 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Parsing with Semi-Supervised Sequential Autoencoders
Sep 29, 2016

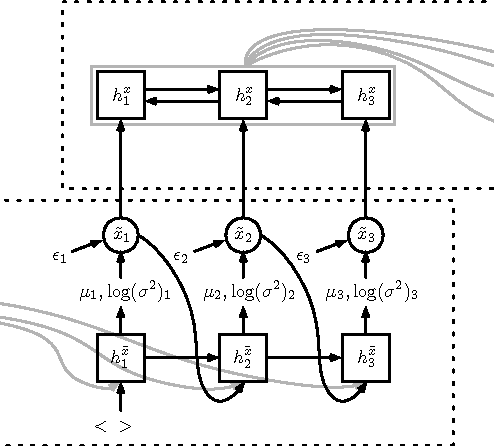
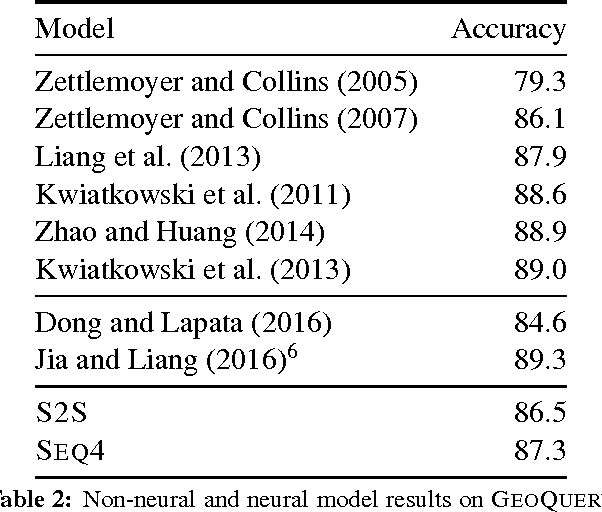
We present a novel semi-supervised approach for sequence transduction and apply it to semantic parsing. The unsupervised component is based on a generative model in which latent sentences generate the unpaired logical forms. We apply this method to a number of semantic parsing tasks focusing on domains with limited access to labelled training data and extend those datasets with synthetically generated logical forms.
Latent Predictor Networks for Code Generation
Jun 08, 2016
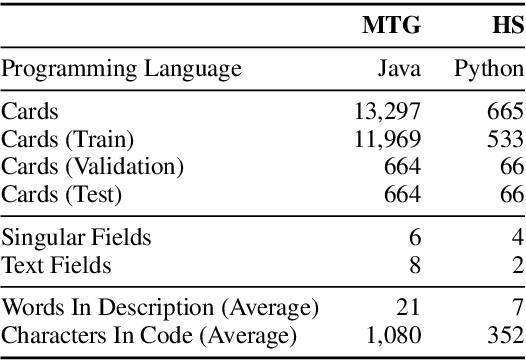


Many language generation tasks require the production of text conditioned on both structured and unstructured inputs. We present a novel neural network architecture which generates an output sequence conditioned on an arbitrary number of input functions. Crucially, our approach allows both the choice of conditioning context and the granularity of generation, for example characters or tokens, to be marginalised, thus permitting scalable and effective training. Using this framework, we address the problem of generating programming code from a mixed natural language and structured specification. We create two new data sets for this paradigm derived from the collectible trading card games Magic the Gathering and Hearthstone. On these, and a third preexisting corpus, we demonstrate that marginalising multiple predictors allows our model to outperform strong benchmarks.
