 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating novel experimental hypotheses from language models: A case study on cross-dative generalization
Aug 09, 2024



Neural network language models (LMs) have been shown to successfully capture complex linguistic knowledge. However, their utility for understanding language acquisition is still debated. We contribute to this debate by presenting a case study where we use LMs as simulated learners to derive novel experimental hypotheses to be tested with humans. We apply this paradigm to study cross-dative generalization (CDG): productive generalization of novel verbs across dative constructions (she pilked me the ball/she pilked the ball to me) -- acquisition of which is known to involve a large space of contextual features -- using LMs trained on child-directed speech. We specifically ask: "what properties of the training exposure facilitate a novel verb's generalization to the (unmodeled) alternate construction?" To answer this, we systematically vary the exposure context in which a novel dative verb occurs in terms of the properties of the theme and recipient, and then analyze the LMs' usage of the novel verb in the unmodeled dative construction. We find LMs to replicate known patterns of children's CDG, as a precondition to exploring novel hypotheses. Subsequent simulations reveal a nuanced role of the features of the novel verbs' exposure context on the LMs' CDG. We find CDG to be facilitated when the first postverbal argument of the exposure context is pronominal, definite, short, and conforms to the prototypical animacy expectations of the exposure dative. These patterns are characteristic of harmonic alignment in datives, where the argument with features ranking higher on the discourse prominence scale tends to precede the other. This gives rise to a novel hypothesis that CDG is facilitated insofar as the features of the exposure context -- in particular, its first postverbal argument -- are harmonically aligned. We conclude by proposing future experiments that can test this hypothesis in children.
Language Models Learn Rare Phenomena from Less Rare Phenomena: The Case of the Missing AANNs
Mar 28, 2024



Language models learn rare syntactic phenomena, but it has been argued that they rely on rote memorization, as opposed to grammatical generalization. Training on a corpus of human-scale in size (100M words), we iteratively trained transformer language models on systematically manipulated corpora and then evaluated their learning of a particular rare grammatical phenomenon: the English Article+Adjective+Numeral+Noun (AANN) construction (``a beautiful five days''). We first compared how well this construction was learned on the default corpus relative to a counterfactual corpus in which the AANN sentences were removed. AANNs were still learned better than systematically perturbed variants of the construction. Using additional counterfactual corpora, we suggest that this learning occurs through generalization from related constructions (e.g., ``a few days''). An additional experiment showed that this learning is enhanced when there is more variability in the input. Taken together, our results provide an existence proof that models learn rare grammatical phenomena by generalization from less rare phenomena. Code available at https://github.com/kanishkamisra/aannalysis
Experimental Contexts Can Facilitate Robust Semantic Property Inference in Language Models, but Inconsistently
Jan 12, 2024



Recent zero-shot evaluations have highlighted important limitations in the abilities of language models (LMs) to perform meaning extraction. However, it is now well known that LMs can demonstrate radical improvements in the presence of experimental contexts such as in-context examples and instructions. How well does this translate to previously studied meaning-sensitive tasks? We present a case-study on the extent to which experimental contexts can improve LMs' robustness in performing property inheritance -- predicting semantic properties of novel concepts, a task that they have been previously shown to fail on. Upon carefully controlling the nature of the in-context examples and the instructions, our work reveals that they can indeed lead to non-trivial property inheritance behavior in LMs. However, this ability is inconsistent: with a minimal reformulation of the task, some LMs were found to pick up on shallow, non-semantic heuristics from their inputs, suggesting that the computational principles of semantic property inference are yet to be mastered by LMs.
Triggering Multi-Hop Reasoning for Question Answering in Language Models using Soft Prompts and Random Walks
Jun 06, 2023



Despite readily memorizing world knowledge about entities, pre-trained language models (LMs) struggle to compose together two or more facts to perform multi-hop reasoning in question-answering tasks. In this work, we propose techniques that improve upon this limitation by relying on random walks over structured knowledge graphs. Specifically, we use soft prompts to guide LMs to chain together their encoded knowledge by learning to map multi-hop questions to random walk paths that lead to the answer. Applying our methods on two T5 LMs shows substantial improvements over standard tuning approaches in answering questions that require 2-hop reasoning.
Large Language Models Can Be Easily Distracted by Irrelevant Context
Feb 13, 2023



