 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemHalDet: Robust VLM Hallucination Detection via Ensemble of Internal State Detectors
Apr 03, 2026Vision-Language Models (VLMs) excel at multimodal tasks, but they remain vulnerable to hallucinations that are factually incorrect or ungrounded in the input image. Recent work suggests that hallucination detection using internal representations is more efficient and accurate than approaches that rely solely on model outputs. However, existing internal-representation-based methods typically rely on a single representation or detector, limiting their ability to capture diverse hallucination signals. In this paper, we propose EnsemHalDet, an ensemble-based hallucination detection framework that leverages multiple internal representations of VLMs, including attention outputs and hidden states. EnsemHalDet trains independent detectors for each representation and combines them through ensemble learning. Experimental results across multiple VQA datasets and VLMs show that EnsemHalDet consistently outperforms prior methods and single-detector models in terms of AUC. These results demonstrate that ensembling diverse internal signals significantly improves robustness in multimodal hallucination detection.
BookAsSumQA: An Evaluation Framework for Aspect-Based Book Summarization via Question Answering
Nov 09, 2025



Aspect-based summarization aims to generate summaries that highlight specific aspects of a text, enabling more personalized and targeted summaries. However, its application to books remains unexplored due to the difficulty of constructing reference summaries for long text. To address this challenge, we propose BookAsSumQA, a QA-based evaluation framework for aspect-based book summarization. BookAsSumQA automatically generates aspect-specific QA pairs from a narrative knowledge graph to evaluate summary quality based on its question-answering performance. Our experiments using BookAsSumQA revealed that while LLM-based approaches showed higher accuracy on shorter texts, RAG-based methods become more effective as document length increases, making them more efficient and practical for aspect-based book summarization.
Estimation of Fireproof Structure Class and Construction Year for Disaster Risk Assessment
Oct 26, 2025Structural fireproof classification is vital for disaster risk assessment and insurance pricing in Japan. However, key building metadata such as construction year and structure type are often missing or outdated, particularly in the second-hand housing market. This study proposes a multi-task learning model that predicts these attributes from facade images. The model jointly estimates the construction year, building structure, and property type, from which the structural fireproof class - defined as H (non-fireproof), T (semi-fireproof), or M (fireproof) - is derived via a rule-based mapping based on official insurance criteria. We trained and evaluated the model using a large-scale dataset of Japanese residential images, applying rigorous filtering and deduplication. The model achieved high accuracy in construction-year regression and robust classification across imbalanced categories. Qualitative analyses show that it captures visual cues related to building age and materials. Our approach demonstrates the feasibility of scalable, interpretable, image-based risk-profiling systems, offering potential applications in insurance, urban planning, and disaster preparedness.
Generation and annotation of item usage scenarios in e-commerce using large language models
Oct 09, 2025Complementary recommendations suggest combinations of useful items that play important roles in e-commerce. However, complementary relationships are often subjective and vary among individuals, making them difficult to infer from historical data. Unlike conventional history-based methods that rely on statistical co-occurrence, we focus on the underlying usage context that motivates item combinations. We hypothesized that people select complementary items by imagining specific usage scenarios and identifying the needs in such situations. Based on this idea, we explored the use of large language models (LLMs) to generate item usage scenarios as a starting point for constructing complementary recommendation systems. First, we evaluated the plausibility of LLM-generated scenarios through manual annotation. The results demonstrated that approximately 85% of the generated scenarios were determined to be plausible, suggesting that LLMs can effectively generate realistic item usage scenarios.
A Universal Framework for Offline Serendipity Evaluation in Recommender Systems via Large Language Models
Aug 25, 2025Serendipity in recommender systems (RSs) has attracted increasing attention as a concept that enhances user satisfaction by presenting unexpected and useful items. However, evaluating serendipitous performance remains challenging because its ground truth is generally unobservable. The existing offline metrics often depend on ambiguous definitions or are tailored to specific datasets and RSs, thereby limiting their generalizability. To address this issue, we propose a universally applicable evaluation framework that leverages large language models (LLMs) known for their extensive knowledge and reasoning capabilities, as evaluators. First, to improve the evaluation performance of the proposed framework, we assessed the serendipity prediction accuracy of LLMs using four different prompt strategies on a dataset containing user-annotated serendipitous ground truth and found that the chain-of-thought prompt achieved the highest accuracy. Next, we re-evaluated the serendipitous performance of both serendipity-oriented and general RSs using the proposed framework on three commonly used real-world datasets, without the ground truth. The results indicated that there was no serendipity-oriented RS that consistently outperformed across all datasets, and even a general RS sometimes achieved higher performance than the serendipity-oriented RS.
