 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoRC: Towards Complex Language Understanding with Paraphrased Reading Comprehension
Oct 10, 2018
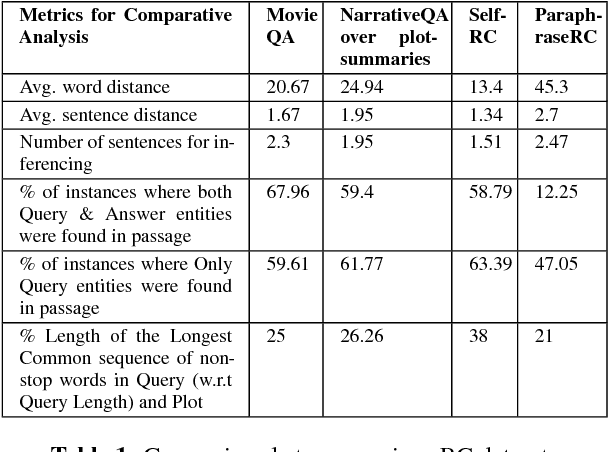
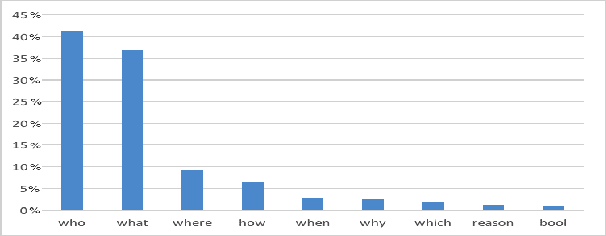
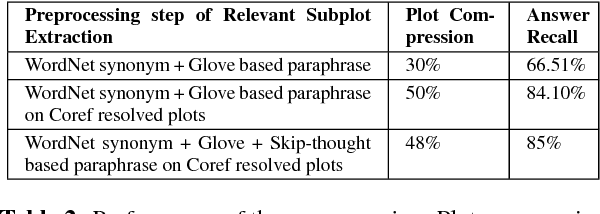
We propose DuoRC, a novel dataset for Reading Comprehension (RC) that motivates several new challenges for neural approaches in language understanding beyond those offered by existing RC datasets. DuoRC contains 186,089 unique question-answer pairs created from a collection of 7680 pairs of movie plots where each pair in the collection reflects two versions of the same movie - one from Wikipedia and the other from IMDb - written by two different authors. We asked crowdsourced workers to create questions from one version of the plot and a different set of workers to extract or synthesize answers from the other version. This unique characteristic of DuoRC where questions and answers are created from different versions of a document narrating the same underlying story, ensures by design, that there is very little lexical overlap between the questions created from one version and the segments containing the answer in the other version. Further, since the two versions have different levels of plot detail, narration style, vocabulary, etc., answering questions from the second version requires deeper language understanding and incorporating external background knowledge. Additionally, the narrative style of passages arising from movie plots (as opposed to typical descriptive passages in existing datasets) exhibits the need to perform complex reasoning over events across multiple sentences. Indeed, we observe that state-of-the-art neural RC models which have achieved near human performance on the SQuAD dataset, even when coupled with traditional NLP techniques to address the challenges presented in DuoRC exhibit very poor performance (F1 score of 37.42% on DuoRC v/s 86% on SQuAD dataset). This opens up several interesting research avenues wherein DuoRC could complement other RC datasets to explore novel neural approaches for studying language understanding.
