 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithm Design and Stronger Guarantees for the Improving Multi-Armed Bandits Problem
Nov 13, 2025The improving multi-armed bandits problem is a formal model for allocating effort under uncertainty, motivated by scenarios such as investing research effort into new technologies, performing clinical trials, and hyperparameter selection from learning curves. Each pull of an arm provides reward that increases monotonically with diminishing returns. A growing line of work has designed algorithms for improving bandits, albeit with somewhat pessimistic worst-case guarantees. Indeed, strong lower bounds of $Ω(k)$ and $Ω(\sqrt{k})$ multiplicative approximation factors are known for both deterministic and randomized algorithms (respectively) relative to the optimal arm, where $k$ is the number of bandit arms. In this work, we propose two new parameterized families of bandit algorithms and bound the sample complexity of learning the near-optimal algorithm from each family using offline data. The first family we define includes the optimal randomized algorithm from prior work. We show that an appropriately chosen algorithm from this family can achieve stronger guarantees, with optimal dependence on $k$, when the arm reward curves satisfy additional properties related to the strength of concavity. Our second family contains algorithms that both guarantee best-arm identification on well-behaved instances and revert to worst case guarantees on poorly-behaved instances. Taking a statistical learning perspective on the bandit rewards optimization problem, we achieve stronger data-dependent guarantees without the need for actually verifying whether the assumptions are satisfied.
A Model for Combinatorial Dictionary Learning and Inference
Jul 26, 2024We are often interested in decomposing complex, structured data into simple components that explain the data. The linear version of this problem is well-studied as dictionary learning and factor analysis. In this work, we propose a combinatorial model in which to study this question, motivated by the way objects occlude each other in a scene to form an image. First, we identify a property we call "well-structuredness" of a set of low-dimensional components which ensures that no two components in the set are too similar. We show how well-structuredness is sufficient for learning the set of latent components comprising a set of sample instances. We then consider the problem: given a set of components and an instance generated from some unknown subset of them, identify which parts of the instance arise from which components. We consider two variants: (1) determine the minimal number of components required to explain the instance; (2) determine the correct explanation for as many locations as possible. For the latter goal, we also devise a version that is robust to adversarial corruptions, with just a slightly stronger assumption on the components. Finally, we show that the learning problem is computationally infeasible in the absence of any assumptions.
Nearly-tight Approximation Guarantees for the Improving Multi-Armed Bandits Problem
Apr 01, 2024We give nearly-tight upper and lower bounds for the improving multi-armed bandits problem. An instance of this problem has $k$ arms, each of whose reward function is a concave and increasing function of the number of times that arm has been pulled so far. We show that for any randomized online algorithm, there exists an instance on which it must suffer at least an $\Omega(\sqrt{k})$ approximation factor relative to the optimal reward. We then provide a randomized online algorithm that guarantees an $O(\sqrt{k})$ approximation factor, if it is told the maximum reward achievable by the optimal arm in advance. We then show how to remove this assumption at the cost of an extra $O(\log k)$ approximation factor, achieving an overall $O(\sqrt{k} \log k)$ approximation relative to optimal.
Applying statistical learning theory to deep learning
Nov 26, 2023Although statistical learning theory provides a robust framework to understand supervised learning, many theoretical aspects of deep learning remain unclear, in particular how different architectures may lead to inductive bias when trained using gradient based methods. The goal of these lectures is to provide an overview of some of the main questions that arise when attempting to understand deep learning from a learning theory perspective. After a brief reminder on statistical learning theory and stochastic optimization, we discuss implicit bias in the context of benign overfitting. We then move to a general description of the mirror descent algorithm, showing how we may go back and forth between a parameter space and the corresponding function space for a given learning problem, as well as how the geometry of the learning problem may be represented by a metric tensor. Building on this framework, we provide a detailed study of the implicit bias of gradient descent on linear diagonal networks for various regression tasks, showing how the loss function, scale of parameters at initialization and depth of the network may lead to various forms of implicit bias, in particular transitioning between kernel or feature learning.
Testing Tail Weight of a Distribution Via Hazard Rate
Oct 06, 2020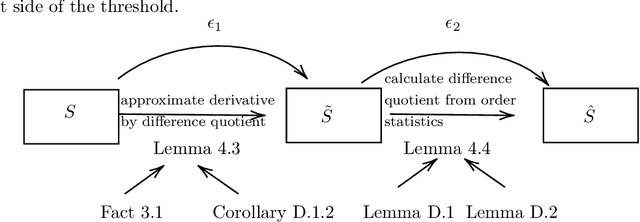
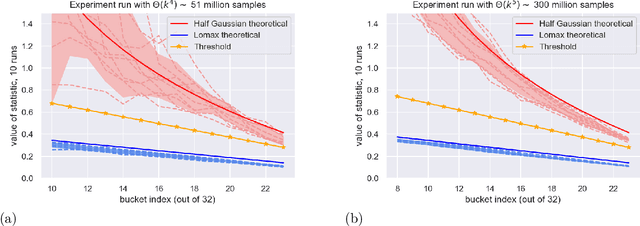
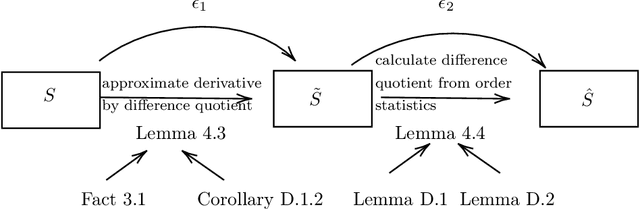
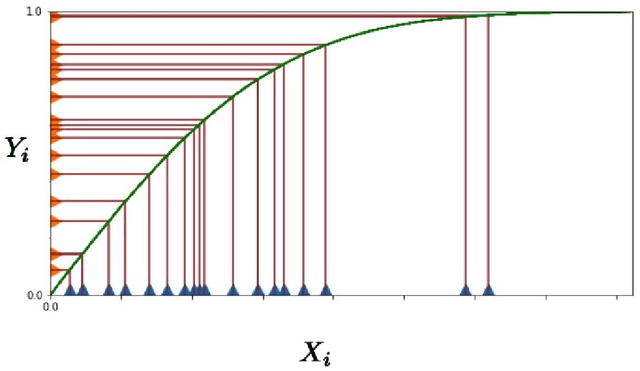
Understanding the shape of a distribution of data is of interest to people in a great variety of fields, as it may affect the types of algorithms used for that data. Given samples from a distribution, we seek to understand how many elements appear infrequently, that is, to characterize the tail of the distribution. We develop an algorithm based on a careful bucketing scheme that distinguishes heavy-tailed distributions from non-heavy-tailed ones via a definition based on the hazard rate under some natural smoothness and ordering assumptions. We verify our theoretical results empirically.