 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Expense of Seeing: Attaining Trustworthy Multimodal Reasoning Within the Monolithic Paradigm
Apr 22, 2026The rapid proliferation of Vision-Language Models (VLMs) is widely celebrated as the dawn of unified multimodal knowledge discovery but its foundation operates on a dangerous, unquestioned axiom: that current VLMs faithfully synthesise multimodal data. We argue they do not. Instead, a profound crisis of trustworthiness underlies the dominant Vision Encoder-Projector-LLM paradigm. Rather than extracting grounded knowledge from visual inputs, state-of-the-art models frequently exhibit functional blindness, i.e., exploiting strong language priors to bypass severe visual representation bottlenecks. In this work, we challenge the conventional methodology of multimodal evaluation, which relies on data ablation or new dataset creation and therefore fatally conflates dataset biases with architectural incapacity. We propose a radical, information-theoretic departure: the Modality Translation Protocol, designed to quantifiably unmask the Expense of Seeing. By translating semantic payloads rather than ablating them, we formulate three novel metrics -- the Toll (ToS), Curse (CoS), and Fallacy (FoS) of Seeing -- culminating in the Semantic Sufficiency Criterion (SSC). Furthermore, we posit a provocative Divergence Law of Multimodal Scaling, hypothesising that as the underlying language engines scale to unprecedented reasoning capabilities, the mathematical penalty of the visual knowledge bottleneck paradoxically increases. We challenge the KDD community to abandon the illusory pursuit of "multimodal gain". By elevating the SSC from a passive diagnostic constraint to an active architectural blueprint, we provide the rigorous, trustworthy foundation required to force the next generation of AI systems to truly see the data, achieving true multimodal reasoning.
DISSECT: Diagnosing Where Vision Ends and Language Priors Begin in Scientific VLMs
Apr 06, 2026When asked to describe a molecular diagram, a Vision-Language Model correctly identifies ``a benzene ring with an -OH group.'' When asked to reason about the same image, it answers incorrectly. The model can see but it cannot think about what it sees. We term this the perception-integration gap: a failure where visual information is successfully extracted but lost during downstream reasoning, invisible to single-configuration benchmarks that conflate perception with integration under one accuracy number. To systematically expose such failures, we introduce DISSECT, a 12,000-question diagnostic benchmark spanning Chemistry (7,000) and Biology (5,000). Every question is evaluated under five input modes -- Vision+Text, Text-Only, Vision-Only, Human Oracle, and a novel Model Oracle in which the VLM first verbalizes the image and then reasons from its own description -- yielding diagnostic gaps that decompose performance into language-prior exploitation, visual extraction, perception fidelity, and integration effectiveness. Evaluating 18~VLMs, we find that: (1) Chemistry exhibits substantially lower language-prior exploitability than Biology, confirming molecular visual content as a harder test of genuine visual reasoning; (2) Open-source models consistently score higher when reasoning from their own verbalized descriptions than from raw images, exposing a systematic integration bottleneck; and (3) Closed-source models show no such gap, indicating that bridging perception and integration is the frontier separating open-source from closed-source multimodal capability. The Model Oracle protocol is both model and benchmark agnostic, applicable post-hoc to any VLM evaluation to diagnose integration failures.
CAGE: Bridging the Accuracy-Aesthetics Gap in Educational Diagrams via Code-Anchored Generative Enhancement
Apr 06, 2026Educational diagrams -- labeled illustrations of biological processes, chemical structures, physical systems, and mathematical concepts -- are essential cognitive tools in K-12 instruction. Yet no existing method can generate them both accurately and engagingly. Open-source diffusion models produce visually rich images but catastrophically garble text labels. Code-based generation via LLMs guarantees label correctness but yields visually flat outputs. Closed-source APIs partially bridge this gap but remain unreliable and prohibitively expensive at educational scale. We quantify this accuracy-aesthetics dilemma across all three paradigms on 400 K-12 diagram prompts, measuring both label fidelity and visual quality through complementary automated and human evaluation protocols. To resolve it, we propose CAGE (Code-Anchored Generative Enhancement): an LLM synthesizes executable code producing a structurally correct diagram, then a diffusion model conditioned on the programmatic output via ControlNet refines it into a visually polished graphic while preserving label fidelity. We also introduce EduDiagram-2K, a collection of 2,000 paired programmatic-stylized diagrams enabling this pipeline, and present proof-of-concept results and a research agenda for the multimedia community.
