 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoltzina: Efficient and Accurate Virtual Screening via Docking-Guided Binding Prediction with Boltz-2
Aug 24, 2025In structure-based drug discovery, virtual screening using conventional molecular docking methods can be performed rapidly but suffers from limitations in prediction accuracy. Recently, Boltz-2 was proposed, achieving extremely high accuracy in binding affinity prediction, but requiring approximately 20 seconds per compound per GPU, making it difficult to apply to large-scale screening of hundreds of thousands to millions of compounds. This study proposes Boltzina, a novel framework that leverages Boltz-2's high accuracy while significantly improving computational efficiency. Boltzina achieves both accuracy and speed by omitting the rate-limiting structure prediction from Boltz-2's architecture and directly predicting affinity from AutoDock Vina docking poses. We evaluate on eight assays from the MF-PCBA dataset and show that while Boltzina performs below Boltz-2, it provides significantly higher screening performance compared to AutoDock Vina and GNINA. Additionally, Boltzina achieved up to 11.8$\times$ faster through reduced recycling iterations and batch processing. Furthermore, we investigated multi-pose selection strategies and two-stage screening combining Boltzina and Boltz-2, presenting optimization methods for accuracy and efficiency according to application requirements. This study represents the first attempt to apply Boltz-2's high-accuracy predictions to practical-scale screening, offering a pipeline that combines both accuracy and efficiency in computational biology. The Boltzina is available on github; https://github.com/ohuelab/boltzina.
NPGPT: Natural Product-Like Compound Generation with GPT-based Chemical Language Models
Nov 19, 2024Natural products are substances produced by organisms in nature and often possess biological activity and structural diversity. Drug development based on natural products has been common for many years. However, the intricate structures of these compounds present challenges in terms of structure determination and synthesis, particularly compared to the efficiency of high-throughput screening of synthetic compounds. In recent years, deep learning-based methods have been applied to the generation of molecules. In this study, we trained chemical language models on a natural product dataset and generated natural product-like compounds. The results showed that the distribution of the compounds generated was similar to that of natural products. We also evaluated the effectiveness of the generated compounds as drug candidates. Our method can be used to explore the vast chemical space and reduce the time and cost of drug discovery of natural products.
Active learning for energy-based antibody optimization and enhanced screening
Sep 18, 2024Accurate prediction and optimization of protein-protein binding affinity is crucial for therapeutic antibody development. Although machine learning-based prediction methods $\Delta\Delta G$ are suitable for large-scale mutant screening, they struggle to predict the effects of multiple mutations for targets without existing binders. Energy function-based methods, though more accurate, are time consuming and not ideal for large-scale screening. To address this, we propose an active learning workflow that efficiently trains a deep learning model to learn energy functions for specific targets, combining the advantages of both approaches. Our method integrates the RDE-Network deep learning model with Rosetta's energy function-based Flex ddG to efficiently explore mutants. In a case study targeting HER2-binding Trastuzumab mutants, our approach significantly improved the screening performance over random selection and demonstrated the ability to identify mutants with better binding properties without experimental $\Delta\Delta G$ data. This workflow advances computational antibody design by combining machine learning, physics-based computations, and active learning to achieve more efficient antibody development.