A Completely Locale-independent Session-based Recommender System by Leveraging Trained Model
Oct 11, 2023



In this paper, we propose a solution that won the 10th prize in the KDD Cup 2023 Challenge Task 2 (Next Product Recommendation for Underrepresented Languages/Locales). Our approach involves two steps: (i) Identify candidate item sets based on co-visitation, and (ii) Re-ranking the items using LightGBM with locale-independent features, including session-based features and product similarity. The experiment demonstrated that the locale-independent model performed consistently well across different test locales, and performed even better when incorporating data from other locales into the training.
AIREX: Neural Network-based Approach for Air Quality Inference in Unmonitored Cities
Aug 16, 2021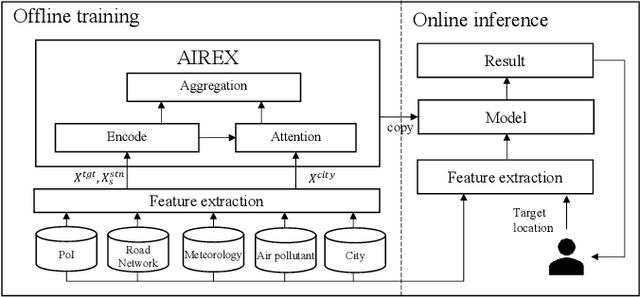
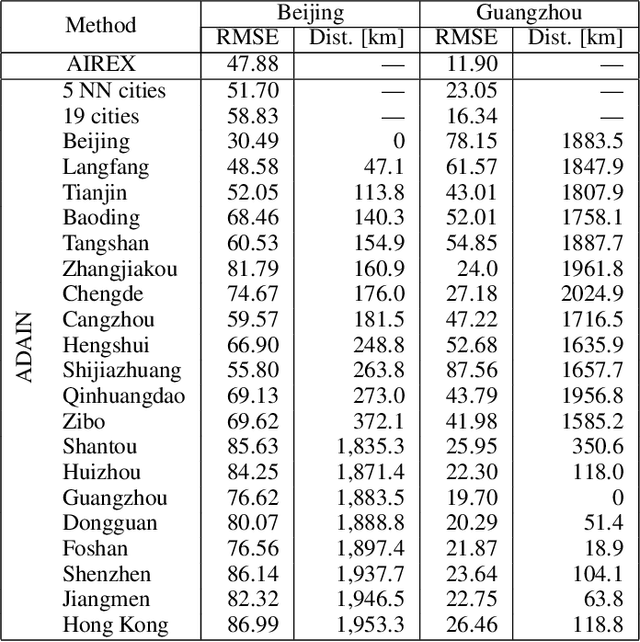
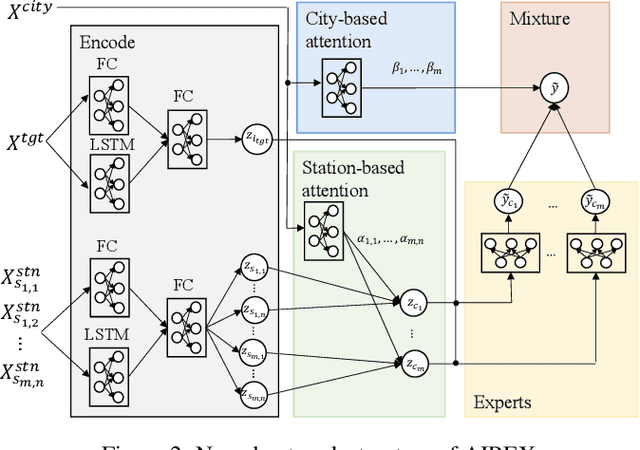
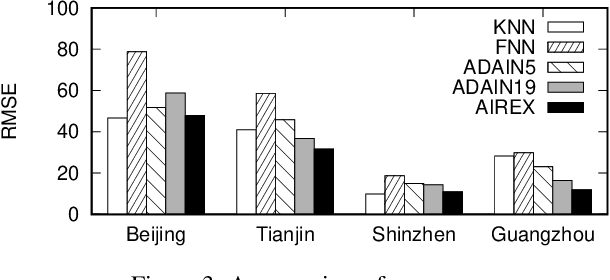
Urban air pollution is a major environmental problem affecting human health and quality of life. Monitoring stations have been established to continuously obtain air quality information, but they do not cover all areas. Thus, there are numerous methods for spatially fine-grained air quality inference. Since existing methods aim to infer air quality of locations only in monitored cities, they do not assume inferring air quality in unmonitored cities. In this paper, we first study the air quality inference in unmonitored cities. To accurately infer air quality in unmonitored cities, we propose a neural network-based approach AIREX. The novelty of AIREX is employing a mixture-of-experts approach, which is a machine learning technique based on the divide-and-conquer principle, to learn correlations of air quality between multiple cities. To further boost the performance, it employs attention mechanisms to compute impacts of air quality inference from the monitored cities to the locations in the unmonitored city. We show, through experiments on a real-world air quality dataset, that AIREX achieves higher accuracy than state-of-the-art methods.