 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARKD: Adaptive Reinforcement Learning-Guided Bidirectional KL Divergence Distillation for Text Generation
Jun 29, 2026Knowledge distillation (KD) is a key technique for compressing Large Language Models (LLMs), yet methods relying on a single KL objective often fail to balance primary distribution fitting with long-tail probability modeling, limiting both generation quality and generalization. To address this, we analyze the complementary roles of forward and reverse KL divergence (FKL/RKL) in distribution alignment from theoretical and empirical perspectives. We then propose a reinforcement-learning-based adaptive KL-weighted distillation framework, in which a policy network dynamically assigns weights to FKL and RKL based on teacher-student distributional characteristics, guided by immediate reward signals to achieve dual alignment on principal and long-tail modes. Extensive experiments demonstrate consistent improvements across Rouge-L and BertScore metrics, surpassing greedy heuristics by 0.4-0.6 points and outperforming other baseline methods on diverse benchmarks.
Rethinking Sales Lead Scoring with LLM-based Hierarchical Preference Ranking
Jun 03, 2026Sales lead conversion in high-stakes domains (e.g., automotive, real estate) differs fundamentally from e-commerce recommendation due to prolonged decision cycles and multi-stage funnels. Traditional lead scoring methods rule-based scorecards, machine learning, or pointwise CTR models face severe challenges: sparse supervision, a semantic gap in unstructured CRM logs, and inability to capture relative lead priority. While Large Language Models(LLMs) offer superior semantic understanding of customer interactions, general-purpose LLMs are ill-suited for lead ranking: they generate text rather than comparable scores, and lack alignment with the hierarchical priorities of sales funnels. We introduce an LLM-based discriminative framework for sales lead scoring, which supports joint modeling of structured CRM features and unstructured customer interactions. On top of this framework, we propose HPRO (Hierarchical Preference Ranking Optimization), which augments sales lead scoring with a hierarchical preference ranking objective. HPRO employs a margin-aware Bradley-Terry formulation to transform sparse binary labels into dense, funnel-aware preference pairs, enabling lead scoring to leverage both pointwise and pairwise supervision. Experiments on large-scale data from a leading NEV brand demonstrate state-of-the-art classification (AUC 0.8161) and ranking performance (+39.7% precision among top-ranked leads). A 132-day online A/B test validates 9.5% sales volume uplift, confirming real-world commercial impact.
MASR: Self-Reflective Reasoning through Multimodal Hierarchical Attention Focusing for Agent-based Video Understanding
Apr 28, 2025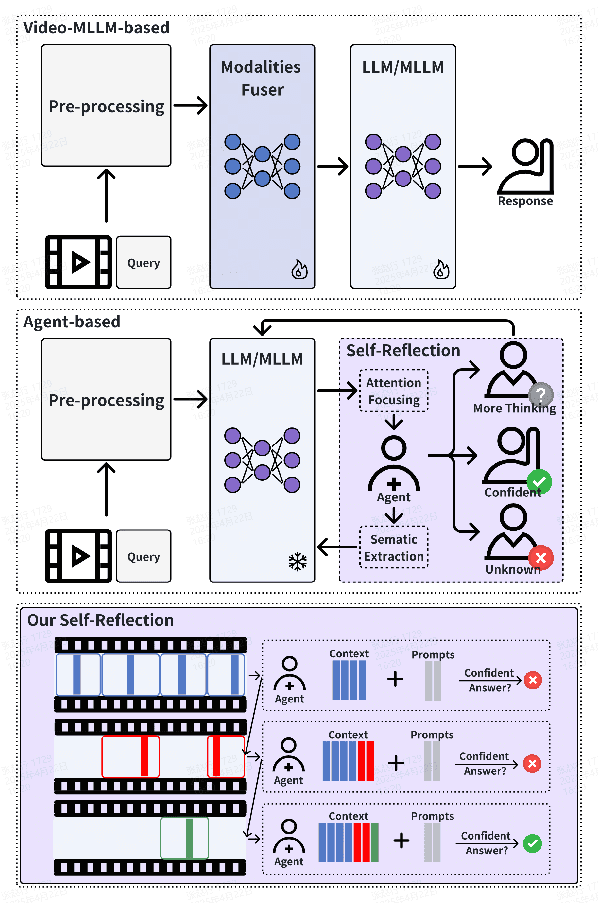
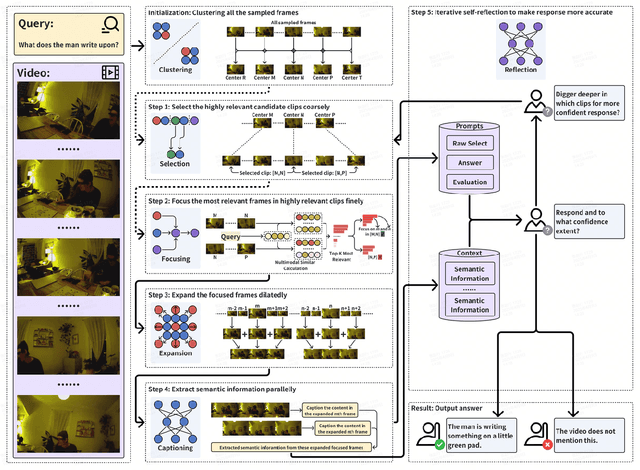
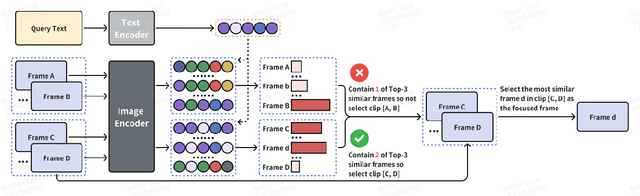
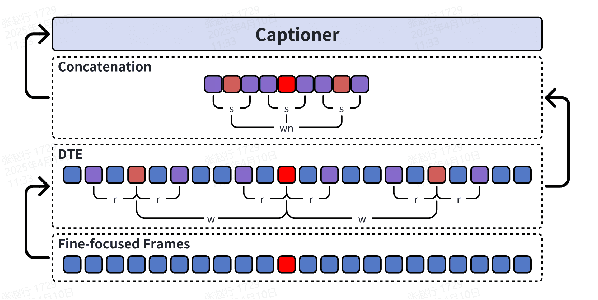
Even in the era of rapid advances in large models, video understanding remains a highly challenging task. Compared to texts or images, videos commonly contain more information with redundancy, requiring large models to properly allocate attention at a global level for comprehensive and accurate understanding. To address this, we propose a Multimodal hierarchical Attention focusing Self-reflective Reasoning (MASR) framework for agent-based video understanding. The key innovation lies in its ability to detect and prioritize segments of videos that are highly relevant to the query. Firstly, MASR