 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Audio Synthesis of Musical Notes with WaveNet Autoencoders
Apr 05, 2017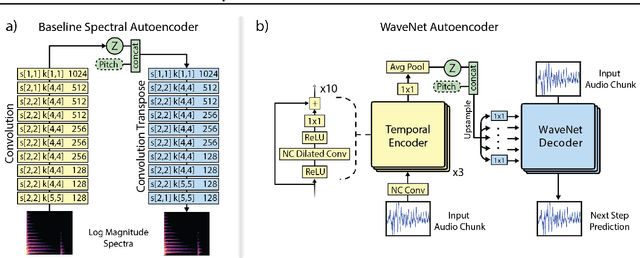
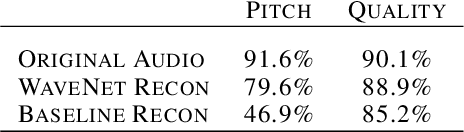

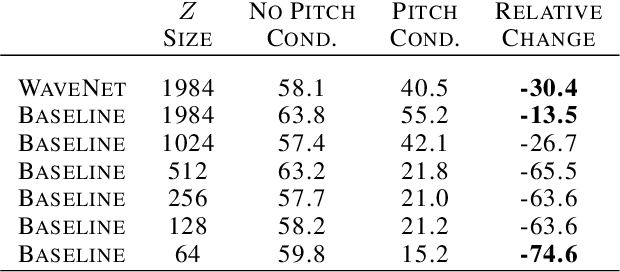
Generative models in vision have seen rapid progress due to algorithmic improvements and the availability of high-quality image datasets. In this paper, we offer contributions in both these areas to enable similar progress in audio modeling. First, we detail a powerful new WaveNet-style autoencoder model that conditions an autoregressive decoder on temporal codes learned from the raw audio waveform. Second, we introduce NSynth, a large-scale and high-quality dataset of musical notes that is an order of magnitude larger than comparable public datasets. Using NSynth, we demonstrate improved qualitative and quantitative performance of the WaveNet autoencoder over a well-tuned spectral autoencoder baseline. Finally, we show that the model learns a manifold of embeddings that allows for morphing between instruments, meaningfully interpolating in timbre to create new types of sounds that are realistic and expressive.
Neural Machine Translation in Linear Time
Mar 15, 2017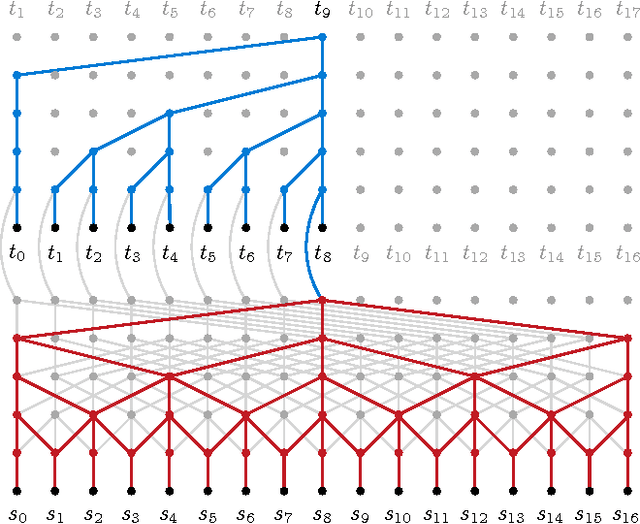
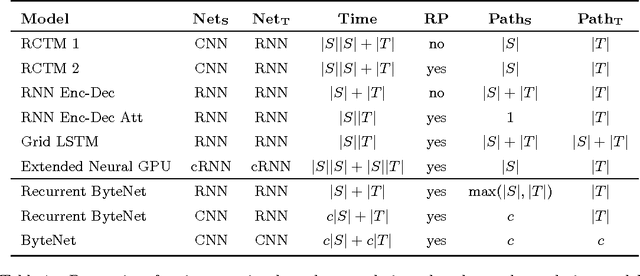


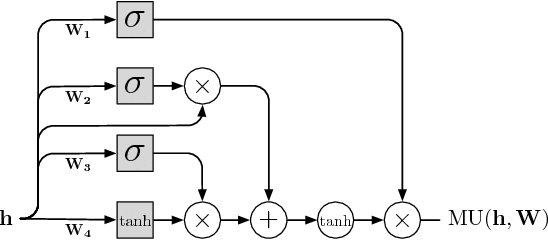
We present a novel neural network for processing sequences. The ByteNet is a one-dimensional convolutional neural network that is composed of two parts, one to encode the source sequence and the other to decode the target sequence. The two network parts are connected by stacking the decoder on top of the encoder and preserving the temporal resolution of the sequences. To address the differing lengths of the source and the target, we introduce an efficient mechanism by which the decoder is dynamically unfolded over the representation of the encoder. The ByteNet uses dilation in the convolutional layers to increase its receptive field. The resulting network has two core properties: it runs in time that is linear in the length of the sequences and it sidesteps the need for excessive memorization. The ByteNet decoder attains state-of-the-art performance on character-level language modelling and outperforms the previous best results obtained with recurrent networks. The ByteNet also achieves state-of-the-art performance on character-to-character machine translation on the English-to-German WMT translation task, surpassing comparable neural translation models that are based on recurrent networks with attentional pooling and run in quadratic time. We find that the latent alignment structure contained in the representations reflects the expected alignment between the tokens.
