 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplex-to-Euclidean Bijection for Conjugate and Calibrated Multiclass Gaussian Process
Mar 17, 2026We propose a conjugate and calibrated Gaussian process (GP) model for multi-class classification by exploiting the geometry of the probability simplex. Our approach uses Aitchison geometry to map simplex-valued class probabilities to an unconstrained Euclidean representation, turning classification into a GP regression problem with fewer latent dimensions than standard multi-class GP classifiers. This yields conjugate inference and reliable predictive probabilities without relying on distributional approximations in the model construction. The method is compatible with standard sparse GP regression techniques, enabling scalable inference on larger datasets. Empirical results show well-calibrated and competitive performance across synthetic and real-world datasets.
Simplex-to-Euclidean Bijections for Categorical Flow Matching
Oct 31, 2025We propose a method for learning and sampling from probability distributions supported on the simplex. Our approach maps the open simplex to Euclidean space via smooth bijections, leveraging the Aitchison geometry to define the mappings, and supports modeling categorical data by a Dirichlet interpolation that dequantizes discrete observations into continuous ones. This enables density modeling in Euclidean space through the bijection while still allowing exact recovery of the original discrete distribution. Compared to previous methods that operate on the simplex using Riemannian geometry or custom noise processes, our approach works in Euclidean space while respecting the Aitchison geometry, and achieves competitive performance on both synthetic and real-world data sets.
Geodesic Slice Sampler for Multimodal Distributions with Strong Curvature
Feb 28, 2025Traditional Markov Chain Monte Carlo sampling methods often struggle with sharp curvatures, intricate geometries, and multimodal distributions. Slice sampling can resolve local exploration inefficiency issues and Riemannian geometries help with sharp curvatures. Recent extensions enable slice sampling on Riemannian manifolds, but they are restricted to cases where geodesics are available in closed form. We propose a method that generalizes Hit-and-Run slice sampling to more general geometries tailored to the target distribution, by approximating geodesics as solutions to differential equations. Our approach enables exploration of regions with strong curvature and rapid transitions between modes in multimodal distributions. We demonstrate the advantages of the approach over challenging sampling problems.
Stochastic variance-reduced Gaussian variational inference on the Bures-Wasserstein manifold
Oct 03, 2024



Optimization in the Bures-Wasserstein space has been gaining popularity in the machine learning community since it draws connections between variational inference and Wasserstein gradient flows. The variational inference objective function of Kullback-Leibler divergence can be written as the sum of the negative entropy and the potential energy, making forward-backward Euler the method of choice. Notably, the backward step admits a closed-form solution in this case, facilitating the practicality of the scheme. However, the forward step is no longer exact since the Bures-Wasserstein gradient of the potential energy involves "intractable" expectations. Recent approaches propose using the Monte Carlo method -- in practice a single-sample estimator -- to approximate these terms, resulting in high variance and poor performance. We propose a novel variance-reduced estimator based on the principle of control variates. We theoretically show that this estimator has a smaller variance than the Monte-Carlo estimator in scenarios of interest. We also prove that variance reduction helps improve the optimization bounds of the current analysis. We demonstrate that the proposed estimator gains order-of-magnitude improvements over the previous Bures-Wasserstein methods.
Non-geodesically-convex optimization in the Wasserstein space
Jun 01, 2024
We study a class of optimization problems in the Wasserstein space (the space of probability measures) where the objective function is \emph{nonconvex} along generalized geodesics. When the regularization term is the negative entropy, the optimization problem becomes a sampling problem where it minimizes the Kullback-Leibler divergence between a probability measure (optimization variable) and a target probability measure whose logarithmic probability density is a nonconvex function. We derive multiple convergence insights for a novel {\em semi Forward-Backward Euler scheme} under several nonconvex (and possibly nonsmooth) regimes. Notably, the semi Forward-Backward Euler is just a slight modification of the Forward-Backward Euler whose convergence is -- to our knowledge -- still unknown in our very general non-geodesically-convex setting.
Riemannian Laplace Approximation with the Fisher Metric
Nov 08, 2023The Laplace's method approximates a target density with a Gaussian distribution at its mode. It is computationally efficient and asymptotically exact for Bayesian inference due to the Bernstein-von Mises theorem, but for complex targets and finite-data posteriors it is often too crude an approximation. A recent generalization of the Laplace Approximation transforms the Gaussian approximation according to a chosen Riemannian geometry providing a richer approximation family, while still retaining computational efficiency. However, as shown here, its properties heavily depend on the chosen metric, indeed the metric adopted in previous work results in approximations that are overly narrow as well as being biased even at the limit of infinite data. We correct this shortcoming by developing the approximation family further, deriving two alternative variants that are exact at the limit of infinite data, extending the theoretical analysis of the method, and demonstrating practical improvements in a range of experiments.
Warped geometric information on the optimisation of Euclidean functions
Aug 16, 2023



