 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLakeFM: Toward a Foundation Model for Aquatic Ecosystems Using Irregular Multivariate Multi-depth Time Series Data
Jun 09, 2026Understanding and forecasting lake dynamics is critical for monitoring water quality and ecosystem health across lakes and reservoirs. While machine learning methods have been recently applied to ecological time-series data, existing works assume regular sampling in time and depth, and struggle to generalize across lakes with heterogeneous variables, depths, and observation patterns. To address these limitations, we introduce \textsc{LakeFM}, a foundation model for aquatic systems, pre-trained on large-scale ecological datasets comprising both simulated and observed lakes. Through extensive empirical evaluation, we show that \textsc{LakeFM} learns meaningful representations spanning broader lake-level characteristics, and achieves competitive or often superior-forecasting performance compared to existing time-series foundation and non-foundation models, while producing physically plausible predictions consistent with real-world lake dynamics.
Open World Scene Graph Generation using Vision Language Models
Jun 09, 2025



Scene-Graph Generation (SGG) seeks to recognize objects in an image and distill their salient pairwise relationships. Most methods depend on dataset-specific supervision to learn the variety of interactions, restricting their usefulness in open-world settings, involving novel objects and/or relations. Even methods that leverage large Vision Language Models (VLMs) typically require benchmark-specific fine-tuning. We introduce Open-World SGG, a training-free, efficient, model-agnostic framework that taps directly into the pretrained knowledge of VLMs to produce scene graphs with zero additional learning. Casting SGG as a zero-shot structured-reasoning problem, our method combines multimodal prompting, embedding alignment, and a lightweight pair-refinement strategy, enabling inference over unseen object vocabularies and relation sets. To assess this setting, we formalize an Open-World evaluation protocol that measures performance when no SGG-specific data have been observed either in terms of objects and relations. Experiments on Visual Genome, Open Images V6, and the Panoptic Scene Graph (PSG) dataset demonstrate the capacity of pretrained VLMs to perform relational understanding without task-level training.
Prompt-CAM: A Simpler Interpretable Transformer for Fine-Grained Analysis
Jan 16, 2025



We present a simple usage of pre-trained Vision Transformers (ViTs) for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as different bird species or dog breeds. Pre-trained ViTs such as DINO have shown remarkable capabilities to extract localized, informative features. However, using saliency maps like Grad-CAM can hardly point out the traits: they often locate the whole object by a blurred, coarse heatmap, not traits. We propose a novel approach Prompt Class Attention Map (Prompt-CAM) to the rescue. Prompt-CAM learns class-specific prompts to a pre-trained ViT and uses the corresponding outputs for classification. To classify an image correctly, the true-class prompt must attend to the unique image patches not seen in other classes' images, i.e., traits. As such, the true class's multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a free lunch by simply modifying the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM fairly easy to train and apply, sharply contrasting other interpretable methods that design specific models and training processes. It is even simpler than the recently published INterpretable TRansformer (INTR), whose encoder-decoder architecture prevents it from leveraging pre-trained ViTs. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate Prompt-CAM superior interpretation capability.
What Do You See in Common? Learning Hierarchical Prototypes over Tree-of-Life to Discover Evolutionary Traits
Sep 03, 2024



A grand challenge in biology is to discover evolutionary traits - features of organisms common to a group of species with a shared ancestor in the tree of life (also referred to as phylogenetic tree). With the growing availability of image repositories in biology, there is a tremendous opportunity to discover evolutionary traits directly from images in the form of a hierarchy of prototypes. However, current prototype-based methods are mostly designed to operate over a flat structure of classes and face several challenges in discovering hierarchical prototypes, including the issue of learning over-specific features at internal nodes. To overcome these challenges, we introduce the framework of Hierarchy aligned Commonality through Prototypical Networks (HComP-Net). We empirically show that HComP-Net learns prototypes that are accurate, semantically consistent, and generalizable to unseen species in comparison to baselines on birds, butterflies, and fishes datasets. The code and datasets are available at https://github.com/Imageomics/HComPNet.
VLM4Bio: A Benchmark Dataset to Evaluate Pretrained Vision-Language Models for Trait Discovery from Biological Images
Aug 28, 2024



