 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Hidden in Gradients of Regression with Target Noise
Jan 26, 2026Second-order information -- such as curvature or data covariance -- is critical for optimisation, diagnostics, and robustness. However, in many modern settings, only the gradients are observable. We show that the gradients alone can reveal the Hessian, equalling the data covariance $Σ$ for the linear regression. Our key insight is a simple variance calibration: injecting Gaussian noise so that the total target noise variance equals the batch size ensures that the empirical gradient covariance closely approximates the Hessian, even when evaluated far from the optimum. We provide non-asymptotic operator-norm guarantees under sub-Gaussian inputs. We also show that without such calibration, recovery can fail by an $Ω(1)$ factor. The proposed method is practical (a "set target-noise variance to $n$" rule) and robust (variance $\mathcal{O}(n)$ suffices to recover $Σ$ up to scale). Applications include preconditioning for faster optimisation, adversarial risk estimation, and gradient-only training, for example, in distributed systems. We support our theoretical results with experiments on synthetic and real data.
GRADSTOP: Early Stopping of Gradient Descent via Posterior Sampling
Aug 27, 2025



Machine learning models are often learned by minimising a loss function on the training data using a gradient descent algorithm. These models often suffer from overfitting, leading to a decline in predictive performance on unseen data. A standard solution is early stopping using a hold-out validation set, which halts the minimisation when the validation loss stops decreasing. However, this hold-out set reduces the data available for training. This paper presents GRADSTOP, a novel stochastic early stopping method that only uses information in the gradients, which are produced by the gradient descent algorithm ``for free.'' Our main contributions are that we estimate the Bayesian posterior by the gradient information, define the early stopping problem as drawing sample from this posterior, and use the approximated posterior to obtain a stopping criterion. Our empirical evaluation shows that GRADSTOP achieves a small loss on test data and compares favourably to a validation-set-based stopping criterion. By leveraging the entire dataset for training, our method is particularly advantageous in data-limited settings, such as transfer learning. It can be incorporated as an optional feature in gradient descent libraries with only a small computational overhead. The source code is available at https://github.com/edahelsinki/gradstop.
Non-geodesically-convex optimization in the Wasserstein space
Jun 01, 2024
We study a class of optimization problems in the Wasserstein space (the space of probability measures) where the objective function is \emph{nonconvex} along generalized geodesics. When the regularization term is the negative entropy, the optimization problem becomes a sampling problem where it minimizes the Kullback-Leibler divergence between a probability measure (optimization variable) and a target probability measure whose logarithmic probability density is a nonconvex function. We derive multiple convergence insights for a novel {\em semi Forward-Backward Euler scheme} under several nonconvex (and possibly nonsmooth) regimes. Notably, the semi Forward-Backward Euler is just a slight modification of the Forward-Backward Euler whose convergence is -- to our knowledge -- still unknown in our very general non-geodesically-convex setting.
Gradient Boosting Mapping for Dimensionality Reduction and Feature Extraction
May 14, 2024



A fundamental problem in supervised learning is to find a good set of features or distance measures. If the new set of features is of lower dimensionality and can be obtained by a simple transformation of the original data, they can make the model understandable, reduce overfitting, and even help to detect distribution drift. We propose a supervised dimensionality reduction method Gradient Boosting Mapping (GBMAP), where the outputs of weak learners -- defined as one-layer perceptrons -- define the embedding. We show that the embedding coordinates provide better features for the supervised learning task, making simple linear models competitive with the state-of-the-art regressors and classifiers. We also use the embedding to find a principled distance measure between points. The features and distance measures automatically ignore directions irrelevant to the supervised learning task. We also show that we can reliably detect out-of-distribution data points with potentially large regression or classification errors. GBMAP is fast and works in seconds for dataset of million data points or hundreds of features. As a bonus, GBMAP provides a regression and classification performance comparable to the state-of-the-art supervised learning methods.
