 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4 for Occlusion Order Recovery
Sep 26, 2025Occlusion remains a significant challenge for current vision models to robustly interpret complex and dense real-world images and scenes. To address this limitation and to enable accurate prediction of the occlusion order relationship between objects, we propose leveraging the advanced capability of a pre-trained GPT-4 model to deduce the order. By providing a specifically designed prompt along with the input image, GPT-4 can analyze the image and generate order predictions. The response can then be parsed to construct an occlusion matrix which can be utilized in assisting with other occlusion handling tasks and image understanding. We report the results of evaluating the model on COCOA and InstaOrder datasets. The results show that by using semantic context, visual patterns, and commonsense knowledge, the model can produce more accurate order predictions. Unlike baseline methods, the model can reason about occlusion relationships in a zero-shot fashion, which requires no annotated training data and can easily be integrated into occlusion handling frameworks.
Mask Guided Gated Convolution for Amodal Content Completion
Jul 21, 2024



We present a model to reconstruct partially visible objects. The model takes a mask as an input, which we call weighted mask. The mask is utilized by gated convolutions to assign more weight to the visible pixels of the occluded instance compared to the background, while ignoring the features of the invisible pixels. By drawing more attention from the visible region, our model can predict the invisible patch more effectively than the baseline models, especially in instances with uniform texture. The model is trained on COCOA dataset and two subsets of it in a self-supervised manner. The results demonstrate that our model generates higher quality and more texture-rich outputs compared to baseline models. Code is available at: https://github.com/KaziwaSaleh/mask-guided.
BBBD: Bounding Box Based Detector for Occlusion Detection and Order Recovery
Apr 27, 2022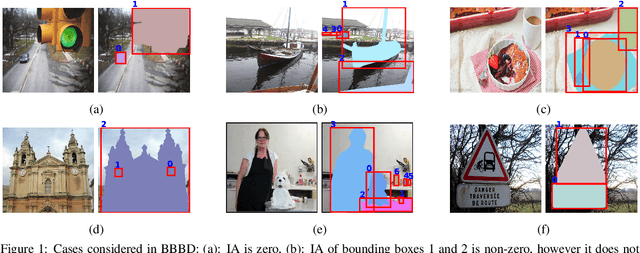
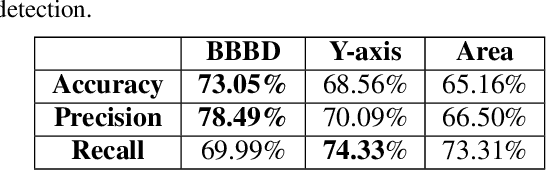
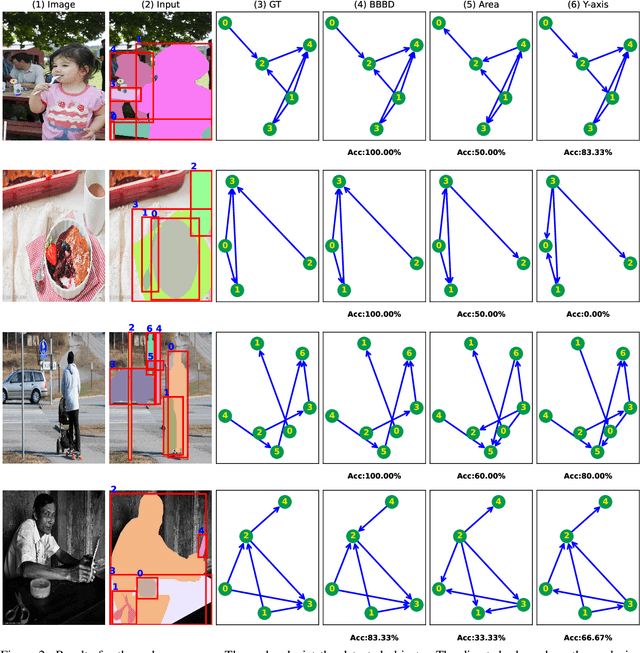
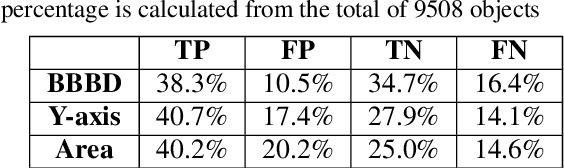
Occlusion handling is one of the challenges of object detection and segmentation, and scene understanding. Because objects appear differently when they are occluded in varying degree, angle, and locations. Therefore, determining the existence of occlusion between objects and their order in a scene is a fundamental requirement for semantic understanding. Existing works mostly use deep learning based models to retrieve the order of the instances in an image or for occlusion detection. This requires labelled occluded data and it is time consuming. In this paper, we propose a simpler and faster method that can perform both operations without any training and only requires the modal segmentation masks. For occlusion detection, instead of scanning the two objects entirely, we only focus on the intersected area between their bounding boxes. Similarly, we use the segmentation mask inside the same area to recover the depth-ordering. When tested on COCOA dataset, our method achieves +8% and +5% more accuracy than the baselines in order recovery and occlusion detection respectively.
* 7 pages, 4 figures
Occlusion Handling in Generic Object Detection: A Review
Jan 21, 2021


The significant power of deep learning networks has led to enormous development in object detection. Over the last few years, object detector frameworks have achieved tremendous success in both accuracy and efficiency. However, their ability is far from that of human beings due to several factors, occlusion being one of them. Since occlusion can happen in various locations, scale, and ratio, it is very difficult to handle. In this paper, we address the challenges in occlusion handling in generic object detection in both outdoor and indoor scenes, then we refer to the recent works that have been carried out to overcome these challenges. Finally, we discuss some possible future directions of research.