 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Latent Fingerprint Segmentation
Sep 04, 2018
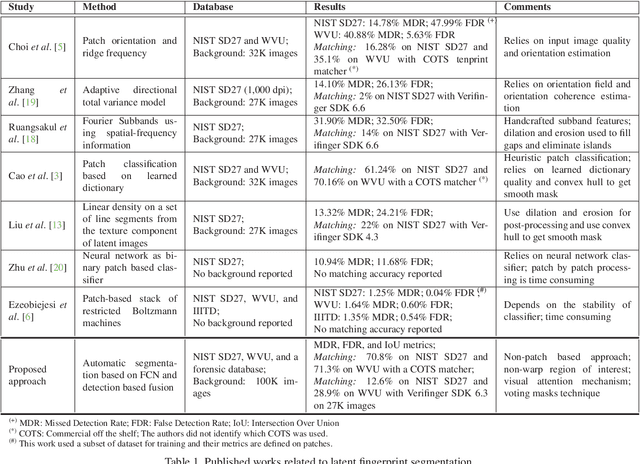
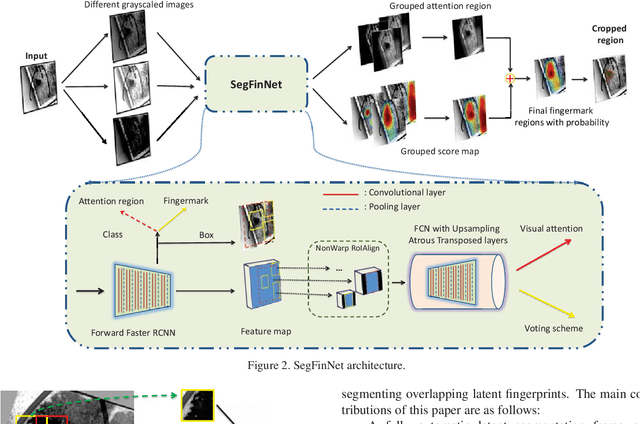
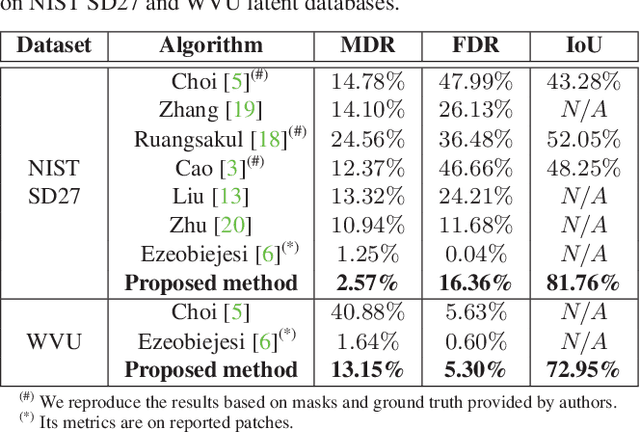
We present a simple but effective method for automatic latent fingerprint segmentation, called SegFinNet. SegFinNet takes a latent image as an input and outputs a binary mask highlighting the friction ridge pattern. Our algorithm combines fully convolutional neural network and detection-based approaches to process the entire input latent image in one shot instead of using latent patches. Experimental results on three different latent databases (i.e. NIST SD27, WVU, and an operational forensic database) show that SegFinNet outperforms both human markup for latents and the state-of-the-art latent segmentation algorithms. We further show that this improved cropping boosts the hit rate of a latent fingerprint matcher.