We consider the fundamental task of optimizing a real-valued function defined in a potentially high-dimensional Euclidean space, such as the loss function in many machine-learning tasks or the logarithm of the probability distribution in statistical inference. We use the warped Riemannian geometry notions to redefine the optimisation problem of a function on Euclidean space to a Riemannian manifold with a warped metric, and then find the function's optimum along this manifold. The warped metric chosen for the search domain induces a computational friendly metric-tensor for which optimal search directions associate with geodesic curves on the manifold becomes easier to compute. Performing optimization along geodesics is known to be generally infeasible, yet we show that in this specific manifold we can analytically derive Taylor approximations up to third-order. In general these approximations to the geodesic curve will not lie on the manifold, however we construct suitable retraction maps to pull them back onto the manifold. Therefore, we can efficiently optimize along the approximate geodesic curves. We cover the related theory, describe a practical optimization algorithm and empirically evaluate it on a collection of challenging optimisation benchmarks. Our proposed algorithm, using third-order approximation of geodesics, outperforms standard Euclidean gradient-based counterparts in term of number of iterations until convergence and an alternative method for Hessian-based optimisation routines.
Scalable Stochastic Gradient Riemannian Langevin Dynamics in Non-Diagonal Metrics
Mar 09, 2023
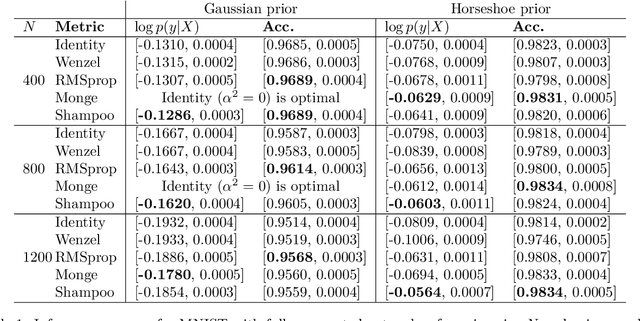

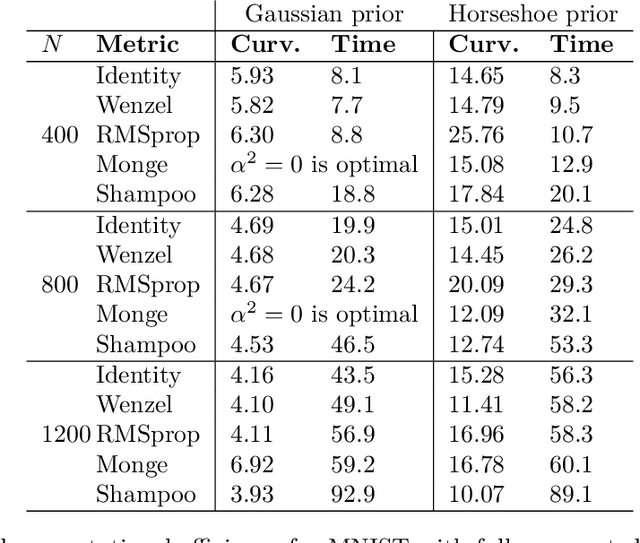
Bayesian neural network inference is often carried out using stochastic gradient sampling methods. For best performance the methods should use a Riemannian metric that improves posterior exploration by accounting for the local curvature, but the existing methods resort to simple diagonal metrics to remain computationally efficient. This loses some of the gains. We propose two non-diagonal metrics that can be used in stochastic samplers to improve convergence and exploration but that have only a minor computational overhead over diagonal metrics. We show that for neural networks with complex posteriors, caused e.g. by use of sparsity-inducing priors, using these metrics provides clear improvements. For some other choices the posterior is sufficiently easy also for the simpler metrics.