Complex Sequential Question Answering: Towards Learning to Converse Over Linked Question Answer Pairs with a Knowledge Graph
Oct 04, 2018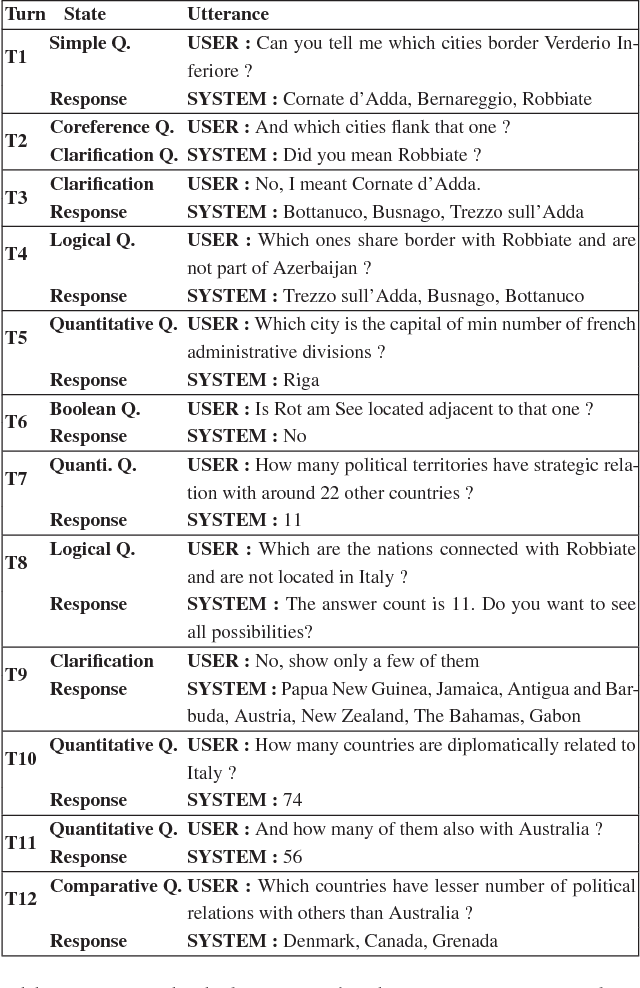
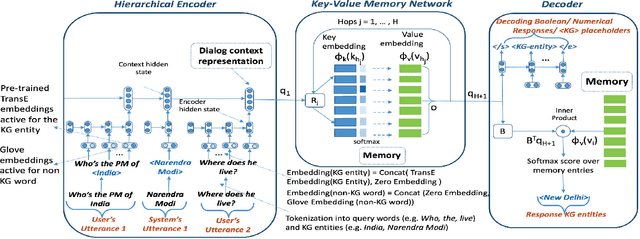
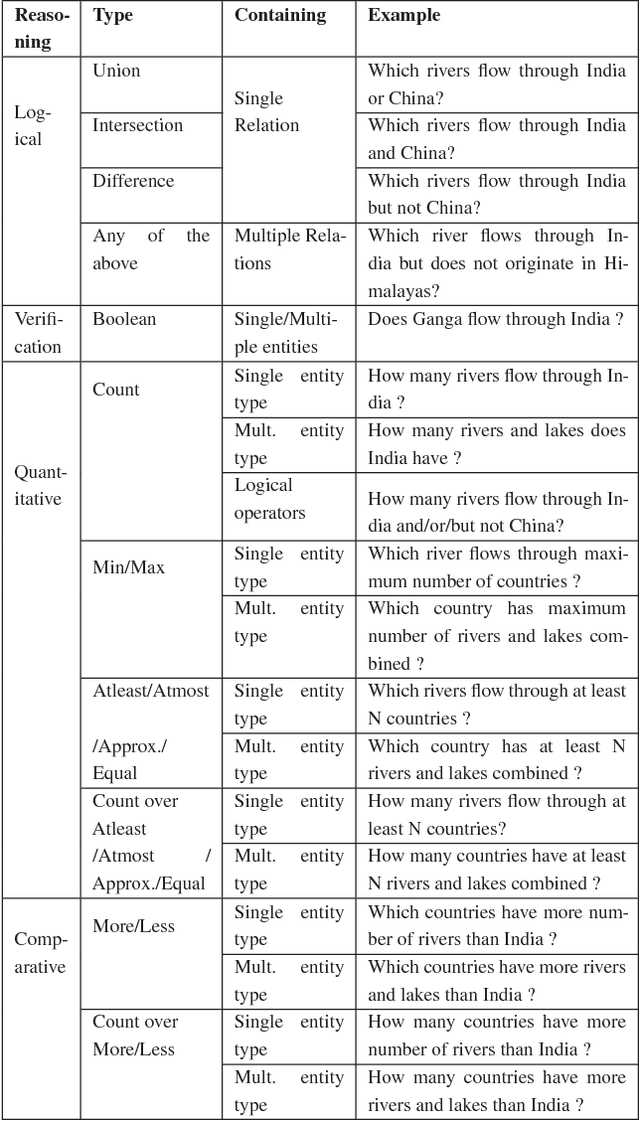
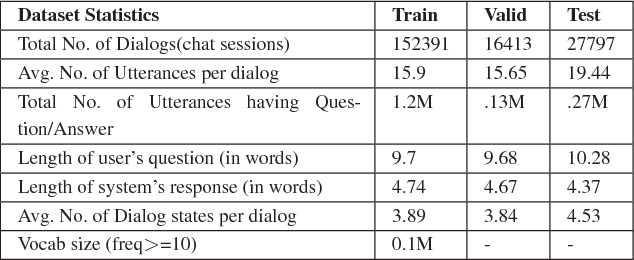
While conversing with chatbots, humans typically tend to ask many questions, a significant portion of which can be answered by referring to large-scale knowledge graphs (KG). While Question Answering (QA) and dialog systems have been studied independently, there is a need to study them closely to evaluate such real-world scenarios faced by bots involving both these tasks. Towards this end, we introduce the task of Complex Sequential QA which combines the two tasks of (i) answering factual questions through complex inferencing over a realistic-sized KG of millions of entities, and (ii) learning to converse through a series of coherently linked QA pairs. Through a labor intensive semi-automatic process, involving in-house and crowdsourced workers, we created a dataset containing around 200K dialogs with a total of 1.6M turns. Further, unlike existing large scale QA datasets which contain simple questions that can be answered from a single tuple, the questions in our dialogs require a larger subgraph of the KG. Specifically, our dataset has questions which require logical, quantitative, and comparative reasoning as well as their combinations. This calls for models which can: (i) parse complex natural language questions, (ii) use conversation context to resolve coreferences and ellipsis in utterances, (iii) ask for clarifications