Using Slisemap to interpret physical data
Oct 24, 2023



Manifold visualisation techniques are commonly used to visualise high-dimensional datasets in physical sciences. In this paper we apply a recently introduced manifold visualisation method, called Slise, on datasets from physics and chemistry. Slisemap combines manifold visualisation with explainable artificial intelligence. Explainable artificial intelligence is used to investigate the decision processes of black box machine learning models and complex simulators. With Slisemap we find an embedding such that data items with similar local explanations are grouped together. Hence, Slisemap gives us an overview of the different behaviours of a black box model. This makes Slisemap into a supervised manifold visualisation method, where the patterns in the embedding reflect a target property. In this paper we show how Slisemap can be used and evaluated on physical data and that Slisemap is helpful in finding meaningful information on classification and regression models trained on these datasets.
SLISEMAP: Explainable Dimensionality Reduction
Jan 12, 2022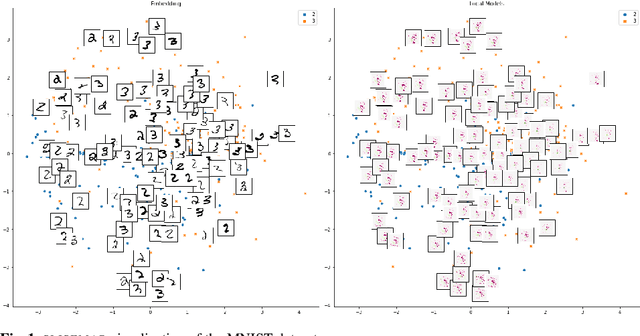
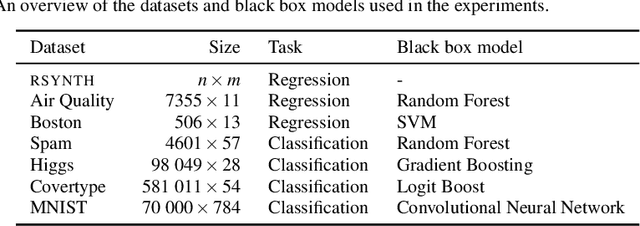
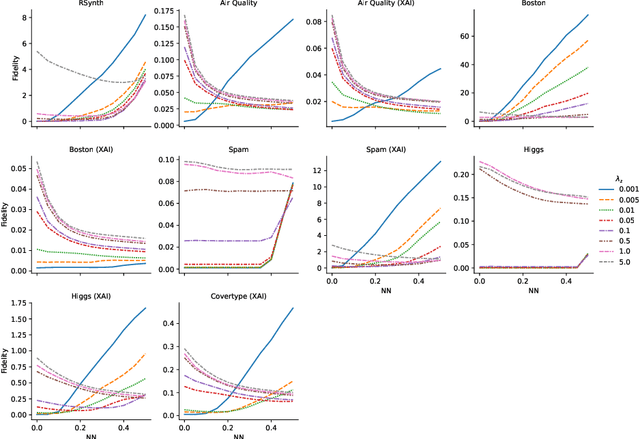
Existing explanation methods for black-box supervised learning models generally work by building local models that explain the models behaviour for a particular data item. It is possible to make global explanations, but the explanations may have low fidelity for complex models. Most of the prior work on explainable models has been focused on classification problems, with less attention on regression. We propose a new manifold visualization method, SLISEMAP, that at the same time finds local explanations for all of the data items and builds a two-dimensional visualization of model space such that the data items explained by the same model are projected nearby. We provide an open source implementation of our methods, implemented by using GPU-optimized PyTorch library. SLISEMAP works both on classification and regression models. We compare SLISEMAP to most popular dimensionality reduction methods and some local explanation methods. We provide mathematical derivation of our problem and show that SLISEMAP provides fast and stable visualizations that can be used to explain and understand black box regression and classification models.