Compound virtual screening by learning-to-rank with gradient boosting decision tree and enrichment-based cumulative gain
May 04, 2022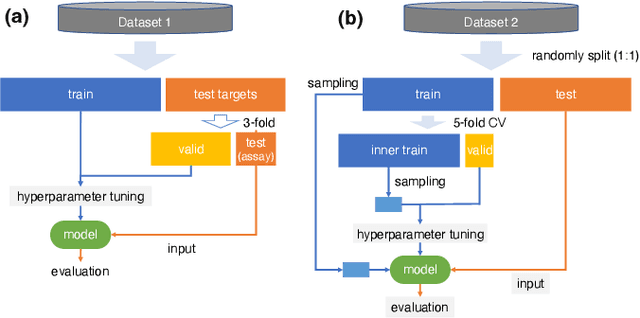
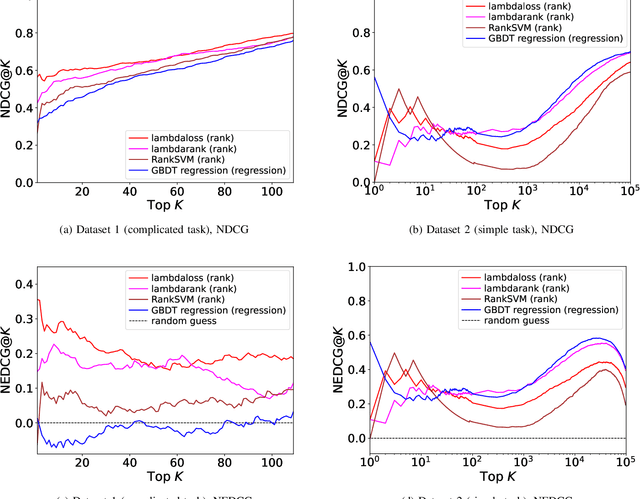
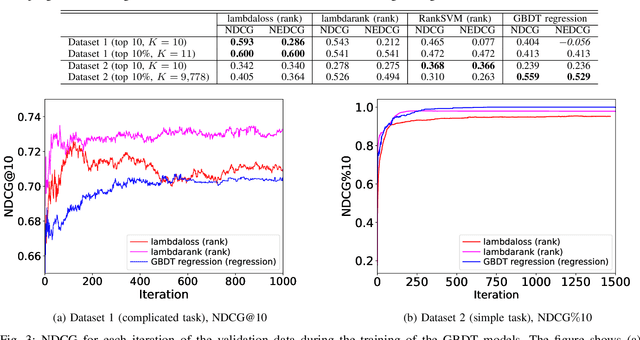
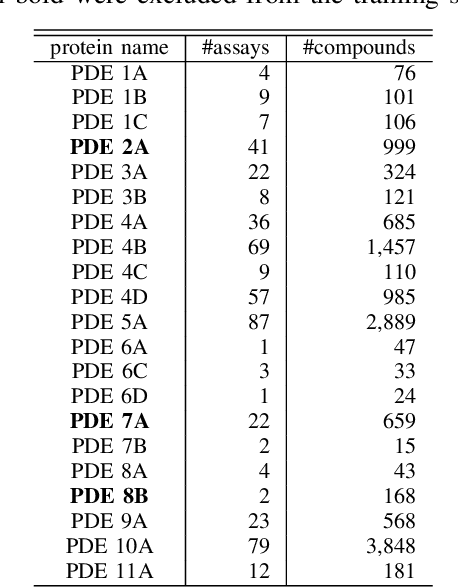
Learning-to-rank, a machine learning technique widely used in information retrieval, has recently been applied to the problem of ligand-based virtual screening, to accelerate the early stages of new drug development. Ranking prediction models learn based on ordinal relationships, making them suitable for integrating assay data from various environments. Existing studies of rank prediction in compound screening have generally used a learning-to-rank method called RankSVM. However, they have not been compared with or validated against the gradient boosting decision tree (GBDT)-based learning-to-rank methods that have gained popularity recently. Furthermore, although the ranking metric called Normalized Discounted Cumulative Gain (NDCG) is widely used in information retrieval, it only determines whether the predictions are better than those of other models. In other words, NDCG is incapable of recognizing when a prediction model produces worse than random results. Nevertheless, NDCG is still used in the performance evaluation of compound screening using learning-to-rank. This study used the GBDT model with ranking loss functions, called lambdarank and lambdaloss, for ligand-based virtual screening; results were compared with existing RankSVM methods and GBDT models using regression. We also proposed a new ranking metric, Normalized Enrichment Discounted Cumulative Gain (NEDCG), which aims to properly evaluate the goodness of ranking predictions. Results showed that the GBDT model with learning-to-rank outperformed existing regression methods using GBDT and RankSVM on diverse datasets. Moreover, NEDCG showed that predictions by regression were comparable to random predictions in multi-assay, multi-family datasets, demonstrating its usefulness for a more direct assessment of compound screening performance.