 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointVG-R: Internalizing Geometric Reasoning in MLLMs for Precise Pointing Localization via Visual Chain of Thought
Jun 23, 2026Pointing-based visual grounding requires models to precisely locate target objects by deciphering complex spatial relationships between the visual scene and pointing gestures. Traditional methods typically encode input images into static feature representations and perform reasoning primarily within the linguistic domain, often overlooking the rich perceptual cues and explicit spatial geometry inherent in images. In this study, we aim to mitigate the cognitive vulnerability of models in interpreting gestural spatial relations by proposing PointVG-R, a reasoning-guided Multi-modal Large Language Model (MLLM). PointVG-R introduces geometric-aware reasoning for pointing-based grounding, enabling the model to think with images through the strategic integration of Reinforcement Learning (RL) and cold-start data. Specifically, we design a novel geometric reasoning pipeline that simulates the iterative cognitive process humans employ when interpreting pointing gestures. Furthermore, we construct EgoPoint-CoT, a high-quality visual Chain-of-Thought (CoT) dataset featuring detailed reasoning trajectories to guide the model via Supervised Fine-Tuning (SFT) and RL. To address the varying quality of learning signals encountered during training, we further propose an Adaptive Importance Weighting strategy based on Group Variance, which dynamically adjusts reward signals to optimize the learning process. Experimental results demonstrate that PointVG-R achieves SOTA performance, outperforming the baseline by $\textbf{15.86}$ points in mIoU. Extensive ablation studies further validate the efficacy of our proposed modules. Code: https://github.com/lingli1724/PointVG-R.
From Sparse to Dense: Spatio-Temporal Fusion for Multi-View 3D Human Pose Estimation with DenseWarper
May 14, 2026In multi-view 3D human pose estimation, models typically rely on images captured simultaneously from different camera views to predict a pose at a specific moment. While providing accurate spatial information, this traditional approach often overlooks the rich temporal dependencies between adjacent frames. We propose a novel 3D human pose estimation input method: the sparse interleaved input to address this. This method leverages images captured from different camera views at various time points (e.g., View 1 at time $t$ and View 2 at time $t+δ$), allowing our model to capture rich spatio-temporal information and effectively boost performance. More importantly, this approach offers two key advantages: First, it can theoretically increase the output pose frame rate by N times with N cameras, thereby breaking through single-view frame rate limitations and enhancing the temporal resolution of the production. Second, using a sparse subset of available frames, our method can reduce data redundancy and simultaneously achieve better performance. We introduce the DenseWarper model, which leverages epipolar geometry for efficient spatio-temporal heatmap exchange. We conducted extensive experiments on the Human3.6M and MPI-INF-3DHP datasets. Results demonstrate that our method, utilizing only sparse interleaved images as input, outperforms traditional dense multi-view input approaches and achieves state-of-the-art performance. The source code for this work is available at: https://github.com/lingli1724/DenseWarper-ICLR2026
Beyond Language: Grounding Referring Expressions with Hand Pointing in Egocentric Vision
Mar 27, 2026Traditional Visual Grounding (VG) predominantly relies on textual descriptions to localize objects, a paradigm that inherently struggles with linguistic ambiguity and often ignores non-verbal deictic cues prevalent in real-world interactions. In natural egocentric engagements, hand-pointing combined with speech forms the most intuitive referring mechanism. To bridge this gap, we introduce EgoPoint-Ground, the first large-scale multimodal dataset dedicated to egocentric deictic visual grounding. Comprising over \textbf{15k} interactive samples in complex scenes, the dataset provides rich, multi-grained annotations including hand-target bounding box pairs and dense semantic captions. We establish a comprehensive benchmark for hand-pointing referring expression resolution, evaluating a wide spectrum of mainstream Multimodal Large Language Models (MLLMs) and state-of-the-art VG architectures. Furthermore, we propose SV-CoT, a novel baseline framework that reformulates grounding as a structured inference process, synergizing gestural and linguistic cues through a Visual Chain-of-Thought paradigm. Extensive experiments demonstrate that SV-CoT achieves an $\textbf{11.7\%}$ absolute improvement over existing methods, effectively mitigating semantic ambiguity and advancing the capability of agents to comprehend multimodal physical intents. The dataset and code will be made publicly available.
Interactive Search Based on Deep Reinforcement Learning
Dec 09, 2020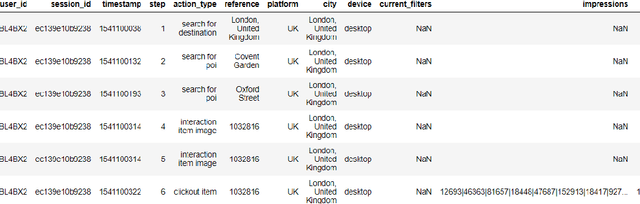

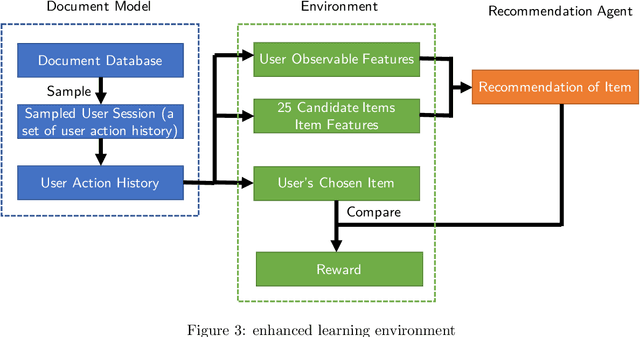
With the continuous development of machine learning technology, major e-commerce platforms have launched recommendation systems based on it to serve a large number of customers with different needs more efficiently. Compared with traditional supervised learning, reinforcement learning can better capture the user's state transition in the decision-making process, and consider a series of user actions, not just the static characteristics of the user at a certain moment. In theory, it will have a long-term perspective, producing a more effective recommendation. The special requirements of reinforcement learning for data make it need to rely on an offline virtual system for training. Our project mainly establishes a virtual user environment for offline training. At the same time, we tried to improve a reinforcement learning algorithm based on bi-clustering to expand the action space and recommended path space of the recommendation agent.