Large language models have achieved impressive performance on various natural language processing tasks. However, so far they have been evaluated primarily on benchmarks where all information in the input context is relevant for solving the task. In this work, we investigate the distractibility of large language models, i.e., how the model problem-solving accuracy can be influenced by irrelevant context. In particular, we introduce Grade-School Math with Irrelevant Context (GSM-IC), an arithmetic reasoning dataset with irrelevant information in the problem description. We use this benchmark to measure the distractibility of cutting-edge prompting techniques for large language models, and find that the model performance is dramatically decreased when irrelevant information is included. We also identify several approaches for mitigating this deficiency, such as decoding with self-consistency and adding to the prompt an instruction that tells the language model to ignore the irrelevant information.
Language model acceptability judgements are not always robust to context
Dec 18, 2022Targeted syntactic evaluations of language models ask whether models show stable preferences for syntactically acceptable content over minimal-pair unacceptable inputs. Most targeted syntactic evaluation datasets ask models to make these judgements with just a single context-free sentence as input. This does not match language models' training regime, in which input sentences are always highly contextualized by the surrounding corpus. This mismatch raises an important question: how robust are models' syntactic judgements in different contexts? In this paper, we investigate the stability of language models' performance on targeted syntactic evaluations as we vary properties of the input context: the length of the context, the types of syntactic phenomena it contains, and whether or not there are violations of grammaticality. We find that model judgements are generally robust when placed in randomly sampled linguistic contexts. However, they are substantially unstable for contexts containing syntactic structures matching those in the critical test content. Among all tested models (GPT-2 and five variants of OPT), we significantly improve models' judgements by providing contexts with matching syntactic structures, and conversely significantly worsen them using unacceptable contexts with matching but violated syntactic structures. This effect is amplified by the length of the context, except for unrelated inputs. We show that these changes in model performance are not explainable by simple features matching the context and the test inputs, such as lexical overlap and dependency overlap. This sensitivity to highly specific syntactic features of the context can only be explained by the models' implicit in-context learning abilities.
COMPS: Conceptual Minimal Pair Sentences for testing Property Knowledge and Inheritance in Pre-trained Language Models
Oct 06, 2022
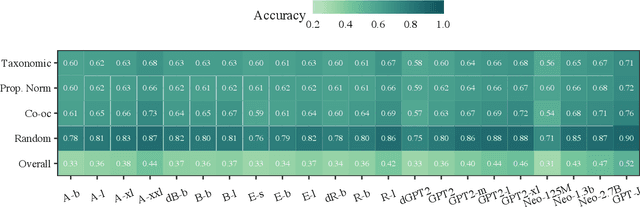

