 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Cross Lingual Pivots to Model Pronoun Gender for Translation
Jun 16, 2020


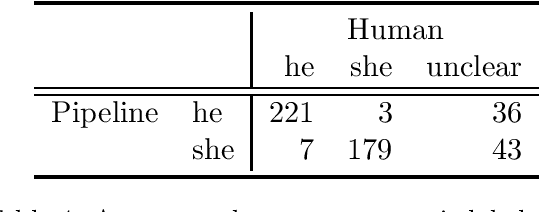
Machine translation systems with inadequate document understanding can make errors when translating dropped or neutral pronouns into languages with gendered pronouns (e.g., English). Predicting the underlying gender of these pronouns is difficult since it is not marked textually and must instead be inferred from coreferent mentions in the context. We propose a novel cross-lingual pivoting technique for automatically producing high-quality gender labels, and show that this data can be used to fine-tune a BERT classifier with 92% F1 for Spanish dropped feminine pronouns, compared with 30-51% for neural machine translation models and 54-71% for a non-fine-tuned BERT model. We augment a neural machine translation model with labels from our classifier to improve pronoun translation, while still having parallelizable translation models that translate a sentence at a time.
Social Biases in NLP Models as Barriers for Persons with Disabilities
May 02, 2020
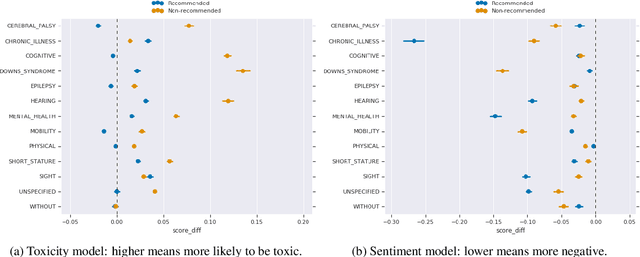
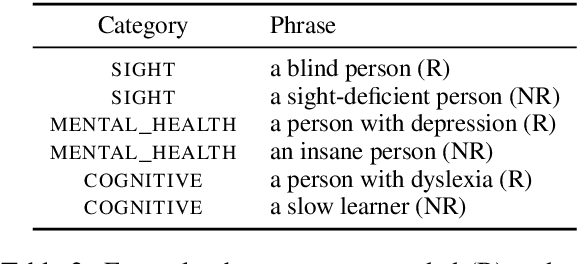
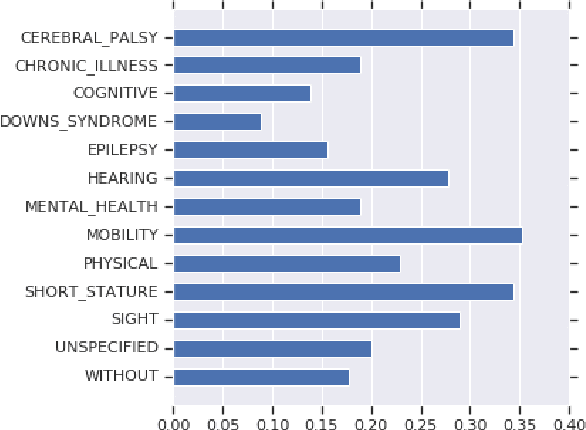
Building equitable and inclusive NLP technologies demands consideration of whether and how social attitudes are represented in ML models. In particular, representations encoded in models often inadvertently perpetuate undesirable social biases from the data on which they are trained. In this paper, we present evidence of such undesirable biases towards mentions of disability in two different English language models: toxicity prediction and sentiment analysis. Next, we demonstrate that the neural embeddings that are the critical first step in most NLP pipelines similarly contain undesirable biases towards mentions of disability. We end by highlighting topical biases in the discourse about disability which may contribute to the observed model biases; for instance, gun violence, homelessness, and drug addiction are over-represented in texts discussing mental illness.
* ACL 2020 short paper. 5 pages
Automatically Identifying Gender Issues in Machine Translation using Perturbations
Apr 29, 2020


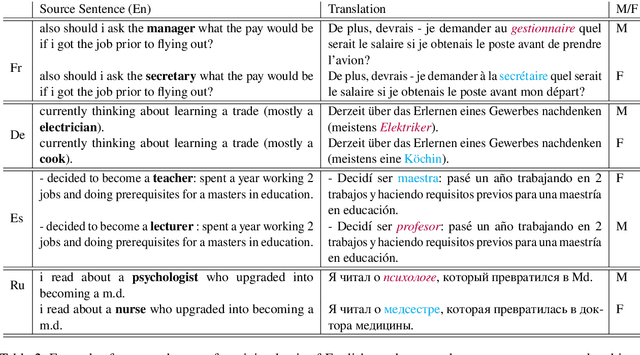
The successful application of neural methods to machine translation has realized huge quality advances for the community. With these improvements, many have noted outstanding challenges, including the modeling and treatment of gendered language. Where previous studies have identified concerns using manually-curated synthetic examples, we develop a novel technique to leverage real world data to explore challenges for deployed systems. We use our new method to compile an evaluation benchmark spanning examples relating to four languages from three language families, which we will publicly release to facilitate research. The examples in our benchmark expose the ways in which gender is represented in a model and the unintended consequences these gendered representations can have in downstream applications.
Mind the GAP: A Balanced Corpus of Gendered Ambiguous Pronouns
Oct 11, 2018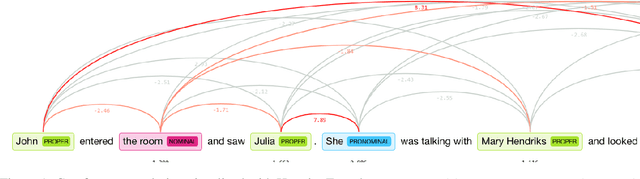
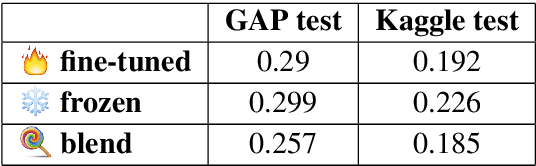


Coreference resolution is an important task for natural language understanding, and the resolution of ambiguous pronouns a longstanding challenge. Nonetheless, existing corpora do not capture ambiguous pronouns in sufficient volume or diversity to accurately indicate the practical utility of models. Furthermore, we find gender bias in existing corpora and systems favoring masculine entities. To address this, we present and release GAP, a gender-balanced labeled corpus of 8,908 ambiguous pronoun-name pairs sampled to provide diverse coverage of challenges posed by real-world text. We explore a range of baselines which demonstrate the complexity of the challenge, the best achieving just 66.9% F1. We show that syntactic structure and continuous neural models provide promising, complementary cues for approaching the challenge.