On the Reconstruction of Face Images from Deep Face Templates
Apr 29, 2018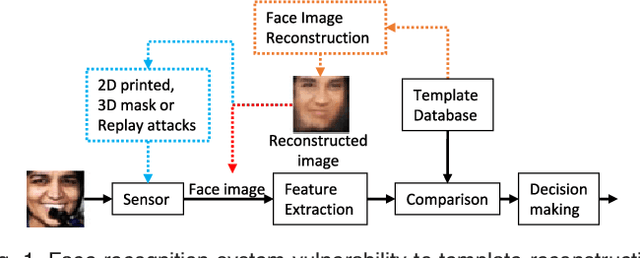


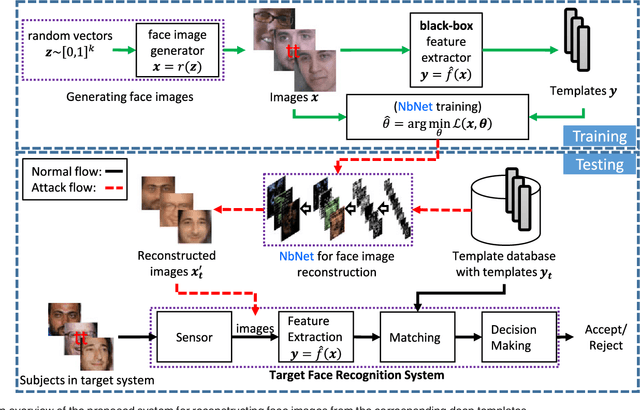
State-of-the-art face recognition systems are based on deep (convolutional) neural networks. Therefore, it is imperative to determine to what extent face templates derived from deep networks can be inverted to obtain the original face image. In this paper, we study the vulnerabilities of a state-of-the-art face recognition system based on template reconstruction attack. We propose a neighborly de-convolutional neural network (\textit{NbNet}) to reconstruct face images from their deep templates. In our experiments, we assumed that no knowledge about the target subject and the deep network are available. To train the \textit{NbNet} reconstruction models, we augmented two benchmark face datasets (VGG-Face and Multi-PIE) with a large collection of images synthesized using a face generator. The proposed reconstruction was evaluated using type-I (comparing the reconstructed images against the original face images used to generate the deep template) and type-II (comparing the reconstructed images against a different face image of the same subject) attacks. Given the images reconstructed from \textit{NbNets}, we show that for verification, we achieve TAR of 95.20\% (58.05\%) on LFW under type-I (type-II) attacks @ FAR of 0.1\%. Besides, 96.58\% (92.84\%) of the images reconstruction from templates of partition \textit{fa} (\textit{fb}) can be identified from partition \textit{fa} in color FERET. Our study demonstrates the need to secure deep templates in face recognition systems.
Latent Fingerprint Recognition: Role of Texture Template
Apr 27, 2018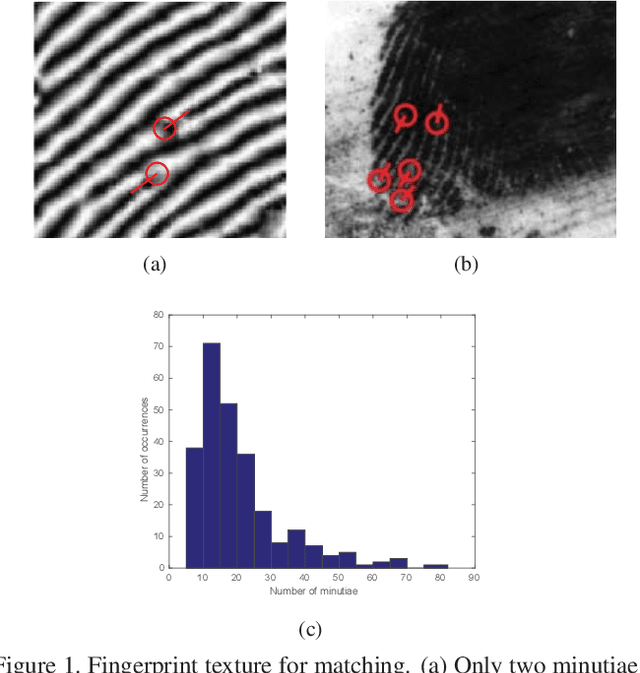
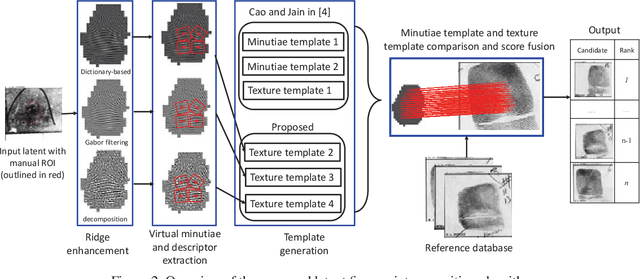
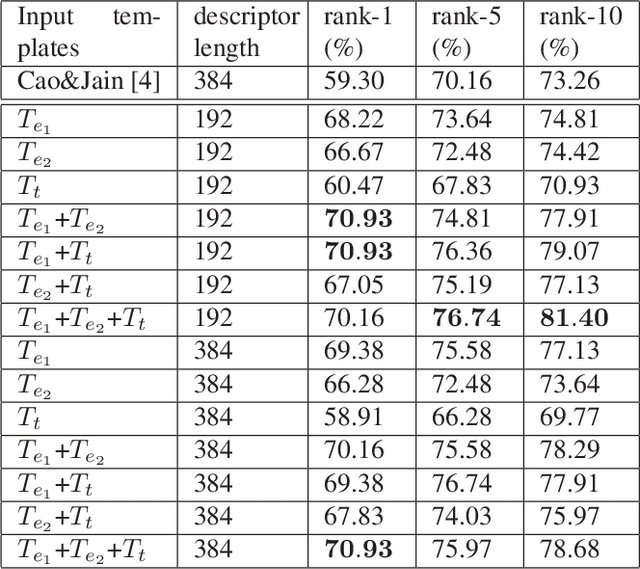