Reasoning about Entailment with Neural Attention
Mar 01, 2016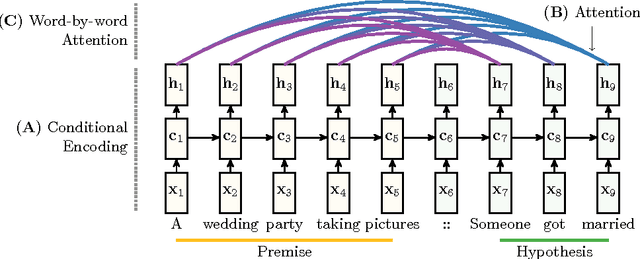
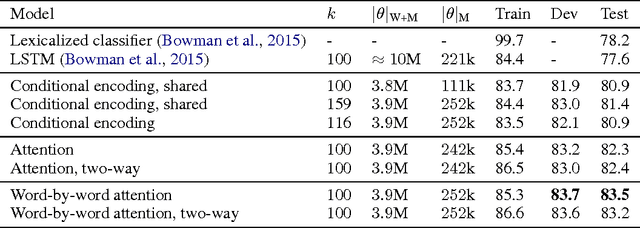
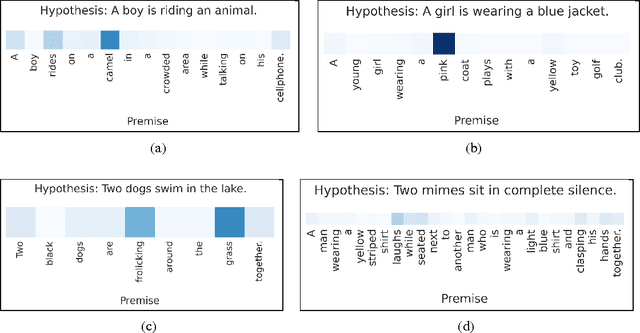
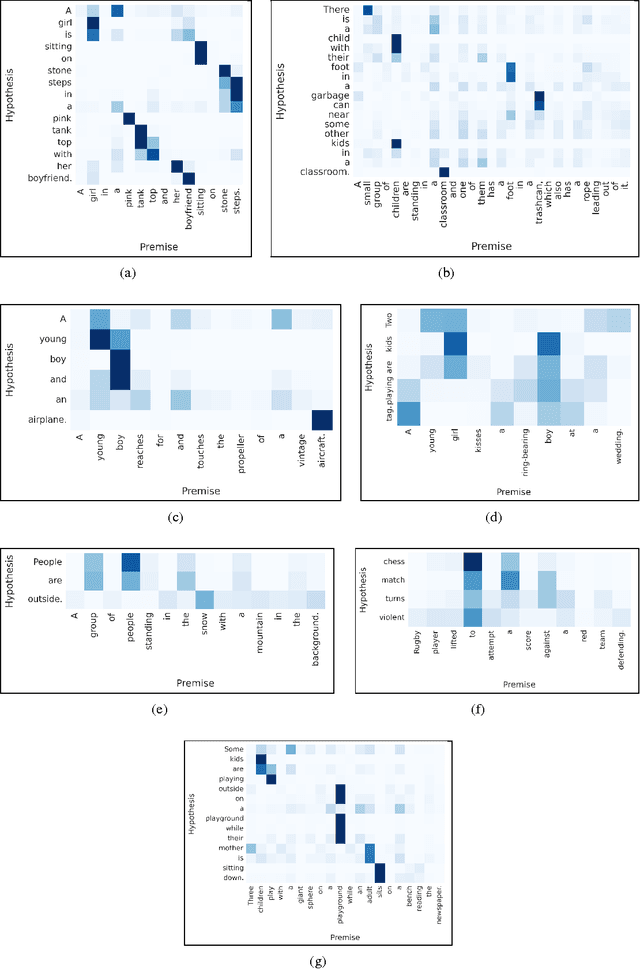
While most approaches to automatically recognizing entailment relations have used classifiers employing hand engineered features derived from complex natural language processing pipelines, in practice their performance has been only slightly better than bag-of-word pair classifiers using only lexical similarity. The only attempt so far to build an end-to-end differentiable neural network for entailment failed to outperform such a simple similarity classifier. In this paper, we propose a neural model that reads two sentences to determine entailment using long short-term memory units. We extend this model with a word-by-word neural attention mechanism that encourages reasoning over entailments of pairs of words and phrases. Furthermore, we present a qualitative analysis of attention weights produced by this model, demonstrating such reasoning capabilities. On a large entailment dataset this model outperforms the previous best neural model and a classifier with engineered features by a substantial margin. It is the first generic end-to-end differentiable system that achieves state-of-the-art accuracy on a textual entailment dataset.
