 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's all In the (Exponential) Family: An Equivalence between Maximum Likelihood Estimation and Control Variates for Sketching Algorithms
Feb 04, 2026Maximum likelihood estimators (MLE) and control variate estimators (CVE) have been used in conjunction with known information across sketching algorithms and applications in machine learning. We prove that under certain conditions in an exponential family, an optimal CVE will achieve the same asymptotic variance as the MLE, giving an Expectation-Maximization (EM) algorithm for the MLE. Experiments show the EM algorithm is faster and numerically stable compared to other root finding algorithms for the MLE for the bivariate Normal distribution, and we expect this to hold across distributions satisfying these conditions. We show how the EM algorithm leads to reproducibility for algorithms using MLE / CVE, and demonstrate how the EM algorithm leads to finding the MLE when the CV weights are known.
It's all the (Exponential) Family: An Equivalence between Maximum Likelihood Estimation and Control Variates for Sketching Algorithms
Jan 29, 2026Maximum likelihood estimators (MLE) and control variate estimators (CVE) have been used in conjunction with known information across sketching algorithms and applications in machine learning. We prove that under certain conditions in an exponential family, an optimal CVE will achieve the same asymptotic variance as the MLE, giving an Expectation-Maximization (EM) algorithm for the MLE. Experiments show the EM algorithm is faster and numerically stable compared to other root finding algorithms for the MLE for the bivariate Normal distribution, and we expect this to hold across distributions satisfying these conditions. We show how the EM algorithm leads to reproducibility for algorithms using MLE / CVE, and demonstrate how the EM algorithm leads to finding the MLE when the CV weights are known.
Feature Representation in Convolutional Neural Networks
Jul 08, 2015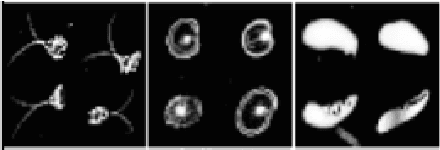
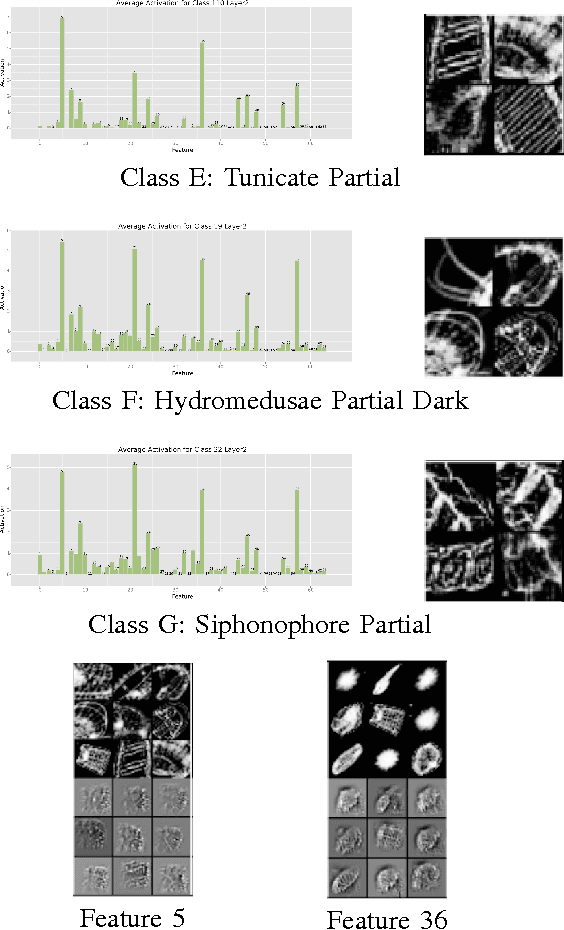
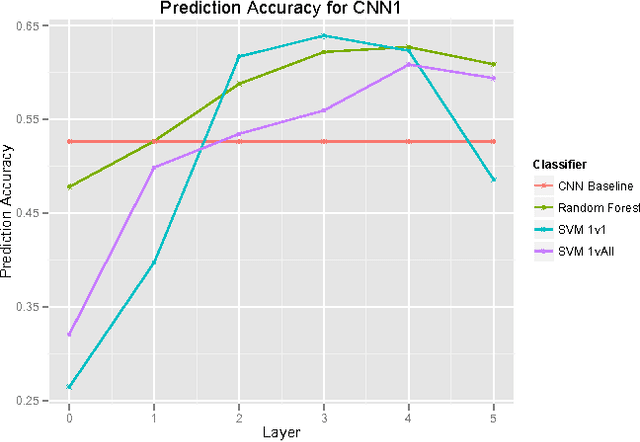
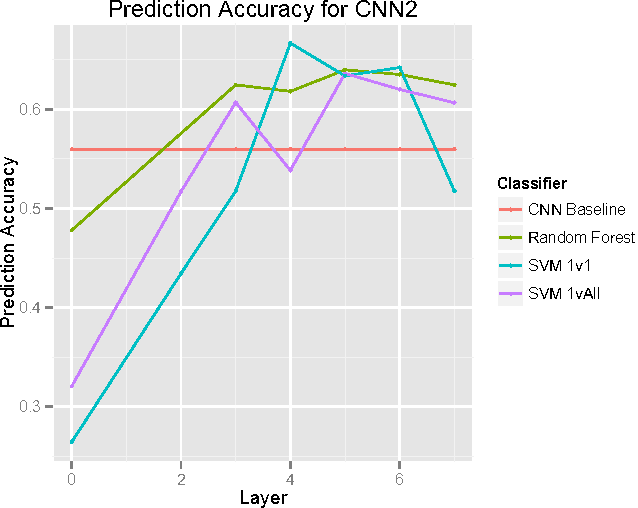
Convolutional Neural Networks (CNNs) are powerful models that achieve impressive results for image classification. In addition, pre-trained CNNs are also useful for other computer vision tasks as generic feature extractors. This paper aims to gain insight into the feature aspect of CNN and demonstrate other uses of CNN features. Our results show that CNN feature maps can be used with Random Forests and SVM to yield classification results that outperforms the original CNN. A CNN that is less than optimal (e.g. not fully trained or overfitting) can also extract features for Random Forest/SVM that yield competitive classification accuracy. In contrast to the literature which uses the top-layer activations as feature representation of images for other tasks, using lower-layer features can yield better results for classification.