for ambiguous queries, and finally (iv) retrieve relevant subgraphs of the KG to answer such questions. However, our experiments with a combination of state of the art dialog and QA models show that they clearly do not achieve the above objectives and are inadequate for dealing with such complex real world settings. We believe that this new dataset coupled with the limitations of existing models as reported in this paper should encourage further research in Complex Sequential QA.
Unsupervised Controllable Text Formalization
Sep 10, 2018
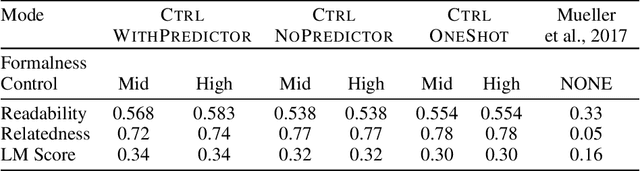
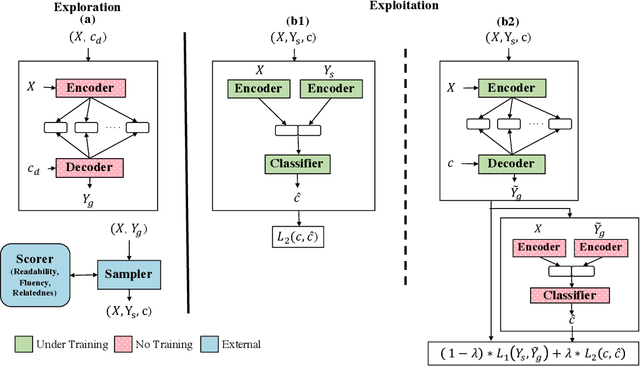

We propose a novel framework for controllable natural language transformation. Realizing that the requirement of parallel corpus is practically unsustainable for controllable generation tasks, an unsupervised training scheme is introduced. The crux of the framework is a deep neural encoder-decoder that is reinforced with text-transformation knowledge through auxiliary modules (called scorers). The scorers, based on off-the-shelf language processing tools, decide the learning scheme of the encoder-decoder based on its actions. We apply this framework for the text-transformation task of formalizing an input text by improving its readability grade; the degree of required formalization can be controlled by the user at run-time. Experiments on public datasets demonstrate the efficacy of our model towards: (a) transforming a given text to a more formal style, and (b) introducing appropriate amount of formalness in the output text pertaining to the input control. Our code and datasets are released for academic use.