Teaching Machines to Read and Comprehend
Nov 19, 2015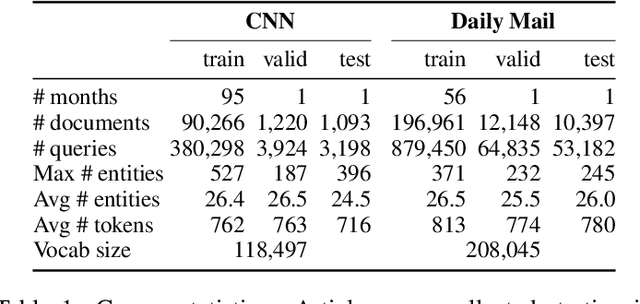
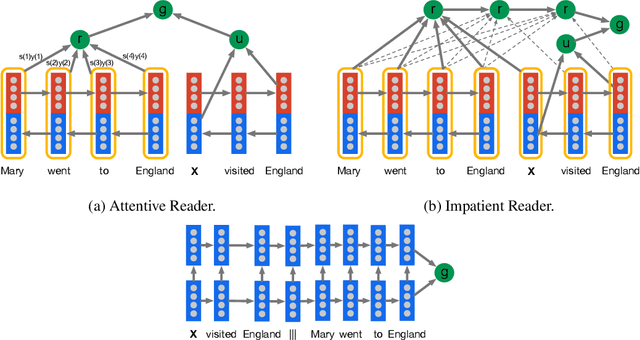
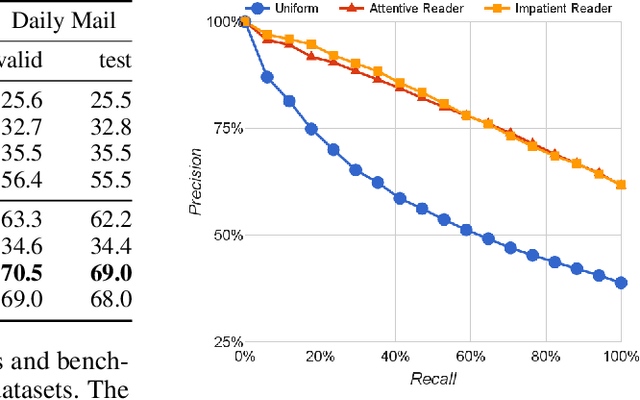

Teaching machines to read natural language documents remains an elusive challenge. Machine reading systems can be tested on their ability to answer questions posed on the contents of documents that they have seen, but until now large scale training and test datasets have been missing for this type of evaluation. In this work we define a new methodology that resolves this bottleneck and provides large scale supervised reading comprehension data. This allows us to develop a class of attention based deep neural networks that learn to read real documents and answer complex questions with minimal prior knowledge of language structure.
Learning to Transduce with Unbounded Memory
Nov 03, 2015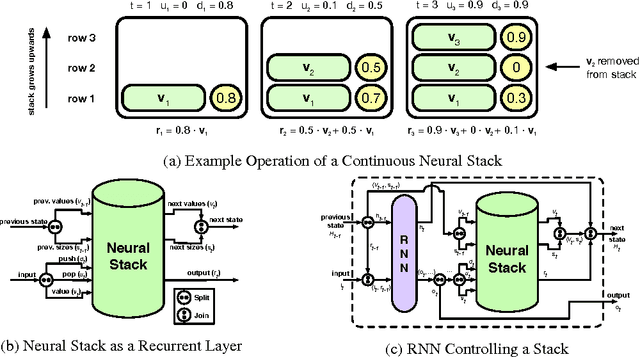

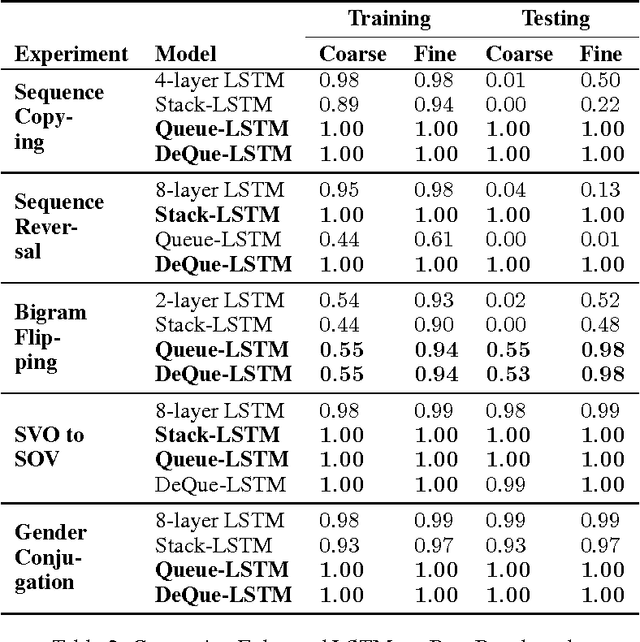
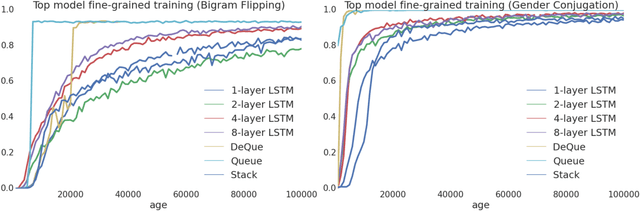
Recently, strong results have been demonstrated by Deep Recurrent Neural Networks on natural language transduction problems. In this paper we explore the representational power of these models using synthetic grammars designed to exhibit phenomena similar to those found in real transduction problems such as machine translation. These experiments lead us to propose new memory-based recurrent networks that implement continuously differentiable