We propose a texture template approach, consisting of a set of virtual minutiae, to improve the overall latent fingerprint recognition accuracy. To compensate for the lack of sufficient number of minutiae in poor quality latent prints, we generate a set of virtual minutiae. However, due to a large number of these regularly placed virtual minutiae, texture based template matching has a large computational requirement compared to matching true minutiae templates. To improve both the accuracy and efficiency of the texture template matching, we investigate: i) both original and enhanced fingerprint patches for training convolutional neural networks (ConvNets) to improve the distinctiveness of descriptors associated with each virtual minutiae, ii) smaller patches around virtual minutiae and a fast ConvNet architecture to speed up descriptor extraction, iii) reduce the descriptor length, iv) a modified hierarchical graph matching strategy to improve the matching speed, and v) extraction of multiple texture templates to boost the performance. Experiments on NIST SD27 latent database show that the above strategies can improve the matching speed from 11 ms (24 threads) per comparison (between a latent and a reference print) to only 7.7 ms (single thread) per comparison while improving the rank-1 accuracy by 8.9% against 10K gallery.
Fingerprint Match in Box
Apr 23, 2018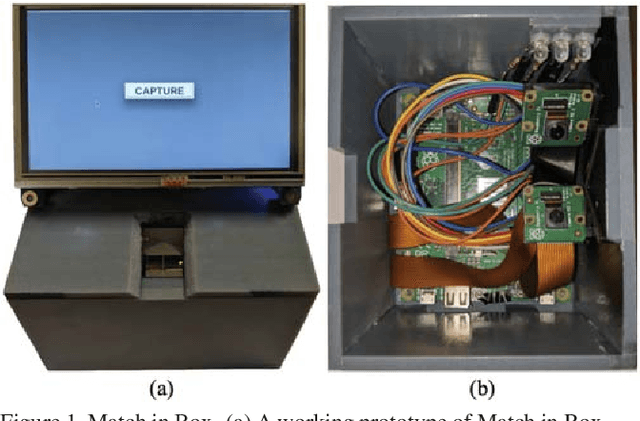

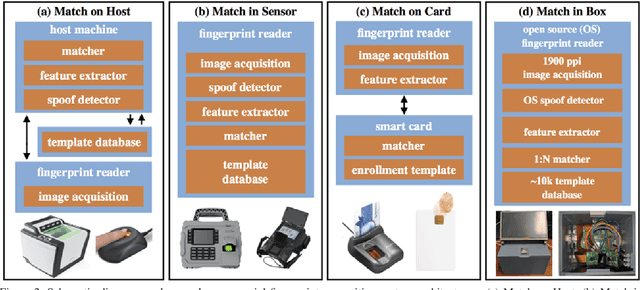

We open source fingerprint Match in Box, a complete end-to-end fingerprint recognition system embedded within a 4 inch cube. Match in Box stands in contrast to a typical bulky and expensive proprietary fingerprint recognition system which requires sending a fingerprint image to an external host for processing and subsequent spoof detection and matching. In particular, Match in Box is a first of a kind, portable, low-cost, and easy-to-assemble fingerprint reader with an enrollment database embedded within the reader's memory and open source fingerprint spoof detector, feature extractor, and matcher all running on the reader's internal vision processing unit (VPU). An onboard touch screen and