 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-action Tangled Program Graphs for Multi-task Reinforcement Learning with Continuous Control
Apr 28, 2026Over the past few decades, machine learning has been widely used to learn complex tasks. Reinforcement Learning (RL), inspired by human behavior, is a great example, as it involves developing specific behaviours for specific tasks. To further challenge algorithms, Multi-Task RL (MTRL) environments have been introduced, requiring a single model to learn multiple behaviors. The Tangled Program Graph (TPG) algorithm is a Genetic Programming (GP) algorithm designed for discrete MTRL environments. Recently, the MAPLE algorithm has been proposed, as another GP algorithm that achieves high results in single task continuous RL environments. A variation of the TPG is proposed alongside MAPLE, named Multi-Action TPG (MATPG) that aggregates MAPLE agents, and creates a control flow to activate them. Initially tested on single task RL environments only, MATPG achieved similar results to MAPLE. In this work, we present a new benchmark based on the MuJoCo Half Cheetah from Gymnasium. This benchmark features five distinct obstacles that are randomly positioned in front of the agent, each of which demands a unique behavior. This benchmark serves as a use case for MATPG, to prove its ability as a GP solution for continuous MTRL environments. Our experiments demonstrate its superiority in this multi-task use case when combined with lexicase selection. Furthermore, we examine the interpretability of the evolved graph, revealing that the decision flow of the model is fully interpretable.
Tangled Program Graphs as an alternative to DRL-based control algorithms for UAVs
Nov 08, 2024Deep reinforcement learning (DRL) is currently the most popular AI-based approach to autonomous vehicle control. An agent, trained for this purpose in simulation, can interact with the real environment with a human-level performance. Despite very good results in terms of selected metrics, this approach has some significant drawbacks: high computational requirements and low explainability. Because of that, a DRL-based agent cannot be used in some control tasks, especially when safety is the key issue. Therefore we propose to use Tangled Program Graphs (TPGs) as an alternative for deep reinforcement learning in control-related tasks. In this approach, input signals are processed by simple programs that are combined in a graph structure. As a result, TPGs are less computationally demanding and their actions can be explained based on the graph structure. In this paper, we present our studies on the use of TPGs as an alternative for DRL in control-related tasks. In particular, we consider the problem of navigating an unmanned aerial vehicle (UAV) through the unknown environment based solely on the on-board LiDAR sensor. The results of our work show promising prospects for the use of TPGs in control related-tasks.
Gegelati: Lightweight Artificial Intelligence through Generic and Evolvable Tangled Program Graphs
Dec 15, 2020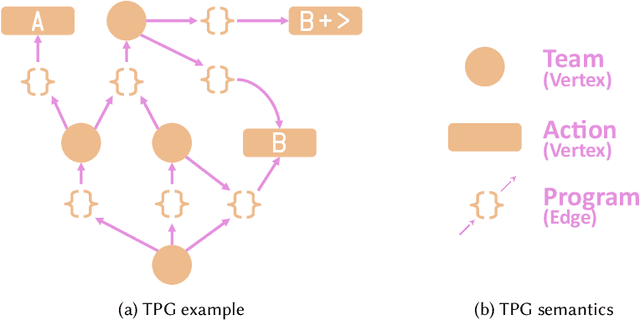
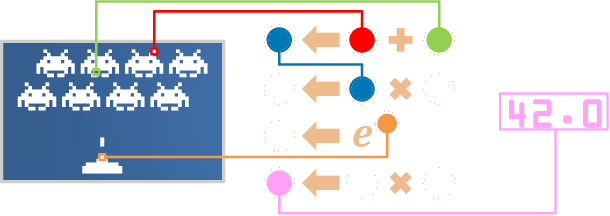
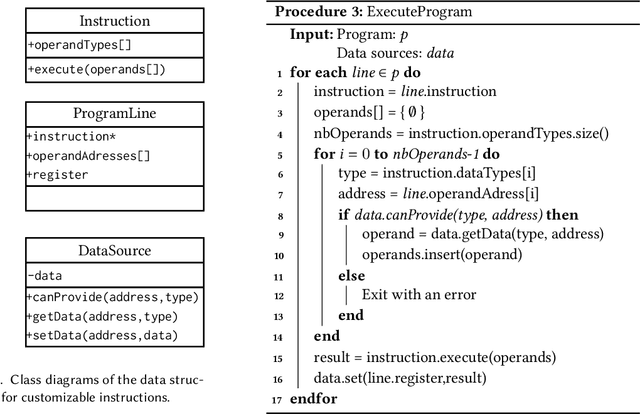
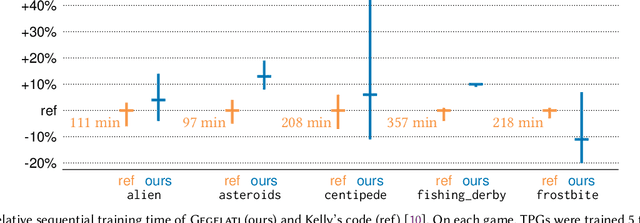
Tangled Program Graph (TPG) is a reinforcement learning technique based on genetic programming concepts. On state-of-the-art learning environments, TPGs have been shown to offer comparable competence with Deep Neural Networks (DNNs), for a fraction of their computational and storage cost. This lightness of TPGs, both for training and inference, makes them an interesting model to implement Artificial Intelligences (AIs) on embedded systems with limited computational and storage resources. In this paper, we introduce the Gegelati library for TPGs. Besides introducing the general concepts and features of the library, two main contributions are detailed in the paper: 1/ The parallelization of the deterministic training process of TPGs, for supporting heterogeneous Multiprocessor Systems-on-Chips (MPSoCs). 2/ The support for customizable instruction sets and data types within the genetically evolved programs of the TPG model. The scalability of the parallel training process is demonstrated through experiments on architectures ranging from a high-end 24-core processor to a low-power heterogeneous MPSoC. The impact of customizable instructions on the outcome of a training process is demonstrated on a state-of-the-art reinforcement learning environment. CCS Concepts: $\bullet$ Computer systems organization $\rightarrow$ Embedded systems; $\bullet$ Computing methodologies $\rightarrow$ Machine learning.