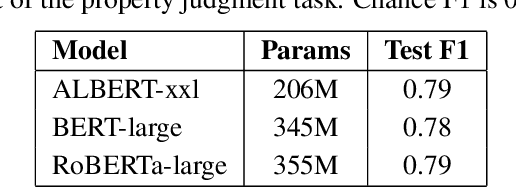
A characteristic feature of human semantic memory is its ability to not only store and retrieve the properties of concepts observed through experience, but to also facilitate the inheritance of properties (can breathe) from superordinate concepts (animal) to their subordinates (dog) -- i.e. demonstrate property inheritance. In this paper, we present COMPS, a collection of minimal pair sentences that jointly tests pre-trained language models (PLMs) on their ability to attribute properties to concepts and their ability to demonstrate property inheritance behavior. Analyses of 22 different PLMs on COMPS reveal that they can easily distinguish between concepts on the basis of a property when they are trivially different, but find it relatively difficult when concepts are related on the basis of nuanced knowledge representations. Furthermore, we find that PLMs can demonstrate behavior consistent with property inheritance to a great extent, but fail in the presence of distracting information, which decreases the performance of many models, sometimes even below chance. This lack of robustness in demonstrating simple reasoning raises important questions about PLMs' capacity to make correct inferences even when they appear to possess the prerequisite knowledge.
A Property Induction Framework for Neural Language Models
May 13, 2022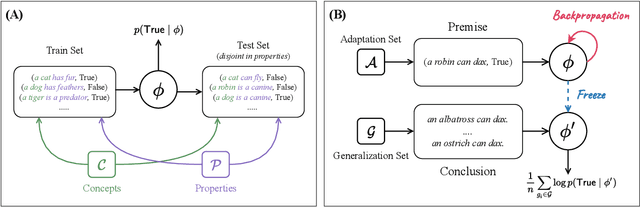
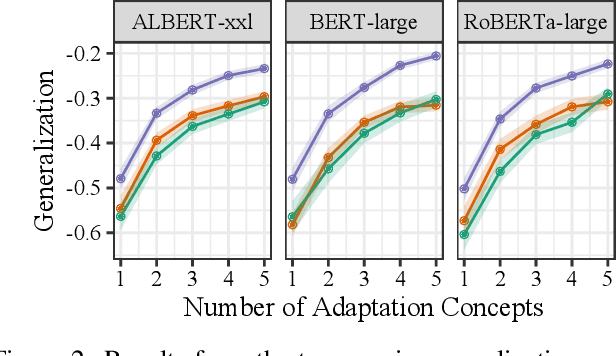
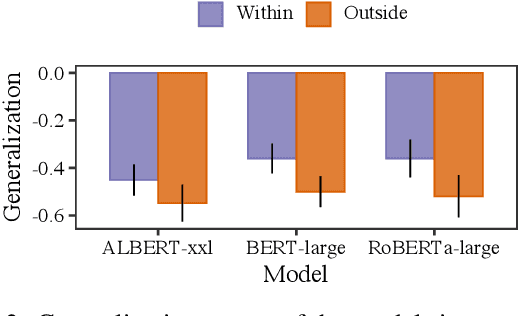
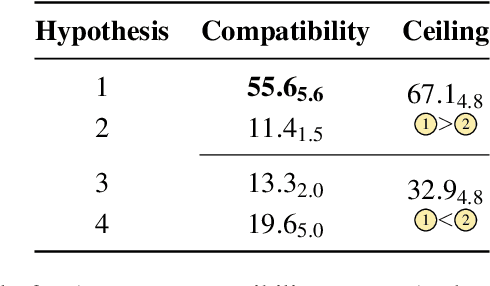
To what extent can experience from language contribute to our conceptual knowledge? Computational explorations of this question have shed light on the ability of powerful neural language models (LMs) -- informed solely through text input -- to encode and elicit information about concepts and properties. To extend this line of research, we present a framework that uses neural-network language models (LMs) to perform property induction -- a task in which humans generalize novel property knowledge (has sesamoid bones) from one or more concepts (robins) to others (sparrows, canaries). Patterns of property induction observed in humans have shed considerable light on the nature and organization of human conceptual knowledge. Inspired by this insight, we use our framework to explore the property inductions of LMs, and find that they show an inductive preference to generalize novel properties on the basis of category membership, suggesting the presence of a taxonomic bias in their representations.
minicons: Enabling Flexible Behavioral and Representational Analyses of Transformer Language Models
Mar 24, 2022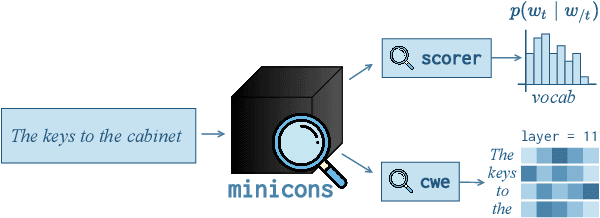
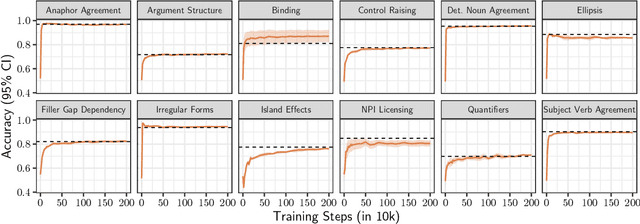
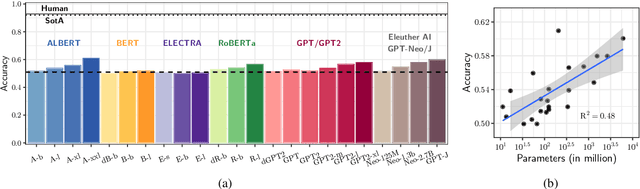
We present minicons, an open source library that provides a standard API for researchers interested in conducting behavioral and representational analyses of transformer-based language models (LMs). Specifically, minicons enables researchers to apply analysis methods at two levels: (1) at the prediction level -- by providing functions to efficiently extract word/sentence level probabilities; and (2) at the representational level -- by also facilitating efficient extraction of word/phrase level vectors from one or more layers. In this paper, we describe the library and apply it to two motivating case studies: One focusing on the learning dynamics of the BERT architecture on relative grammatical judgments, and the other on benchmarking 23 different LMs on zero-shot abductive reasoning. minicons is available at https://github.com/kanishkamisra/minicons
On Semantic Cognition, Inductive Generalization, and Language Models
Nov 04, 2021
My doctoral research focuses on understanding semantic knowledge in neural network models trained solely to predict natural language (referred to as language models, or LMs), by drawing on insights from the study of concepts and categories grounded in cognitive science. I propose a framework inspired by 'inductive reasoning,' a phenomenon that sheds light on how humans utilize background knowledge to make inductive leaps and generalize from new pieces of information about concepts and their properties. Drawing from experiments that study inductive reasoning, I propose to analyze semantic inductive generalization in LMs using phenomena observed in human-induction literature, investigate inductive behavior on tasks such as implicit reasoning and emergent feature recognition, and analyze and relate induction dynamics to the learned conceptual representation space.