Interactive Causal Structure Discovery in Earth System Sciences
Jul 01, 2021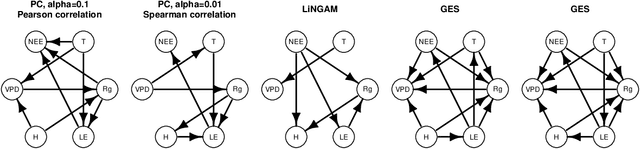
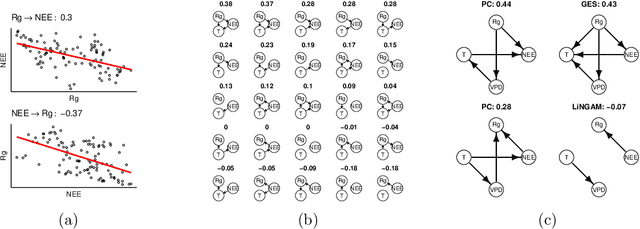
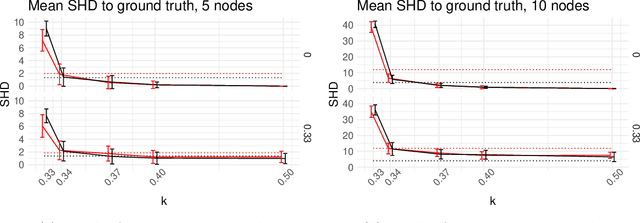
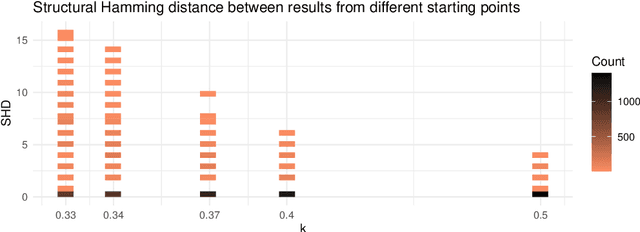
Causal structure discovery (CSD) models are making inroads into several domains, including Earth system sciences. Their widespread adaptation is however hampered by the fact that the resulting models often do not take into account the domain knowledge of the experts and that it is often necessary to modify the resulting models iteratively. We present a workflow that is required to take this knowledge into account and to apply CSD algorithms in Earth system sciences. At the same time, we describe open research questions that still need to be addressed. We present a way to interactively modify the outputs of the CSD algorithms and argue that the user interaction can be modelled as a greedy finding of the local maximum-a-posteriori solution of the likelihood function, which is composed of the likelihood of the causal model and the prior distribution representing the knowledge of the expert user. We use a real-world data set for examples constructed in collaboration with our co-authors, who are the domain area experts. We show that finding maximally usable causal models in the Earth system sciences or other similar domains is a difficult task which contains many interesting open research questions. We argue that taking the domain knowledge into account has a substantial effect on the final causal models discovered.
Tell Me Something I Don't Know: Randomization Strategies for Iterative Data Mining
Jun 16, 2020
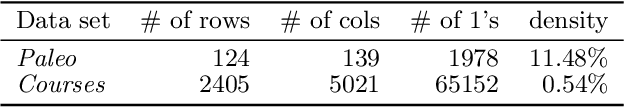
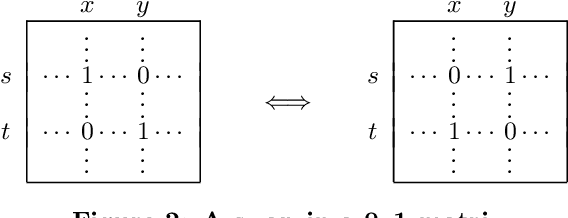

There is a wide variety of data mining methods available, and it is generally useful in exploratory data analysis to use many different methods for the same dataset. This, however, leads to the problem of whether the results found by one method are a reflection of the phenomenon shown by the results of another method, or whether the results depict in some sense unrelated properties of the data. For example, using clustering can give indication of a clear cluster structure, and computing correlations between variables can show that there are many significant correlations in the data. However, it can be the case that the correlations are actually determined by the cluster structure. In this paper, we consider the problem of randomizing data so that previously discovered patterns or models are taken into account. The randomization methods can be used in iterative data mining. At each step in the data mining process, the randomization produces random samples from the set of data matrices satisfying the already discovered patterns or models. That is, given a data set and some statistics (e.g., cluster centers or co-occurrence counts) of the data, the randomization methods sample data sets having similar values of the given statistics as the original data set. We use Metropolis sampling based on local swaps to achieve this. We describe experiments on real data that demonstrate the usefulness of our approach. Our results indicate that in many cases, the results of, e.g., clustering actually imply the results of, say, frequent pattern discovery.