Modeling Topical Coherence in Discourse without Supervision
Sep 02, 2018
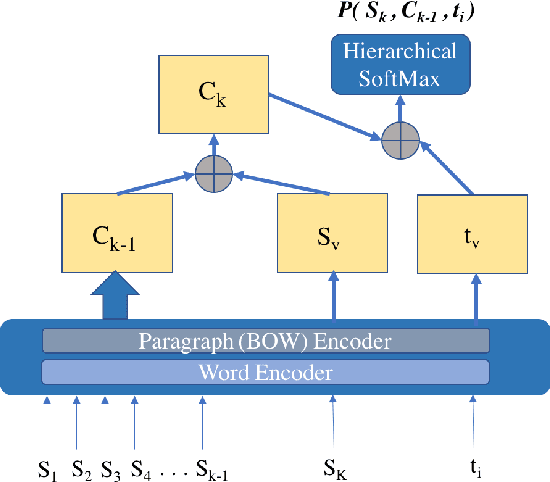
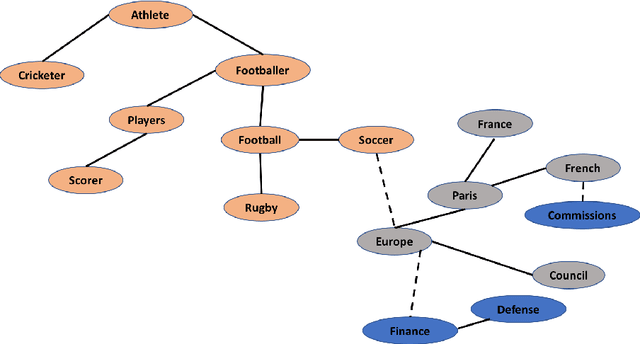
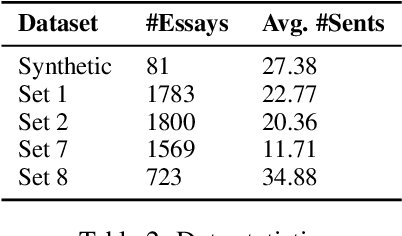
Coherence of text is an important attribute to be measured for both manually and automatically generated discourse; but well-defined quantitative metrics for it are still elusive. In this paper, we present a metric for scoring topical coherence of an input paragraph on a real-valued scale by analyzing its underlying topical structure. We first extract all possible topics that the sentences of a paragraph of text are related to. Coherence of this text is then measured by computing: (a) the degree of uncertainty of the topics with respect to the paragraph, and (b) the relatedness between these topics. All components of our modular framework rely only on unlabeled data and WordNet, thus making it completely unsupervised, which is an important feature for general-purpose usage of any metric. Experiments are conducted on two datasets - a publicly available dataset for essay grading (representing human discourse), and a synthetic dataset constructed by mixing content from multiple paragraphs covering diverse topics. Our evaluation shows that the measured coherence scores are positively correlated with the ground truth for both the datasets. Further validation to our coherence scores is provided by conducting human evaluation on the synthetic data, showing a significant agreement of 79.3%
A Mixed Hierarchical Attention based Encoder-Decoder Approach for Standard Table Summarization
Apr 20, 2018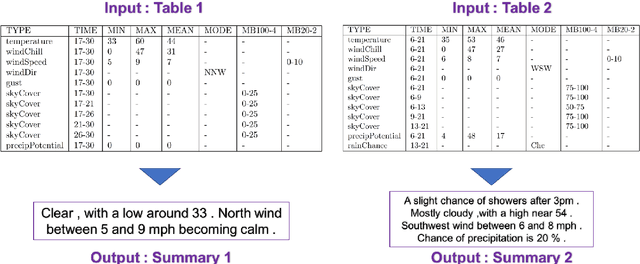
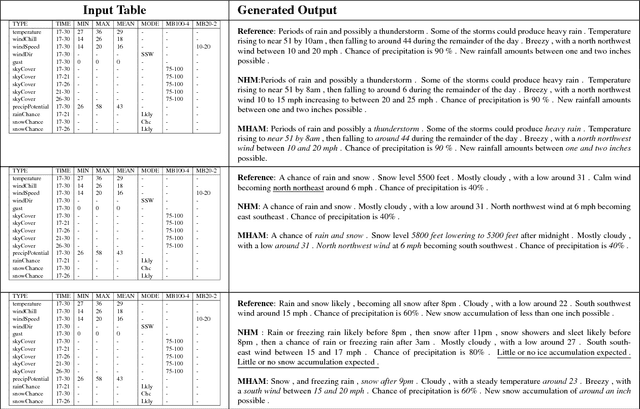
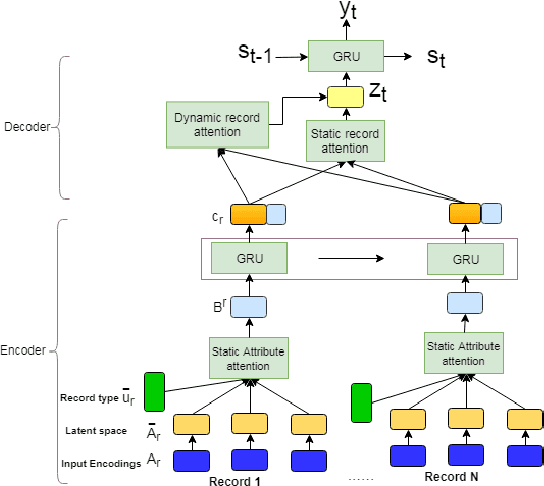
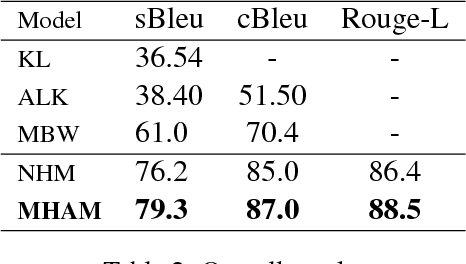
Structured data summarization involves generation of natural language summaries from structured input data. In this work, we consider summarizing structured data occurring in the form of tables as they are prevalent across a wide variety of domains. We formulate the standard table summarization problem, which deals with tables conforming to a single predefined schema. To this end, we propose a mixed hierarchical attention based encoder-decoder model which is able to leverage the structure in addition to the content of the tables. Our experiments on the publicly available WEATHERGOV dataset show around 18 BLEU (~ 30%) improvement over the current state-of-the-art.