Public Profile Matters: A Scalable Integrated Approach to Recommend Citations in the Wild
Mar 18, 2026Proper citation of relevant literature is essential for contextualising and validating scientific contributions. While current citation recommendation systems leverage local and global textual information, they often overlook the nuances of the human citation behaviour. Recent methods that incorporate such patterns improve performance but incur high computational costs and introduce systematic biases into downstream rerankers. To address this, we propose Profiler, a lightweight, non-learnable module that captures human citation patterns efficiently and without bias, significantly enhancing candidate retrieval. Furthermore, we identify a critical limitation in current evaluation protocol: the systems are assessed in a transductive setting, which fails to reflect real-world scenarios. We introduce a rigorous Inductive evaluation setting that enforces strict temporal constraints, simulating the recommendation of citations for newly authored papers in the wild. Finally, we present DAVINCI, a novel reranking model that integrates profiler-derived confidence priors with semantic information via an adaptive vector-gating mechanism. Our system achieves new state-of-the-art results across multiple benchmark datasets, demonstrating superior efficiency and generalisability.
SymTax: Symbiotic Relationship and Taxonomy Fusion for Effective Citation Recommendation
May 26, 2024



Citing pertinent literature is pivotal to writing and reviewing a scientific document. Existing techniques mainly focus on the local context or the global context for recommending citations but fail to consider the actual human citation behaviour. We propose SymTax, a three-stage recommendation architecture that considers both the local and the global context, and additionally the taxonomical representations of query-candidate tuples and the Symbiosis prevailing amongst them. SymTax learns to embed the infused taxonomies in the hyperbolic space and uses hyperbolic separation as a latent feature to compute query-candidate similarity. We build a novel and large dataset ArSyTa containing 8.27 million citation contexts and describe the creation process in detail. We conduct extensive experiments and ablation studies to demonstrate the effectiveness and design choice of each module in our framework. Also, combinatorial analysis from our experiments shed light on the choice of language models (LMs) and fusion embedding, and the inclusion of section heading as a signal. Our proposed module that captures the symbiotic relationship solely leads to performance gains of 26.66% and 39.25% in Recall@5 w.r.t. SOTA on ACL-200 and RefSeer datasets, respectively. The complete framework yields a gain of 22.56% in Recall@5 wrt SOTA on our proposed dataset. The code and dataset are available at https://github.com/goyalkaraniit/SymTax
A Novel Framework for Neural Architecture Search in the Hill Climbing Domain
Feb 22, 2021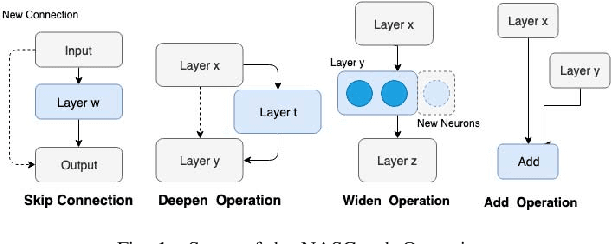
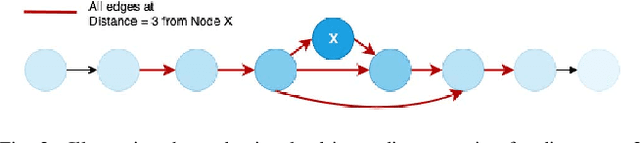
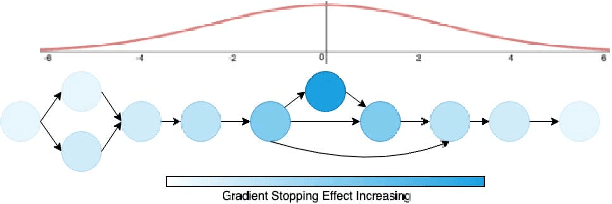
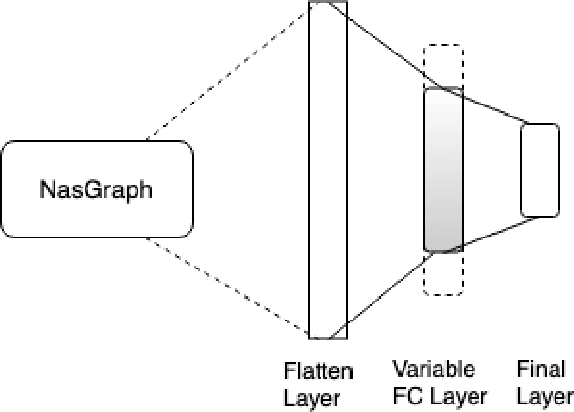
Neural networks have now long been used for solving complex problems of image domain, yet designing the same needs manual expertise. Furthermore, techniques for automatically generating a suitable deep learning architecture for a given dataset have frequently made use of reinforcement learning and evolutionary methods which take extensive computational resources and time. We propose a new framework for neural architecture search based on a hill-climbing procedure using morphism operators that makes use of a novel gradient update scheme. The update is based on the aging of neural network layers and results in the reduction in the overall training time. This technique can search in a broader search space which subsequently yields competitive results. We achieve a 4.96% error rate on the CIFAR-10 dataset in 19.4 hours of a single GPU training.