analogues of traditional data structures such as Stacks, Queues, and DeQues. We show that these architectures exhibit superior generalisation performance to Deep RNNs and are often able to learn the underlying generating algorithms in our transduction experiments.
Deep Learning for Answer Sentence Selection
Dec 04, 2014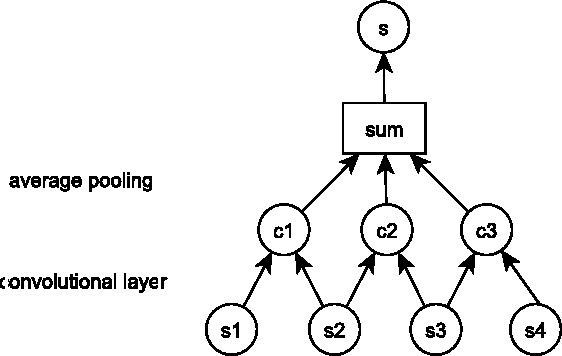
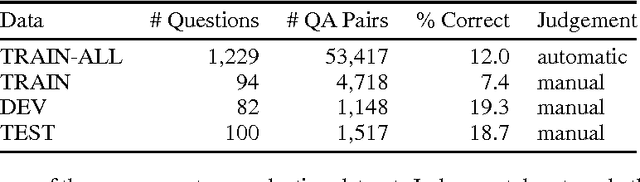
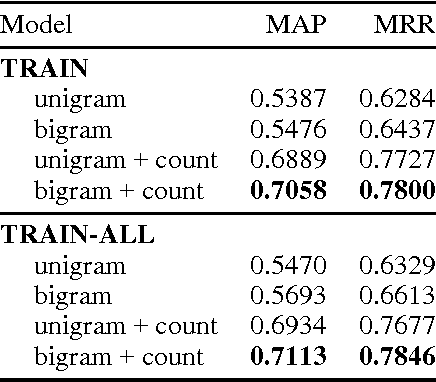
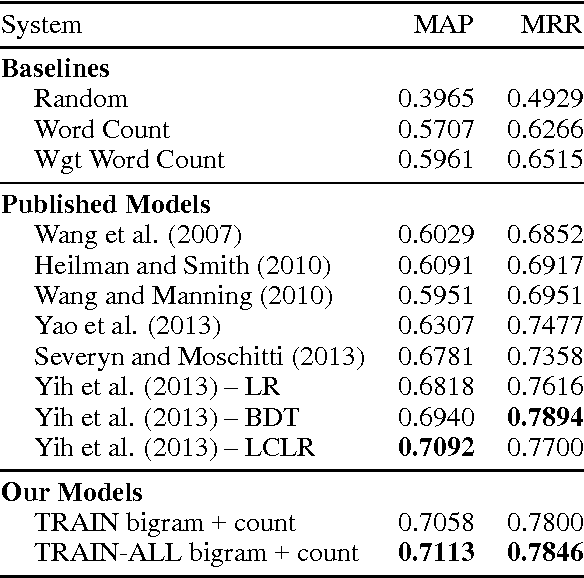
Answer sentence selection is the task of identifying sentences that contain the answer to a given question. This is an important problem in its own right as well as in the larger context of open domain question answering. We propose a novel approach to solving this task via means of distributed representations, and learn to match questions with answers by considering their semantic encoding. This contrasts prior work on this task, which typically relies on classifiers with large numbers of hand-crafted syntactic and semantic features and various external resources. Our approach does not require any feature engineering nor does it involve specialist linguistic data, making this model easily applicable to a wide range of domains and languages. Experimental results on a standard benchmark dataset from TREC demonstrate that---despite its simplicity---our model matches state of the art performance on the answer sentence selection task.
