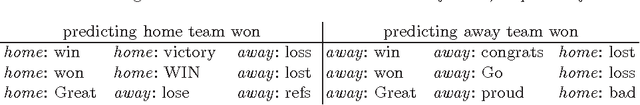
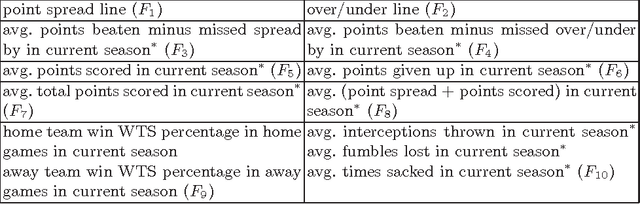
We study the relationship between social media output and National Football League (NFL) games, using a dataset containing messages from Twitter and NFL game statistics. Specifically, we consider tweets pertaining to specific teams and games in the NFL season and use them alongside statistical game data to build predictive models for future game outcomes (which team will win?) and sports betting outcomes (which team will win with the point spread? will the total points be over/under the line?). We experiment with several feature sets and find that simple features using large volumes of tweets can match or exceed the performance of more traditional features that use game statistics.