rechargeable battery pack make this device extremely portable and ideal for applying both fingerprint authentication (1:1 comparison) and fingerprint identification (1:N search) to applications (vaccination tracking, food and benefit distribution programs, human trafficking prevention) in rural communities, especially in developing countries. We also show that Match in Box is suited for capturing neonate fingerprints due to its high resolution (1900 ppi) cameras.
Matching Fingerphotos to Slap Fingerprint Images
Apr 22, 2018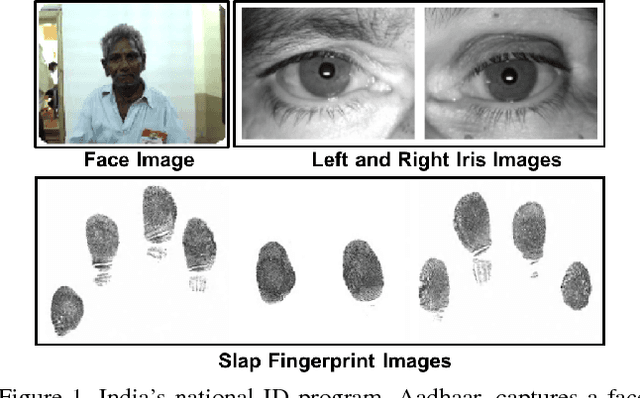
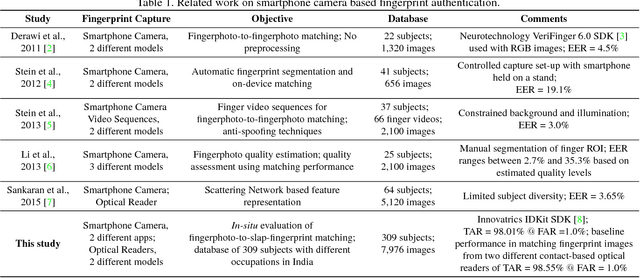

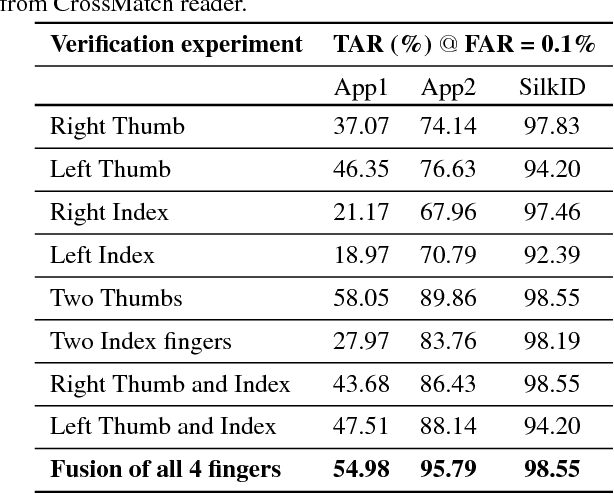
We address the problem of comparing fingerphotos, fingerprint images from a commodity smartphone camera, with the corresponding legacy slap contact-based fingerprint images. Development of robust versions of these technologies would enable the use of the billions of standard Android phones as biometric readers through a simple software download, dramatically lowering the cost and complexity of deployment relative to using a separate fingerprint reader. Two fingerphoto apps running on Android phones and an optical slap reader were utilized for fingerprint collection of 309 subjects who primarily work as construction workers, farmers, and domestic helpers. Experimental results show that a True Accept Rate (TAR) of 95.79 at a False Accept Rate (FAR) of 0.1% can be achieved in matching fingerphotos to slaps (two thumbs and two index fingers) using a COTS fingerprint matcher. By comparison, a baseline TAR of 98.55% at 0.1% FAR is achieved when matching fingerprint images from two different contact-based optical readers. We also report the usability of the two smartphone apps, in terms of failure to acquire rate and fingerprint acquisition time. Our results show that fingerphotos are promising to authenticate individuals (against a national ID database) for banking, welfare distribution, and healthcare applications in developing countries.