Distributed Representations for Compositional Semantics
Nov 12, 2014
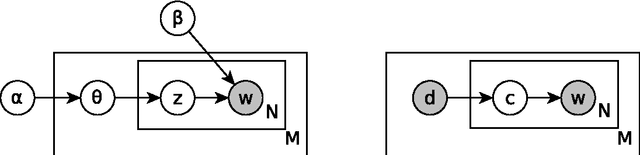
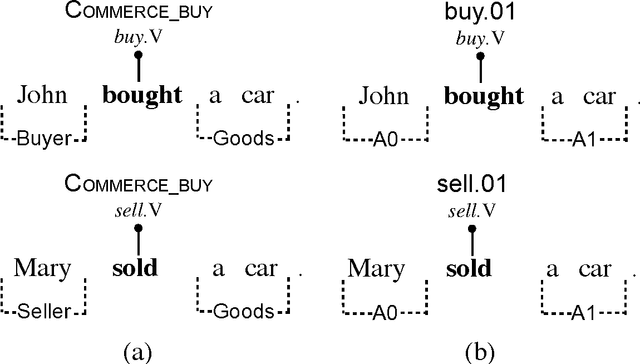

The mathematical representation of semantics is a key issue for Natural Language Processing (NLP). A lot of research has been devoted to finding ways of representing the semantics of individual words in vector spaces. Distributional approaches --- meaning distributed representations that exploit co-occurrence statistics of large corpora --- have proved popular and successful across a number of tasks. However, natural language usually comes in structures beyond the word level, with meaning arising not only from the individual words but also the structure they are contained in at the phrasal or sentential level. Modelling the compositional process by which the meaning of an utterance arises from the meaning of its parts is an equally fundamental task of NLP. This dissertation explores methods for learning distributed semantic representations and models for composing these into representations for larger linguistic units. Our underlying hypothesis is that neural models are a suitable vehicle for learning semantically rich representations and that such representations in turn are suitable vehicles for solving important tasks in natural language processing. The contribution of this thesis is a thorough evaluation of our hypothesis, as part of which we introduce several new approaches to representation learning and compositional semantics, as well as multiple state-of-the-art models which apply distributed semantic representations to various tasks in NLP.
Learning Bilingual Word Representations by Marginalizing Alignments
May 05, 2014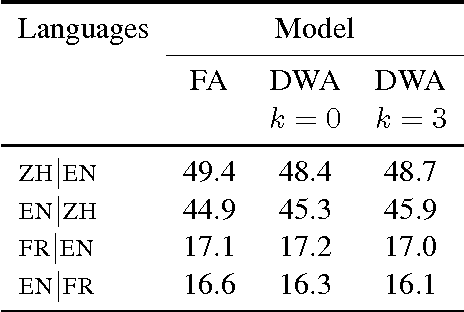

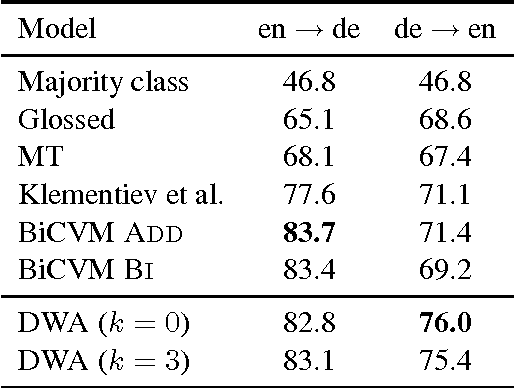

We present a probabilistic model that simultaneously learns alignments and distributed representations for bilingual data. By marginalizing over word alignments the model captures a larger semantic context than prior work relying on hard alignments. The advantage of this approach is demonstrated in a cross-lingual classification task, where we outperform the prior published state of the art.