Images are increasingly becoming the currency for documenting biodiversity on the planet, providing novel opportunities for accelerating scientific discoveries in the field of organismal biology, especially with the advent of large vision-language models (VLMs). We ask if pre-trained VLMs can aid scientists in answering a range of biologically relevant questions without any additional fine-tuning. In this paper, we evaluate the effectiveness of 12 state-of-the-art (SOTA) VLMs in the field of organismal biology using a novel dataset, VLM4Bio, consisting of 469K question-answer pairs involving 30K images from three groups of organisms: fishes, birds, and butterflies, covering five biologically relevant tasks. We also explore the effects of applying prompting techniques and tests for reasoning hallucination on the performance of VLMs, shedding new light on the capabilities of current SOTA VLMs in answering biologically relevant questions using images. The code and datasets for running all the analyses reported in this paper can be found at https://github.com/sammarfy/VLM4Bio.
Fish-Vista: A Multi-Purpose Dataset for Understanding & Identification of Traits from Images
Jul 10, 2024



Fishes are integral to both ecological systems and economic sectors, and studying fish traits is crucial for understanding biodiversity patterns and macro-evolution trends. To enable the analysis of visual traits from fish images, we introduce the Fish-Visual Trait Analysis (Fish-Vista) dataset - a large, annotated collection of about 60K fish images spanning 1900 different species, supporting several challenging and biologically relevant tasks including species classification, trait identification, and trait segmentation. These images have been curated through a sophisticated data processing pipeline applied to a cumulative set of images obtained from various museum collections. Fish-Vista provides fine-grained labels of various visual traits present in each image. It also offers pixel-level annotations of 9 different traits for 2427 fish images, facilitating additional trait segmentation and localization tasks. The ultimate goal of Fish-Vista is to provide a clean, carefully curated, high-resolution dataset that can serve as a foundation for accelerating biological discoveries using advances in AI. Finally, we provide a comprehensive analysis of state-of-the-art deep learning techniques on Fish-Vista.
Let There Be Order: Rethinking Ordering in Autoregressive Graph Generation
May 24, 2023



Conditional graph generation tasks involve training a model to generate a graph given a set of input conditions. Many previous studies employ autoregressive models to incrementally generate graph components such as nodes and edges. However, as graphs typically lack a natural ordering among their components, converting a graph into a sequence of tokens is not straightforward. While prior works mostly rely on conventional heuristics or graph traversal methods like breadth-first search (BFS) or depth-first search (DFS) to convert graphs to sequences, the impact of ordering on graph generation has largely been unexplored. This paper contributes to this problem by: (1) highlighting the crucial role of ordering in autoregressive graph generation models, (2) proposing a novel theoretical framework that perceives ordering as a dimensionality reduction problem, thereby facilitating a deeper understanding of the relationship between orderings and generated graph accuracy, and (3) introducing "latent sort," a learning-based ordering scheme to perform dimensionality reduction of graph tokens. Our experimental results showcase the effectiveness of latent sort across a wide range of graph generation tasks, encouraging future works to further explore and develop learning-based ordering schemes for autoregressive graph generation.
CoDesc: A Large Code-Description Parallel Dataset
May 29, 2021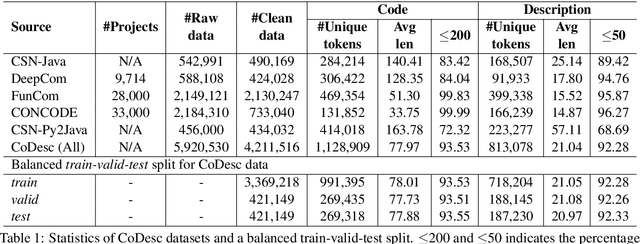
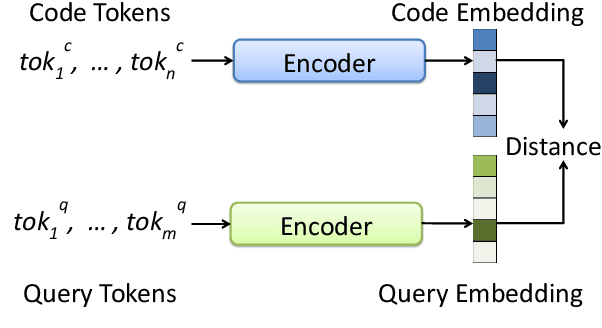
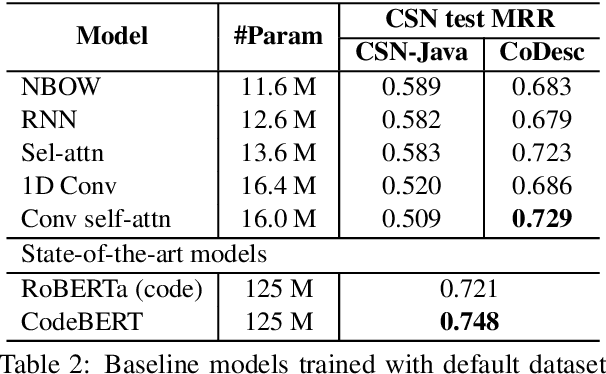