Robust Minutiae Extractor: Integrating Deep Networks and Fingerprint Domain Knowledge
Dec 26, 2017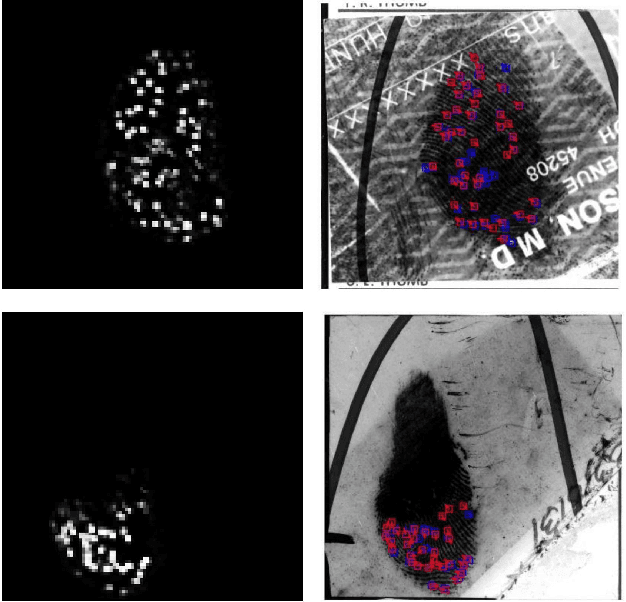
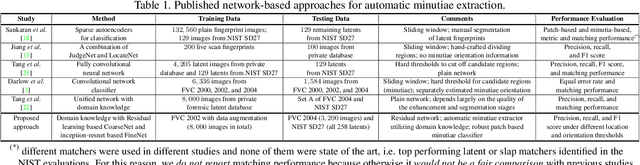
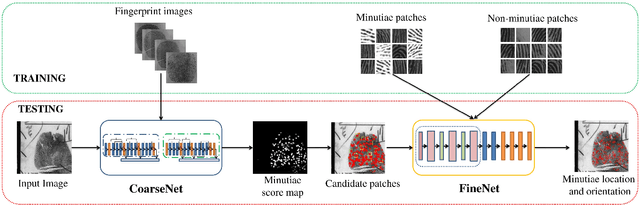
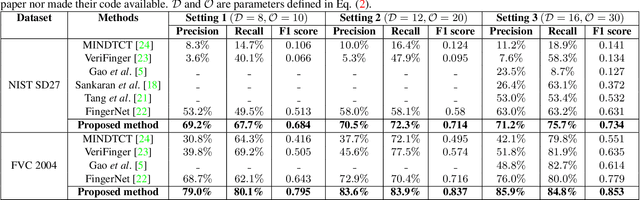
We propose a fully automatic minutiae extractor, called MinutiaeNet, based on deep neural networks with compact feature representation for fast comparison of minutiae sets. Specifically, first a network, called CoarseNet, estimates the minutiae score map and minutiae orientation based on convolutional neural network and fingerprint domain knowledge (enhanced image, orientation field, and segmentation map). Subsequently, another network, called FineNet, refines the candidate minutiae locations based on score map. We demonstrate the effectiveness of using the fingerprint domain knowledge together with the deep networks. Experimental results on both latent (NIST SD27) and plain (FVC 2004) public domain fingerprint datasets provide comprehensive empirical support for the merits of our method. Further, our method finds minutiae sets that are better in terms of precision and recall in comparison with state-of-the-art on these two datasets. Given the lack of annotated fingerprint datasets with minutiae ground truth, the proposed approach to robust minutiae detection will be useful to train network-based fingerprint matching algorithms as well as for evaluating fingerprint individuality at scale. MinutiaeNet is implemented in Tensorflow: https://github.com/luannd/MinutiaeNet