A Deep Architecture for Semantic Parsing
Apr 29, 2014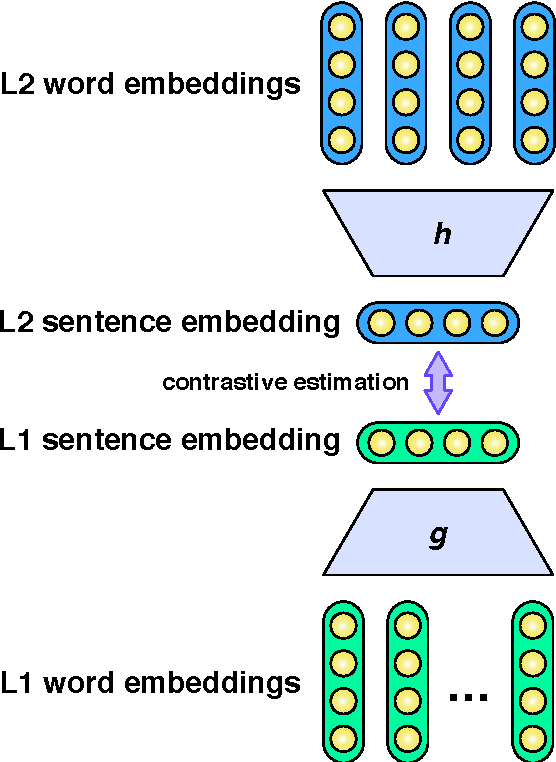
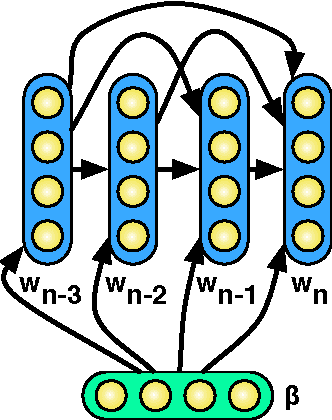
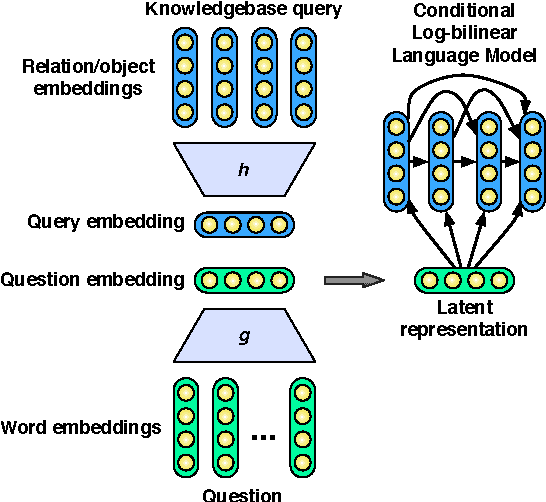
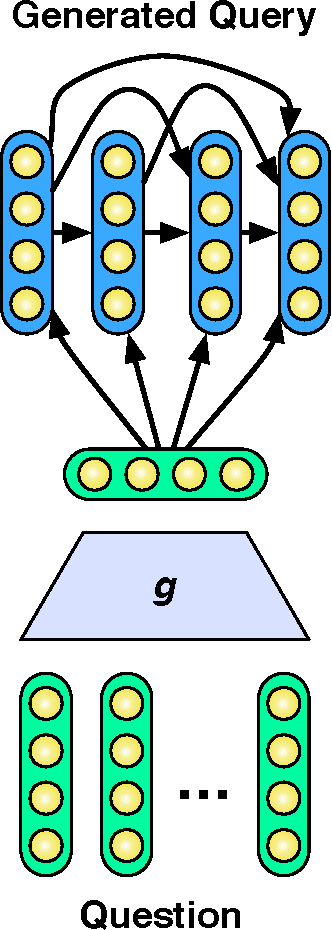
Many successful approaches to semantic parsing build on top of the syntactic analysis of text, and make use of distributional representations or statistical models to match parses to ontology-specific queries. This paper presents a novel deep learning architecture which provides a semantic parsing system through the union of two neural models of language semantics. It allows for the generation of ontology-specific queries from natural language statements and questions without the need for parsing, which makes it especially suitable to grammatically malformed or syntactically atypical text, such as tweets, as well as permitting the development of semantic parsers for resource-poor languages.