Low-Cost Outdoor Air Quality Monitoring and In-Field Sensor Calibration
Feb 05, 2020
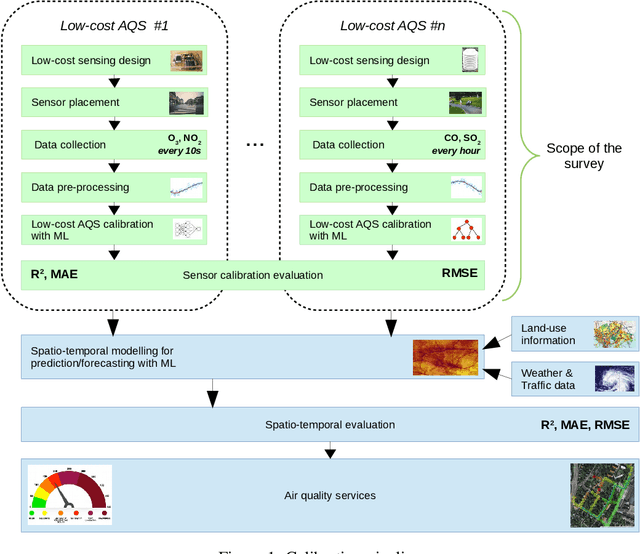
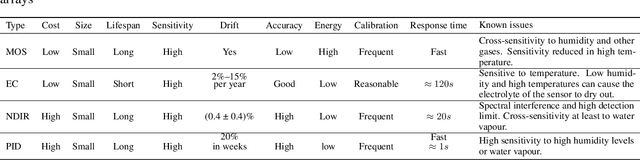
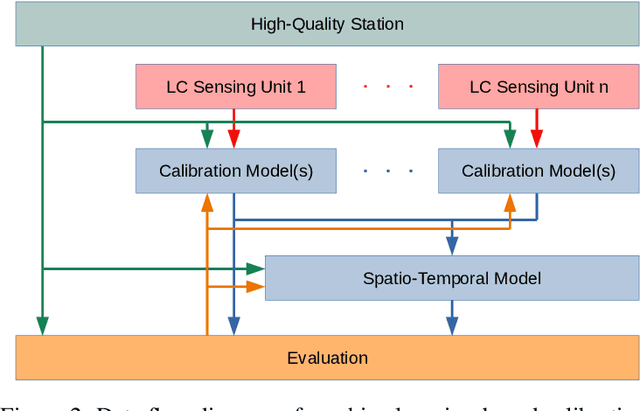
The significance of air pollution and problems associated with it is fueling deployments of air quality monitoring stations worldwide. The most common approach for air quality monitoring is to rely on environmental monitoring stations, which unfortunately are very expensive both to acquire and to maintain. Hence, environmental monitoring stations typically are deployed sparsely, resulting in limited spatial resolution for measurements. Recently, low-cost air quality sensors have emerged as an alternative that can improve granularity of monitoring. The use of low-cost air quality sensors, however, presents several challenges: they suffer from cross-sensitivities between different ambient pollutants; they can be affected by external factors such as traffic, weather changes, and human behavior; and their accuracy degrades over time. The accuracy of low-cost sensors can be improved through periodic re-calibration with particularly machine learning based calibration having shown great promise due to its capability to calibrate sensors in-field. In this article, we survey the rapidly growing research landscape of low-cost sensor technologies for air quality monitoring, and their calibration using machine learning techniques. We also identify open research challenges and present directions for future research.