Video Pixel Networks
Oct 03, 2016


We propose a probabilistic video model, the Video Pixel Network (VPN), that estimates the discrete joint distribution of the raw pixel values in a video. The model and the neural architecture reflect the time, space and color structure of video tensors and encode it as a four-dimensional dependency chain. The VPN approaches the best possible performance on the Moving MNIST benchmark, a leap over the previous state of the art, and the generated videos show only minor deviations from the ground truth. The VPN also produces detailed samples on the action-conditional Robotic Pushing benchmark and generalizes to the motion of novel objects.
WaveNet: A Generative Model for Raw Audio
Sep 19, 2016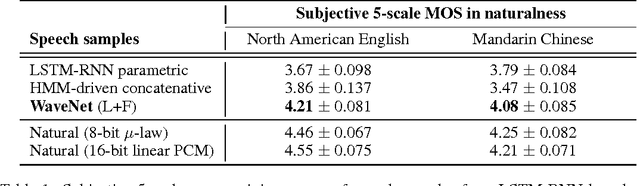
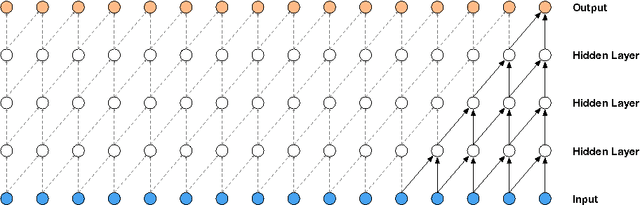
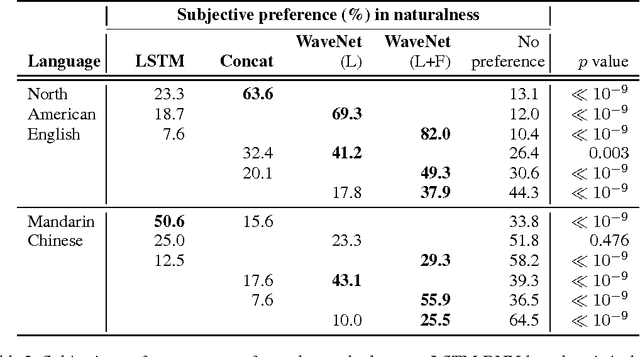
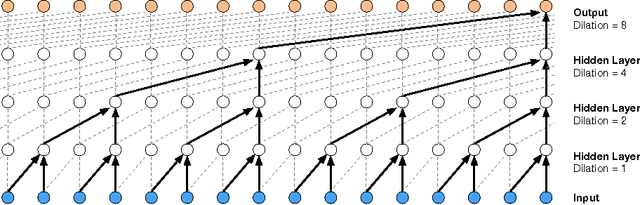
This paper introduces WaveNet, a deep neural network for generating raw audio waveforms. The model is fully probabilistic and autoregressive, with the predictive distribution for each audio sample conditioned on all previous ones; nonetheless we show that it can be efficiently trained on data with tens of thousands of samples per second of audio. When applied to text-to-speech, it yields state-of-the-art performance, with human listeners rating it as significantly more natural sounding than the best parametric and concatenative systems for both English and Mandarin. A single WaveNet can capture the characteristics of many different speakers with equal fidelity, and can switch between them by conditioning on the speaker identity. When trained to model music, we find that it generates novel and often highly realistic musical fragments. We also show that it can be employed as a discriminative model, returning promising results for phoneme recognition.