RaspiReader: Open Source Fingerprint Reader
Dec 26, 2017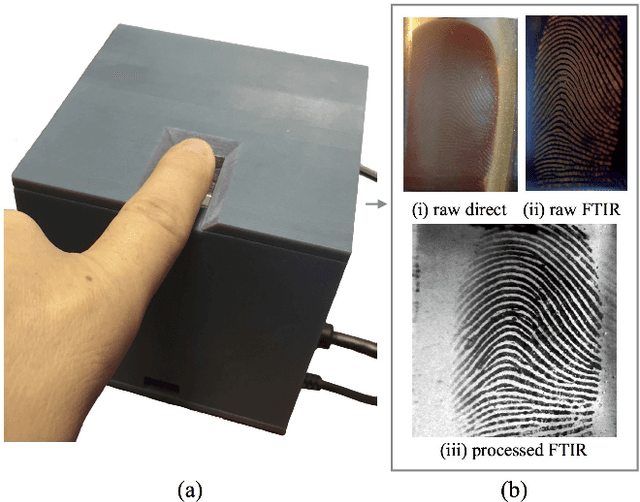


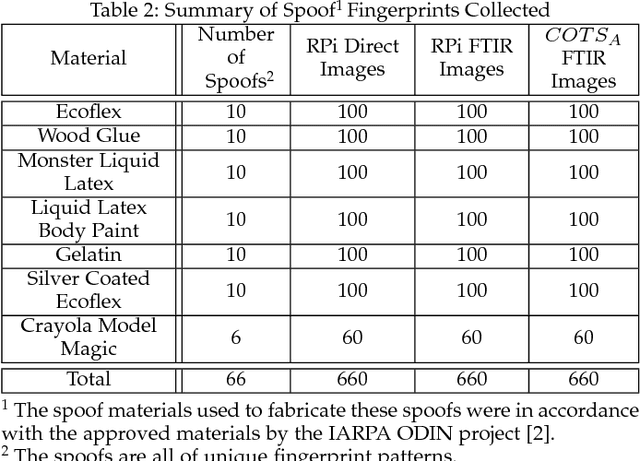
We open source an easy to assemble, spoof resistant, high resolution, optical fingerprint reader, called RaspiReader, using ubiquitous components. By using our open source STL files and software, RaspiReader can be built in under one hour for only US $175. As such, RaspiReader provides the fingerprint research community a seamless and simple method for quickly prototyping new ideas involving fingerprint reader hardware. In particular, we posit that this open source fingerprint reader will facilitate the exploration of novel fingerprint spoof detection techniques involving both hardware and software. We demonstrate one such spoof detection technique by specially customizing RaspiReader with two cameras for fingerprint image acquisition. One camera provides high contrast, frustrated total internal reflection (FTIR) fingerprint images, and the other outputs direct images of the finger in contact with the platen. Using both of these image streams, we extract complementary information which, when fused together and used for spoof detection, results in marked performance improvement over previous methods relying only on grayscale FTIR images provided by COTS optical readers. Finally, fingerprint matching experiments between images acquired from the FTIR output of RaspiReader and images acquired from a COTS reader verify the interoperability of the RaspiReader with existing COTS optical readers.