Estimating regression errors without ground truth values
Oct 09, 2019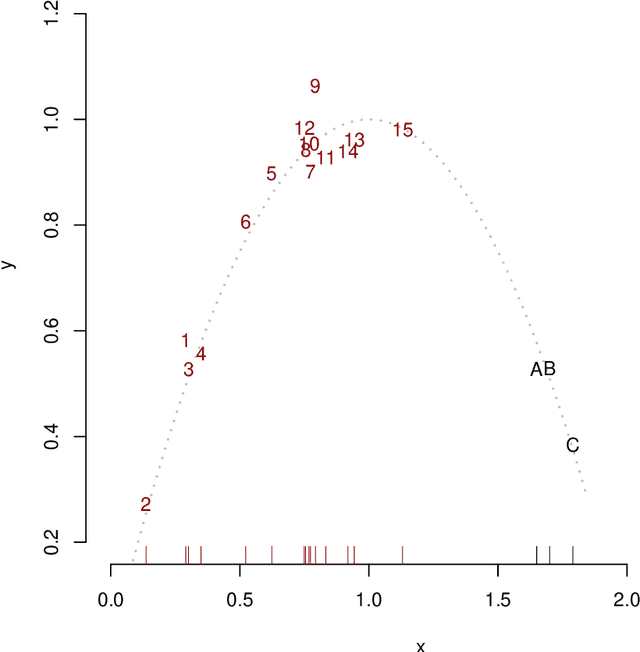
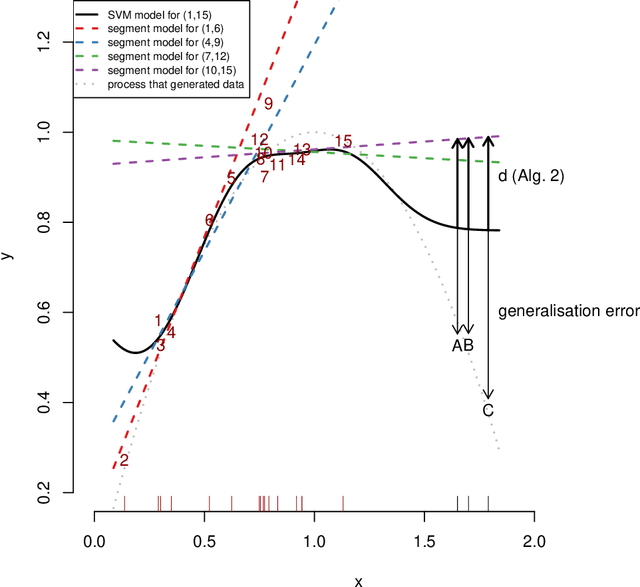
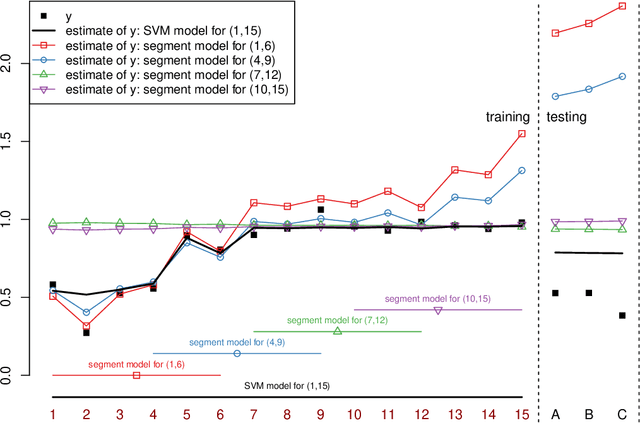
Regression analysis is a standard supervised machine learning method used to model an outcome variable in terms of a set of predictor variables. In most real-world applications we do not know the true value of the outcome variable being predicted outside the training data, i.e., the ground truth is unknown. It is hence not straightforward to directly observe when the estimate from a model potentially is wrong, due to phenomena such as overfitting and concept drift. In this paper we present an efficient framework for estimating the generalization error of regression functions, applicable to any family of regression functions when the ground truth is unknown. We present a theoretical derivation of the framework and empirically evaluate its strengths and limitations. We find that it performs robustly and is useful for detecting concept drift in datasets in several real-world domains.