Generating Descriptions from Structured Data Using a Bifocal Attention Mechanism and Gated Orthogonalization
Apr 20, 2018
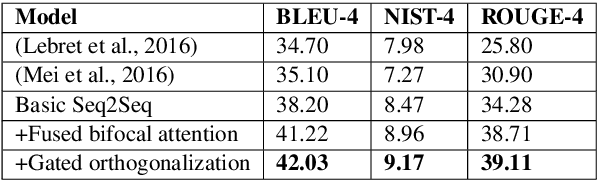
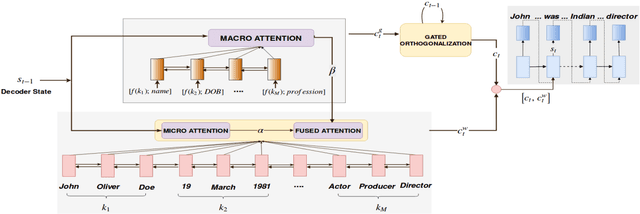

In this work, we focus on the task of generating natural language descriptions from a structured table of facts containing fields (such as nationality, occupation, etc) and values (such as Indian, actor, director, etc). One simple choice is to treat the table as a sequence of fields and values and then use a standard seq2seq model for this task. However, such a model is too generic and does not exploit task-specific characteristics. For example, while generating descriptions from a table, a human would attend to information at two levels: (i) the fields (macro level) and (ii) the values within the field (micro level). Further, a human would continue attending to a field for a few timesteps till all the information from that field has been rendered and then never return back to this field (because there is nothing left to say about it). To capture this behavior we use (i) a fused bifocal attention mechanism which exploits and combines this micro and macro level information and (ii) a gated orthogonalization mechanism which tries to ensure that a field is remembered for a few time steps and then forgotten. We experiment with a recently released dataset which contains fact tables about people and their corresponding one line biographical descriptions in English. In addition, we also introduce two similar datasets for French and German. Our experiments show that the proposed model gives 21% relative improvement over a recently proposed state of the art method and 10% relative improvement over basic seq2seq models. The code and the datasets developed as a part of this work are publicly available.