Fingerprint Spoof Buster
Dec 12, 2017
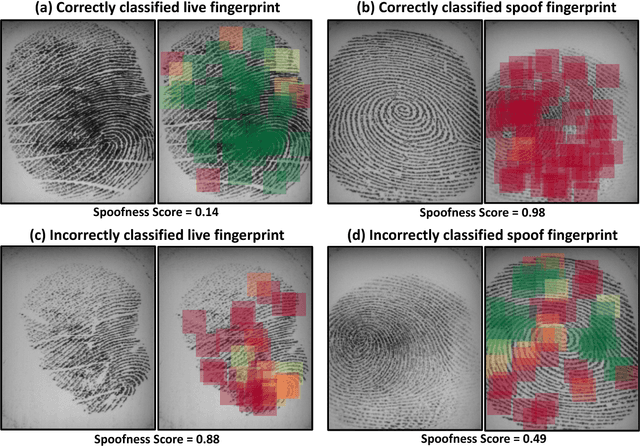
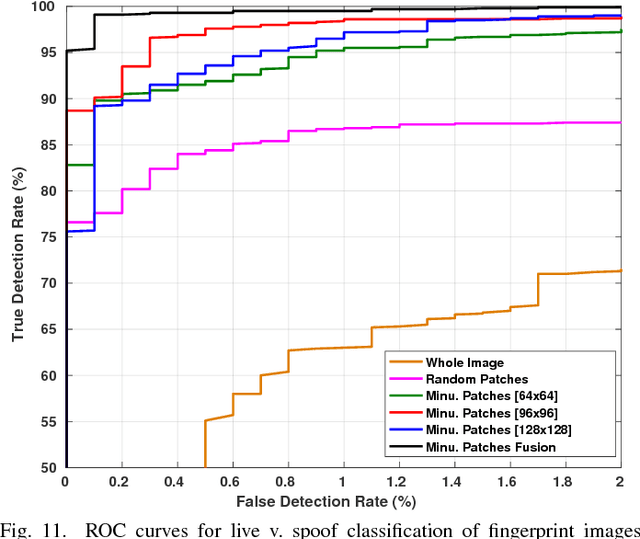

The primary purpose of a fingerprint recognition system is to ensure a reliable and accurate user authentication, but the security of the recognition system itself can be jeopardized by spoof attacks. This study addresses the problem of developing accurate, generalizable, and efficient algorithms for detecting fingerprint spoof attacks. Specifically, we propose a deep convolutional neural network based approach utilizing local patches centered and aligned using fingerprint minutiae. Experimental results on three public-domain LivDet datasets (2011, 2013, and 2015) show that the proposed approach provides state-of-the-art accuracies in fingerprint spoof detection for intra-sensor, cross-material, cross-sensor, as well as cross-dataset testing scenarios. For example, in LivDet 2015, the proposed approach achieves 99.03% average accuracy over all sensors compared to 95.51% achieved by the LivDet 2015 competition winners. Additionally, two new fingerprint presentation attack datasets containing more than 20,000 images, using two different fingerprint readers, and over 12 different spoof fabrication materials are collected. We also present a graphical user interface, called Fingerprint Spoof Buster, that allows the operator to visually examine the local regions of the fingerprint highlighted as live or spoof, instead of relying on only a single score as output by the traditional approaches.
RaspiReader: An Open Source Fingerprint Reader Facilitating Spoof Detection
Aug 25, 2017


We present the design and prototype of an open source, optical fingerprint reader, called RaspiReader, using ubiquitous components. RaspiReader, a low-cost and easy to assemble reader, provides the fingerprint research community a seamless and simple method for gaining more control over the sensing component of fingerprint recognition systems. In particular, we posit that this versatile fingerprint reader will encourage researchers to explore novel spoof detection methods that integrate both hardware and software. RaspiReader's hardware is customized with two cameras for fingerprint acquisition with one camera providing high contrast, frustrated total internal reflection (FTIR) images, and the other camera outputting direct images. Using both of these image streams, we extract complementary information which, when fused together, results in highly discriminative features for fingerprint spoof (presentation attack) detection. Our experimental results demonstrate a marked improvement over previous spoof detection methods which rely only on FTIR images provided by COTS optical readers. Finally, fingerprint matching experiments between images acquired from the FTIR output of the RaspiReader and images acquired from a COTS fingerprint reader verify the interoperability of the RaspiReader with existing COTS optical readers.
