 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Reply Prediction X Dataset: Linguistic Discrepancies in Naively Generated Content
Feb 22, 2026The increasing use of Large Language Models (LLMs) as proxies for human participants in social science research presents a promising, yet methodologically risky, paradigm shift. While LLMs offer scalability and cost-efficiency, their "naive" application, where they are prompted to generate content without explicit behavioral constraints, introduces significant linguistic discrepancies that challenge the validity of research findings. This paper addresses these limitations by introducing a novel, history-conditioned reply prediction task on authentic X (formerly Twitter) data, to create a dataset designed to evaluate the linguistic output of LLMs against human-generated content. We analyze these discrepancies using stylistic and content-based metrics, providing a quantitative framework for researchers to assess the quality and authenticity of synthetic data. Our findings highlight the need for more sophisticated prompting techniques and specialized datasets to ensure that LLM-generated content accurately reflects the complex linguistic patterns of human communication, thereby improving the validity of computational social science studies.
Zero-shot prompt-based classification: topic labeling in times of foundation models in German Tweets
Jun 26, 2024


Filtering and annotating textual data are routine tasks in many areas, like social media or news analytics. Automating these tasks allows to scale the analyses wrt. speed and breadth of content covered and decreases the manual effort required. Due to technical advancements in Natural Language Processing, specifically the success of large foundation models, a new tool for automating such annotation processes by using a text-to-text interface given written guidelines without providing training samples has become available. In this work, we assess these advancements in-the-wild by empirically testing them in an annotation task on German Twitter data about social and political European crises. We compare the prompt-based results with our human annotation and preceding classification approaches, including Naive Bayes and a BERT-based fine-tuning/domain adaptation pipeline. Our results show that the prompt-based approach - despite being limited by local computation resources during the model selection - is comparable with the fine-tuned BERT but without any annotated training data. Our findings emphasize the ongoing paradigm shift in the NLP landscape, i.e., the unification of downstream tasks and elimination of the need for pre-labeled training data.
InvBERT: Text Reconstruction from Contextualized Embeddings used for Derived Text Formats of Literary Works
Sep 21, 2021
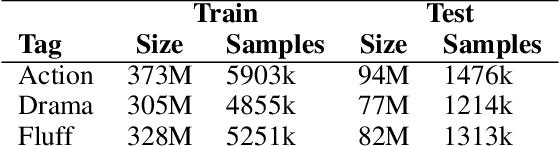
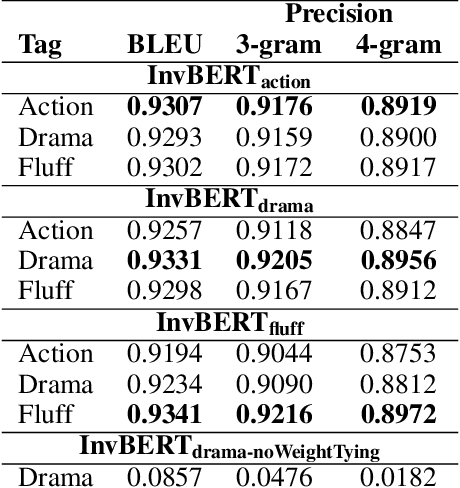
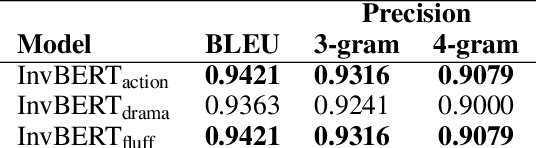
Digital Humanities and Computational Literary Studies apply text mining methods to investigate literature. Such automated approaches enable quantitative studies on large corpora which would not be feasible by manual inspection alone. However, due to copyright restrictions, the availability of relevant digitized literary works is limited. Derived Text Formats (DTFs) have been proposed as a solution. Here, textual materials are transformed in such a way that copyright-critical features are removed, but that the use of certain analytical methods remains possible. Contextualized word embeddings produced by transformer-encoders (like BERT) are promising candidates for DTFs because they allow for state-of-the-art performance on various analytical tasks and, at first sight, do not disclose the original text. However, in this paper we demonstrate that under certain conditions the reconstruction of the original copyrighted text becomes feasible and its publication in the form of contextualized word representations is not safe. Our attempts to invert BERT suggest, that publishing parts of the encoder together with the contextualized embeddings is critical, since it allows to generate data to train a decoder with a reconstruction accuracy sufficient to violate copyright laws.