Towards Building Large Scale Multimodal Domain-Aware Conversation Systems
Jan 31, 2018
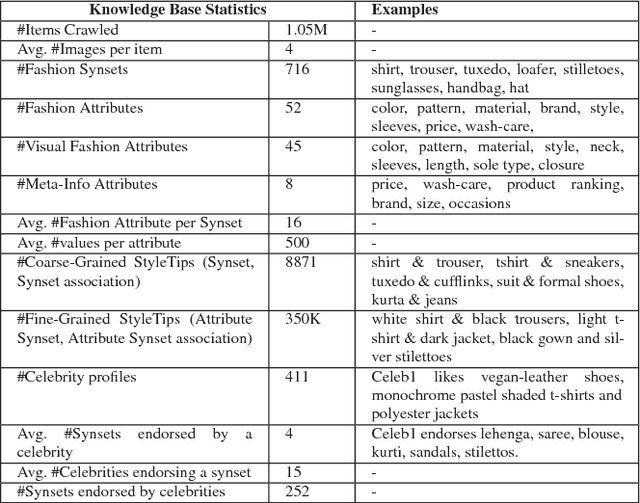
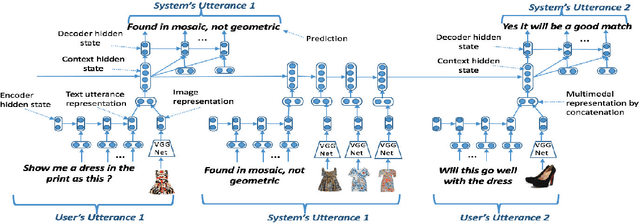
While multimodal conversation agents are gaining importance in several domains such as retail, travel etc., deep learning research in this area has been limited primarily due to the lack of availability of large-scale, open chatlogs. To overcome this bottleneck, in this paper we introduce the task of multimodal, domain-aware conversations, and propose the MMD benchmark dataset. This dataset was gathered by working in close coordination with large number of domain experts in the retail domain. These experts suggested various conversations flows and dialog states which are typically seen in multimodal conversations in the fashion domain. Keeping these flows and states in mind, we created a dataset consisting of over 150K conversation sessions between shoppers and sales agents, with the help of in-house annotators using a semi-automated manually intense iterative process. With this dataset, we propose 5 new sub-tasks for multimodal conversations along with their evaluation methodology. We also propose two multimodal neural models in the encode-attend-decode paradigm and demonstrate their performance on two of the sub-tasks, namely text response generation and best image response selection. These experiments serve to establish baseline performance and open new research directions for each of these sub-tasks. Further, for each of the sub-tasks, we present a `per-state evaluation' of 9 most significant dialog states, which would enable more focused research into understanding the challenges and complexities involved in each of these states.
Story Generation from Sequence of Independent Short Descriptions
Aug 21, 2017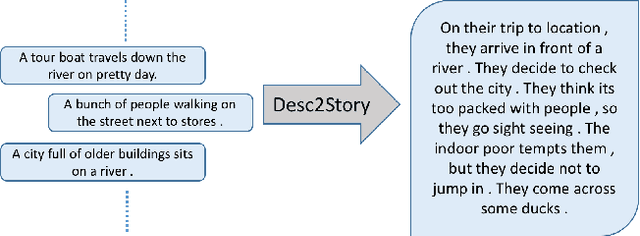
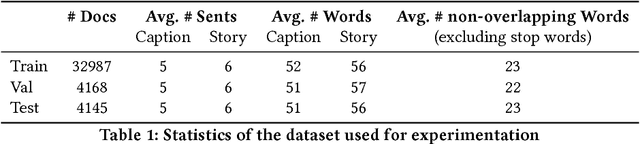
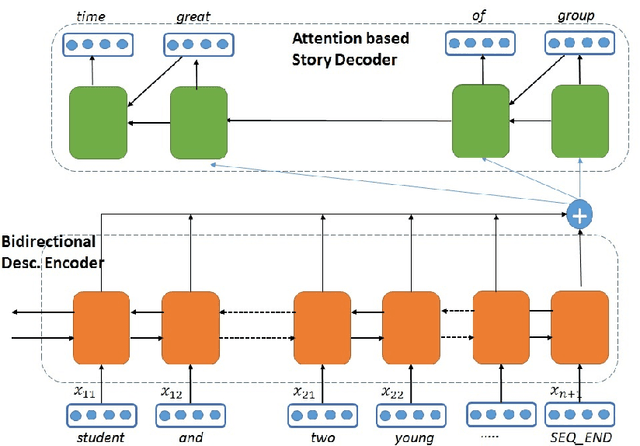
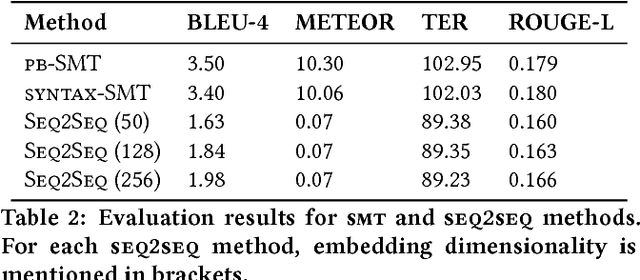
Existing Natural Language Generation (NLG) systems are weak AI systems and exhibit limited capabilities when language generation tasks demand higher levels of creativity, originality and brevity. Effective solutions or, at least evaluations of modern NLG paradigms for such creative tasks have been elusive, unfortunately. This paper introduces and addresses the task of coherent story generation from independent descriptions, describing a scene or an event. Towards this, we explore along two popular text-generation paradigms -- (1) Statistical Machine Translation (SMT), posing story generation as a translation problem and (2) Deep Learning, posing story generation as a sequence to sequence learning problem. In SMT, we chose two popular methods such as phrase based SMT (PB-SMT) and syntax based SMT (SYNTAX-SMT) to `translate' the incoherent input text into stories. We then implement a deep recurrent neural network (RNN) architecture that encodes sequence of variable length input descriptions to corresponding latent representations and decodes them to produce well formed comprehensive story like summaries. The efficacy of the suggested approaches is demonstrated on a publicly available dataset with the help of popular machine translation and summarization evaluation metrics.