Translation between natural language and source code can help software development by enabling developers to comprehend, ideate, search, and write computer programs in natural language. Despite growing interest from the industry and the research community, this task is often difficult due to the lack of large standard datasets suitable for training deep neural models, standard noise removal methods, and evaluation benchmarks. This leaves researchers to collect new small-scale datasets, resulting in inconsistencies across published works. In this study, we present CoDesc -- a large parallel dataset composed of 4.2 million Java methods and natural language descriptions. With extensive analysis, we identify and remove prevailing noise patterns from the dataset. We demonstrate the proficiency of CoDesc in two complementary tasks for code-description pairs: code summarization and code search. We show that the dataset helps improve code search by up to 22\% and achieves the new state-of-the-art in code summarization. Furthermore, we show CoDesc's effectiveness in pre-training--fine-tuning setup, opening possibilities in building pretrained language models for Java. To facilitate future research, we release the dataset, a data processing tool, and a benchmark at \url{https://github.com/csebuetnlp/CoDesc}.
Text2App: A Framework for Creating Android Apps from Text Descriptions
Apr 16, 2021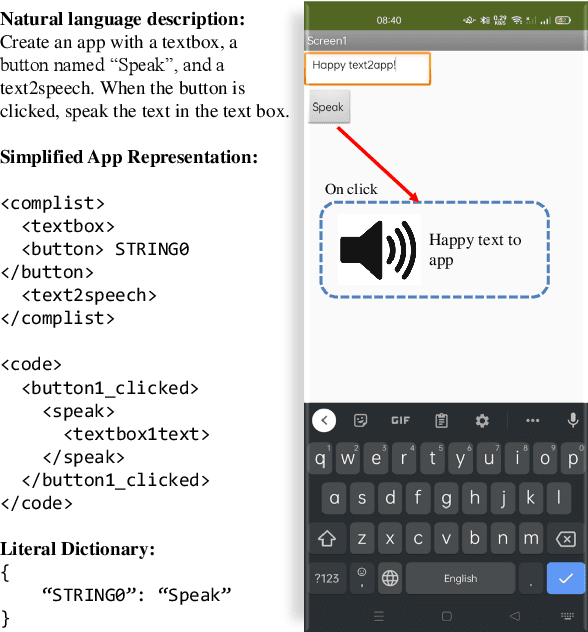

