 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Hate Speech with GPT-3
Mar 23, 2021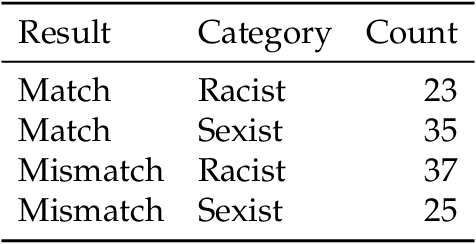
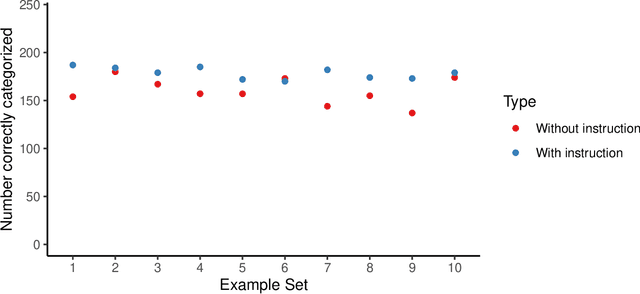

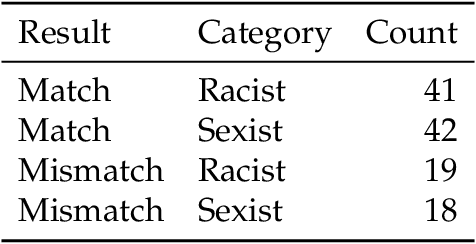
Sophisticated language models such as OpenAI's GPT-3 can generate hateful text that targets marginalized groups. Given this capacity, we are interested in whether large language models can be used to identify hate speech and classify text as sexist or racist? We use GPT-3 to identify sexist and racist text passages with zero-, one-, and few-shot learning. We find that with zero- and one-shot learning, GPT-3 is able to identify sexist or racist text with an accuracy between 48 per cent and 69 per cent. With few-shot learning and an instruction included in the prompt, the model's accuracy can be as high as 78 per cent. We conclude that large language models have a role to play in hate speech detection, and that with further development language models could be used to counter hate speech and even self-police.
On consistency scores in text data with an implementation in R
Jan 13, 2021In this paper, we introduce a reproducible cleaning process for the text extracted from PDFs using n-gram models. Our approach compares the originally extracted text with the text generated from, or expected by, these models using earlier text as stimulus. To guide this process, we introduce the notion of a consistency score, which refers to the proportion of text that is expected by the model. This is used to monitor changes during the cleaning process, and across different corpuses. We illustrate our process on text from the book Jane Eyre and introduce both a Shiny application and an R package to make our process easier for others to adopt.