A Machine Learning Approach for Evaluating Creative Artifacts
Jul 18, 2017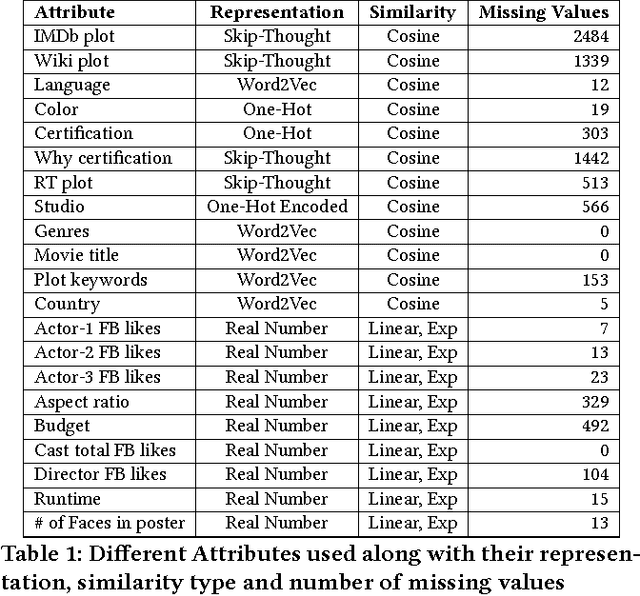
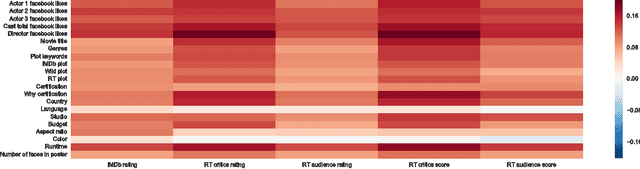
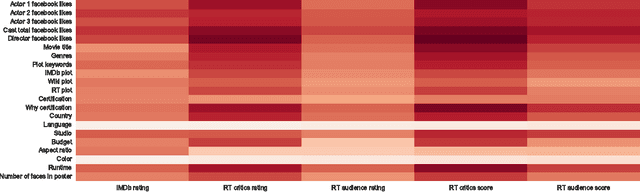
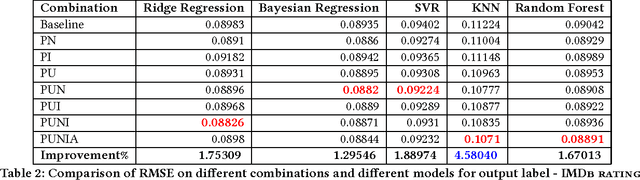
Much work has been done in understanding human creativity and defining measures to evaluate creativity. This is necessary mainly for the reason of having an objective and automatic way of quantifying creative artifacts. In this work, we propose a regression-based learning framework which takes into account quantitatively the essential criteria for creativity like novelty, influence, value and unexpectedness. As it is often the case with most creative domains, there is no clear ground truth available for creativity. Our proposed learning framework is applicable to all creative domains; yet we evaluate it on a dataset of movies created from IMDb and Rotten Tomatoes due to availability of audience and critic scores, which can be used as proxy ground truth labels for creativity. We report promising results and observations from our experiments in the following ways : 1) Correlation of creative criteria with critic scores, 2) Improvement in movie rating prediction with inclusion of various creative criteria, and 3) Identification of creative movies.