Automated Latent Fingerprint Recognition
Apr 06, 2017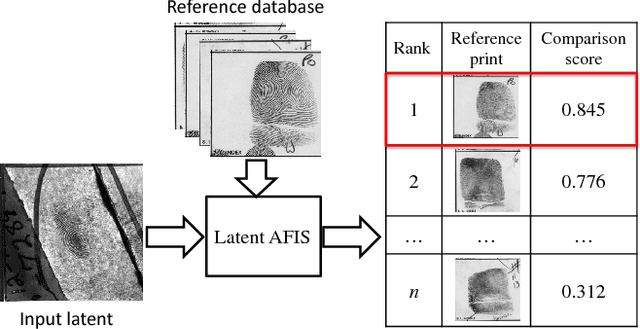
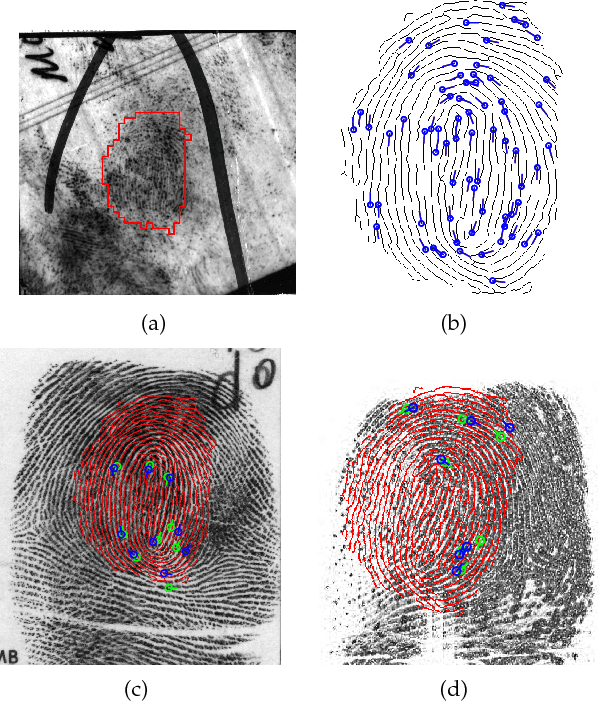


Latent fingerprints are one of the most important and widely used evidence in law enforcement and forensic agencies worldwide. Yet, NIST evaluations show that the performance of state-of-the-art latent recognition systems is far from satisfactory. An automated latent fingerprint recognition system with high accuracy is essential to compare latents found at crime scenes to a large collection of reference prints to generate a candidate list of possible mates. In this paper, we propose an automated latent fingerprint recognition algorithm that utilizes Convolutional Neural Networks (ConvNets) for ridge flow estimation and minutiae descriptor extraction, and extract complementary templates (two minutiae templates and one texture template) to represent the latent. The comparison scores between the latent and a reference print based on the three templates are fused to retrieve a short candidate list from the reference database. Experimental results show that the rank-1 identification accuracies (query latent is matched with its true mate in the reference database) are 64.7% for the NIST SD27 and 75.3% for the WVU latent databases, against a reference database of 100K rolled prints. These results are the best among published papers on latent recognition and competitive with the performance (66.7% and 70.8% rank-1 accuracies on NIST SD27 and WVU DB, respectively) of a leading COTS latent Automated Fingerprint Identification System (AFIS). By score-level (rank-level) fusion of our system with the commercial off-the-shelf (COTS) latent AFIS, the overall rank-1 identification performance can be improved from 64.7% and 75.3% to 73.3% (74.4%) and 76.6% (78.4%) on NIST SD27 and WVU latent databases, respectively.