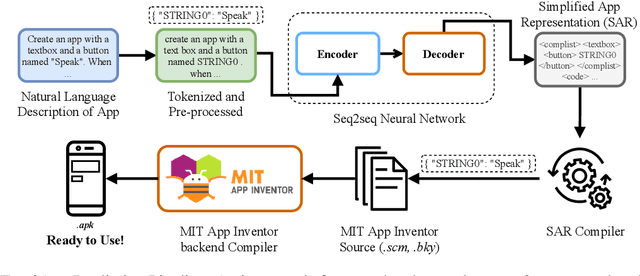
We present Text2App -- a framework that allows users to create functional Android applications from natural language specifications. The conventional method of source code generation tries to generate source code directly, which is impractical for creating complex software. We overcome this limitation by transforming natural language into an abstract intermediate formal language representing an application with a substantially smaller number of tokens. The intermediate formal representation is then compiled into target source codes. This abstraction of programming details allows seq2seq networks to learn complex application structures with less overhead. In order to train sequence models, we introduce a data synthesis method grounded in a human survey. We demonstrate that Text2App generalizes well to unseen combination of app components and it is capable of handling noisy natural language instructions. We explore the possibility of creating applications from highly abstract instructions by coupling our system with GPT-3 -- a large pretrained language model. The source code, a ready-to-run demo notebook, and a demo video are publicly available at \url{http://text2app.github.io}.
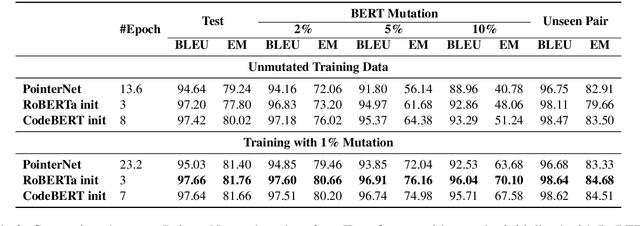
BERT2Code: Can Pretrained Language Models be Leveraged for Code Search?
Apr 16, 2021
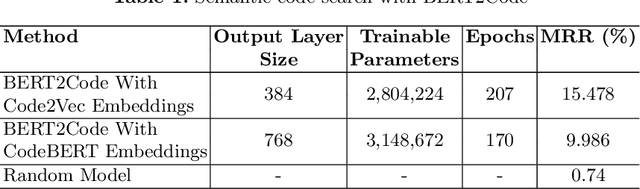
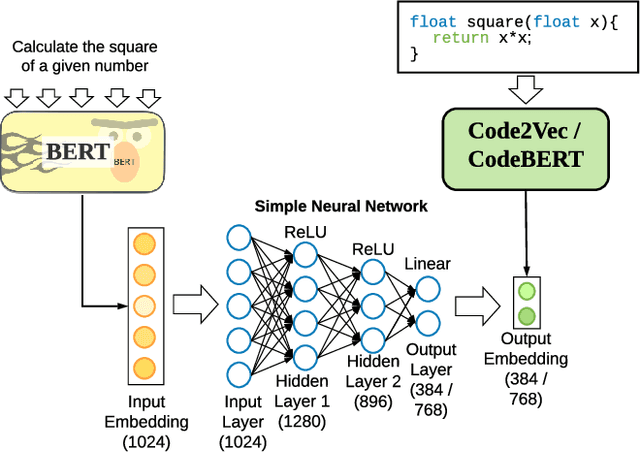

Millions of repetitive code snippets are submitted to code repositories every day. To search from these large codebases using simple natural language queries would allow programmers to ideate, prototype, and develop easier and faster. Although the existing methods have shown good performance in searching codes when the natural language description contains keywords from the code, they are still far behind in searching codes based on the semantic meaning of the natural language query and semantic structure of the code. In recent years, both natural language and programming language research communities have created techniques to embed them in vector spaces. In this work, we leverage the efficacy of these embedding models using a simple, lightweight 2-layer neural network in the task of semantic code search. We show that our model learns the inherent relationship between the embedding spaces and further probes into the scope of improvement by empirically analyzing the embedding methods. In this analysis, we show that the quality of the code embedding model is the bottleneck for our model's performance, and discuss future directions of study in this area.