Spatial Transformer Networks
Feb 04, 2016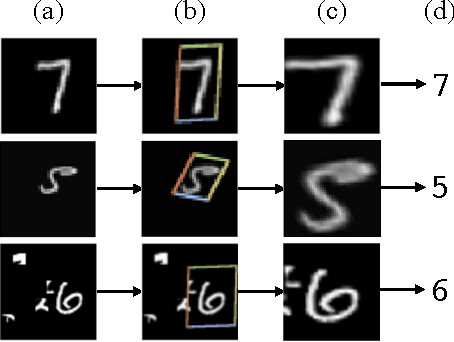
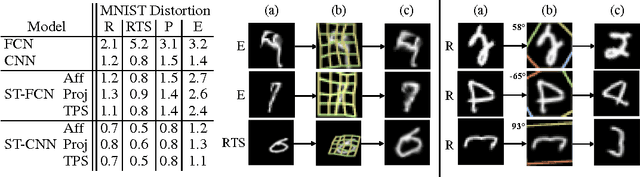
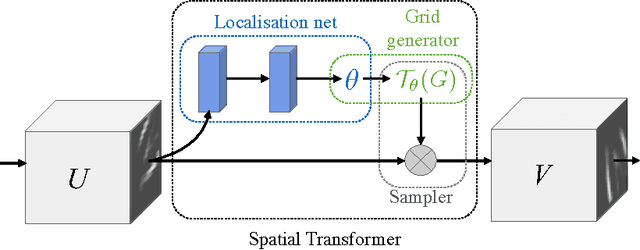
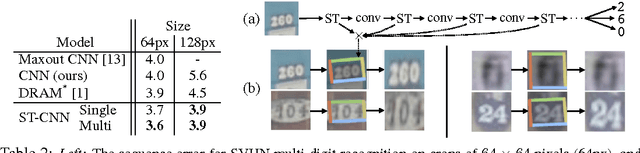
Convolutional Neural Networks define an exceptionally powerful class of models, but are still limited by the lack of ability to be spatially invariant to the input data in a computationally and parameter efficient manner. In this work we introduce a new learnable module, the Spatial Transformer, which explicitly allows the spatial manipulation of data within the network. This differentiable module can be inserted into existing convolutional architectures, giving neural networks the ability to actively spatially transform feature maps, conditional on the feature map itself, without any extra training supervision or modification to the optimisation process. We show that the use of spatial transformers results in models which learn invariance to translation, scale, rotation and more generic warping, resulting in state-of-the-art performance on several benchmarks, and for a number of classes of transformations.
Natural Neural Networks
Jul 01, 2015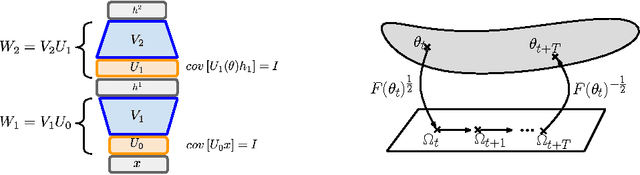

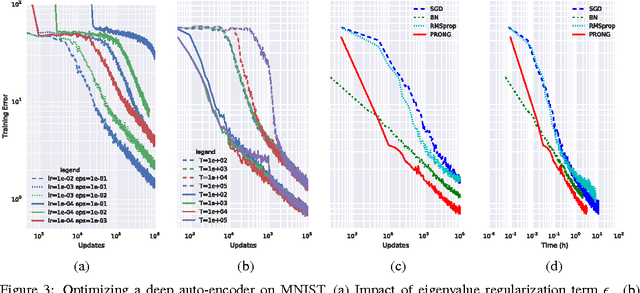
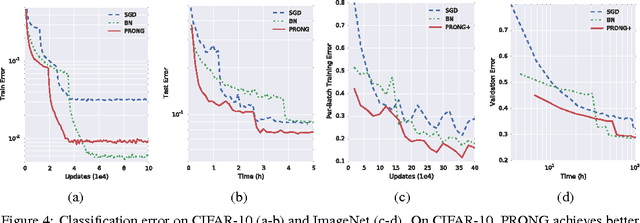
We introduce Natural Neural Networks, a novel family of algorithms that speed up convergence by adapting their internal representation during training to improve conditioning of the Fisher matrix. In particular, we show a specific example that employs a simple and efficient reparametrization of the neural network weights by implicitly whitening the representation obtained at each layer, while preserving the feed-forward computation of the network. Such networks can be trained efficiently via the proposed Projected Natural Gradient Descent algorithm (PRONG), which amortizes the cost of these reparametrizations over many parameter updates and is closely related to the Mirror Descent online learning algorithm. We highlight the benefits of our method on both unsupervised and supervised learning tasks, and showcase its scalability by training on the large-scale ImageNet Challenge dataset.