Multilingual Models for Compositional Distributed Semantics
Apr 17, 2014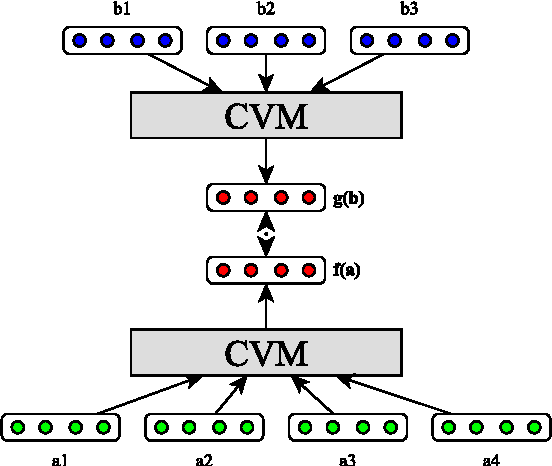
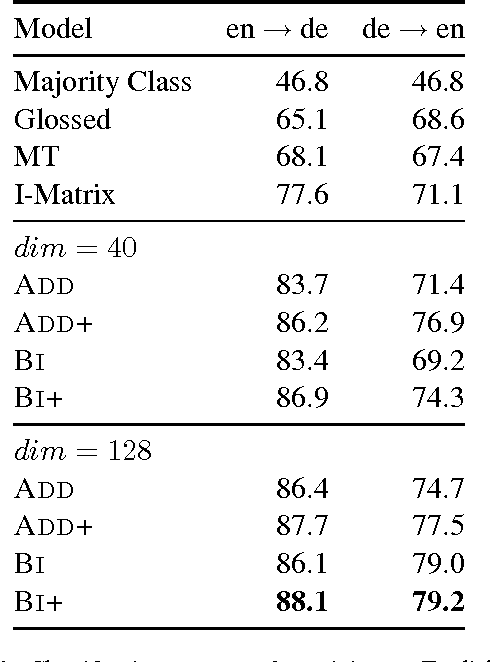
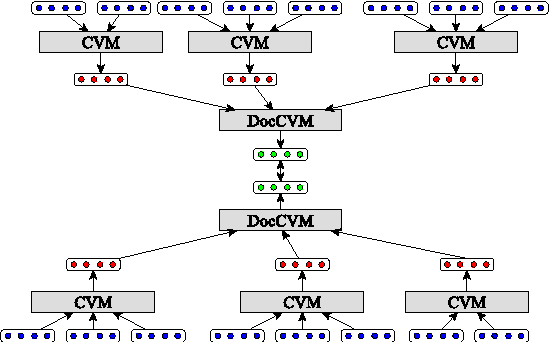
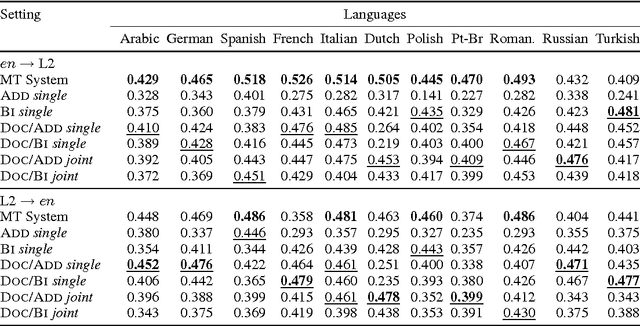
We present a novel technique for learning semantic representations, which extends the distributional hypothesis to multilingual data and joint-space embeddings. Our models leverage parallel data and learn to strongly align the embeddings of semantically equivalent sentences, while maintaining sufficient distance between those of dissimilar sentences. The models do not rely on word alignments or any syntactic information and are successfully applied to a number of diverse languages. We extend our approach to learn semantic representations at the document level, too. We evaluate these models on two cross-lingual document classification tasks, outperforming the prior state of the art. Through qualitative analysis and the study of pivoting effects we demonstrate that our representations are semantically plausible and can capture semantic relationships across languages without parallel data.