Very Deep Convolutional Networks for Large-Scale Image Recognition
Apr 10, 2015In this work we investigate the effect of the convolutional network depth on its accuracy in the large-scale image recognition setting. Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3x3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16-19 weight layers. These findings were the basis of our ImageNet Challenge 2014 submission, where our team secured the first and the second places in the localisation and classification tracks respectively. We also show that our representations generalise well to other datasets, where they achieve state-of-the-art results. We have made our two best-performing ConvNet models publicly available to facilitate further research on the use of deep visual representations in computer vision.
Deep Structured Output Learning for Unconstrained Text Recognition
Apr 10, 2015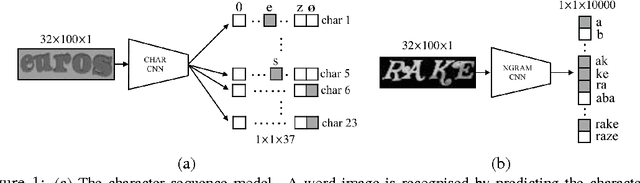
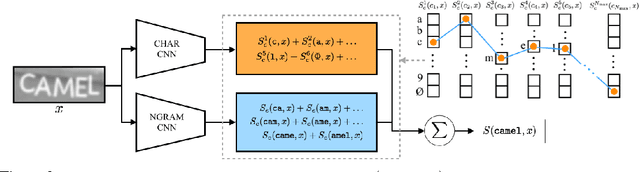
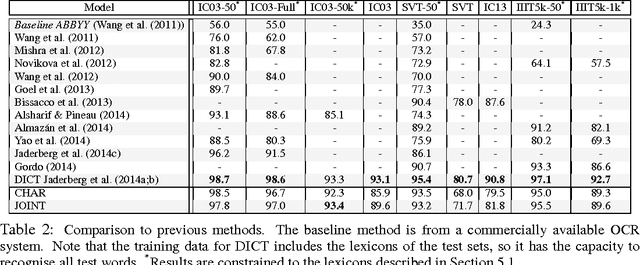
We develop a representation suitable for the unconstrained recognition of words in natural images: the general case of no fixed lexicon and unknown length. To this end we propose a convolutional neural network (CNN) based architecture which incorporates a Conditional Random Field (CRF) graphical model, taking the whole word image as a single input. The unaries of the CRF are provided by a CNN that predicts characters at each position of the output, while higher order terms are provided by another CNN that detects the presence of N-grams. We show that this entire model (CRF, character predictor, N-gram predictor) can be jointly optimised by back-propagating the structured output loss, essentially requiring the system to perform multi-task learning, and training uses purely synthetically generated data. The resulting model is a more accurate system on standard real-world text recognition benchmarks than character prediction alone, setting a benchmark for systems that have not been trained on a particular lexicon. In addition, our model achieves state-of-the-art accuracy in lexicon-constrained scenarios, without being specifically modelled for constrained recognition. To test the generalisation of our model, we also perform experiments with random alpha-numeric strings to evaluate the method when no visual language model is applicable.
Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition
Dec 09, 2014
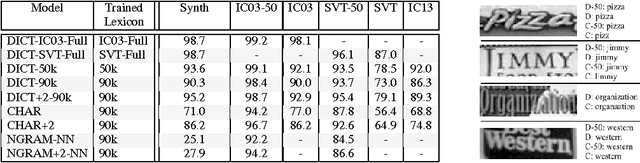
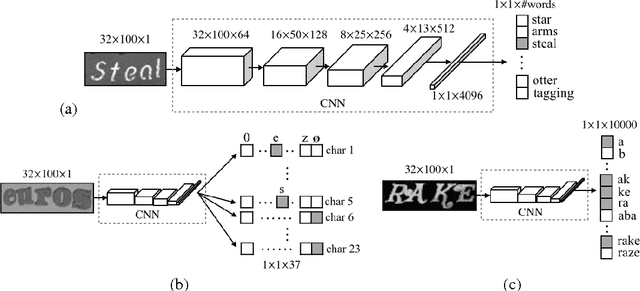
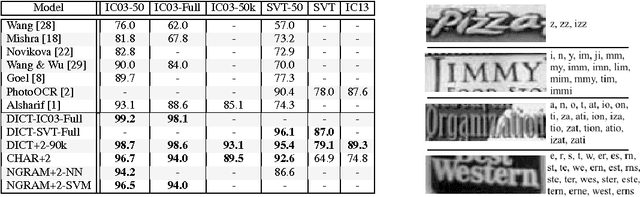
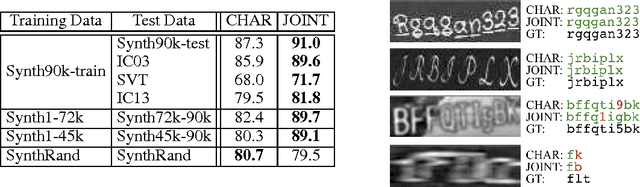
In this work we present a framework for the recognition of natural scene text. Our framework does not require any human-labelled data, and performs word recognition on the whole image holistically, departing from the character based recognition systems of the past. The deep neural network models at the centre of this framework are trained solely on data produced by a synthetic text generation engine -- synthetic data that is highly realistic and sufficient to replace real data, giving us infinite amounts of training data. This excess of data exposes new possibilities for word recognition models, and here we consider three models, each one "reading" words in a different way: via 90k-way dictionary encoding, character sequence encoding, and bag-of-N-grams encoding. In the scenarios of language based and completely unconstrained text recognition we greatly improve upon state-of-the-art performance on standard datasets, using our fast, simple machinery and requiring zero data-acquisition costs.
Reading Text in the Wild with Convolutional Neural Networks
Dec 04, 2014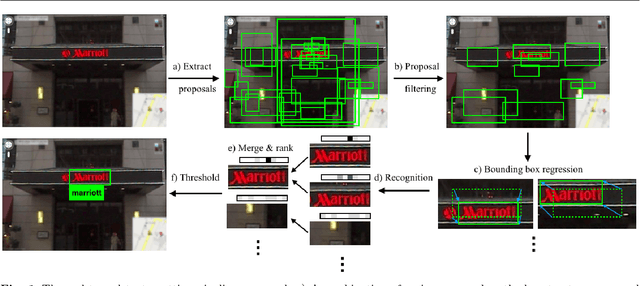
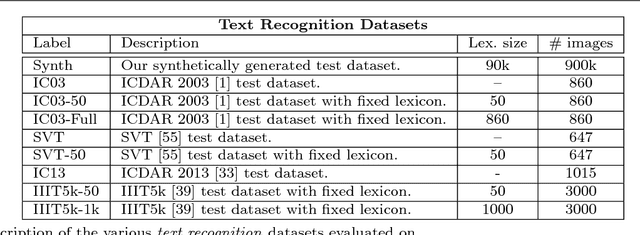

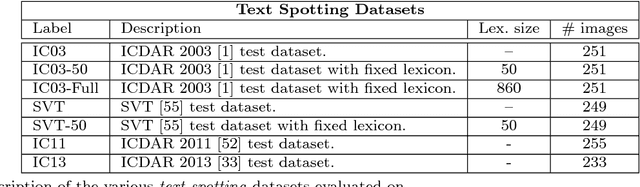
In this work we present an end-to-end system for text spotting -- localising and recognising text in natural scene images -- and text based image retrieval. This system is based on a region proposal mechanism for detection and deep convolutional neural networks for recognition. Our pipeline uses a novel combination of complementary proposal generation techniques to ensure high recall, and a fast subsequent filtering stage for improving precision. For the recognition and ranking of proposals, we train very large convolutional neural networks to perform word recognition on the whole proposal region at the same time, departing from the character classifier based systems of the past. These networks are trained solely on data produced by a synthetic text generation engine, requiring no human labelled data. Analysing the stages of our pipeline, we show state-of-the-art performance throughout. We perform rigorous experiments across a number of standard end-to-end text spotting benchmarks and text-based image retrieval datasets, showing a large improvement over all previous methods. Finally, we demonstrate a real-world application of our text spotting system to allow thousands of hours of news footage to be instantly searchable via a text query.