realizes Multimodal Coarse-to-fine Relevance Sensing (MCRS) which enhances the correlation between the acquired contextual information and the query. Secondly, MASR employs Dilated Temporal Expansion (DTE) to mitigate the risk of missing crucial details when extracting semantic information from the focused frames selected through MCRS. By iteratively applying MCRS and DTE in the self-reflective reasoning process, MASR is able to adaptively adjust the attention to extract highly query-relevant context and therefore improve the response accuracy. In the EgoSchema dataset, MASR achieves a remarkable 5% performance gain over previous leading approaches. In the Next-QA and IntentQA datasets, it outperforms the state-of-the-art standards by 0.2% and 0.3% respectively. In the Video-MME dataset that contains long-term videos, MASR also performs better than other agent-based methods.
MCAF: Efficient Agent-based Video Understanding Framework through Multimodal Coarse-to-Fine Attention Focusing
Apr 24, 2025Even in the era of rapid advances in large models, video understanding, particularly long videos, remains highly challenging. Compared with textual or image-based information, videos commonly contain more information with redundancy, requiring large models to strategically allocate attention at a global level for accurate comprehension. To address this, we propose MCAF, an agent-based, training-free framework perform video understanding through Multimodal Coarse-to-fine Attention Focusing. The key innovation lies in its ability to sense and prioritize segments of the video that are highly relevant to the understanding task. First, MCAF hierarchically concentrates on highly relevant frames through multimodal information, enhancing the correlation between the acquired contextual information and the query. Second, it employs a dilated temporal expansion mechanism to mitigate the risk of missing crucial details when extracting information from these concentrated frames. In addition, our framework incorporates a self-reflection mechanism utilizing the confidence level of the model's responses as feedback. By iteratively applying these two creative focusing strategies, it adaptively adjusts attention to capture highly query-connected context and thus improves response accuracy. MCAF outperforms comparable state-of-the-art methods on average. On the EgoSchema dataset, it achieves a remarkable 5% performance gain over the leading approach. Meanwhile, on Next-QA and IntentQA datasets, it outperforms the current state-of-the-art standard by 0.2% and 0.3% respectively. On the Video-MME dataset, which features videos averaging nearly an hour in length, MCAF also outperforms other agent-based methods.
DR-RAG: Applying Dynamic Document Relevance to Retrieval-Augmented Generation for Question-Answering
Jun 12, 2024



Retrieval-Augmented Generation (RAG) has significantly demonstrated the performance of Large Language Models (LLMs) in the knowledge-intensive tasks, such as Question-Answering (QA). RAG expands the query context by incorporating external knowledge bases to enhance the response accuracy. However, it would be inefficient to access LLMs multiple times for each query and unreliable to retrieve all the relevant documents by a single query. We find that even though there is low relevance between some critical documents and query, it is possible to retrieve the remaining documents by combining parts of the documents with the query. To mine the relevance, a two-stage retrieval framework called Dynamic-Relevant Retrieval-Augmented Generation (DR-RAG) is proposed to improve document retrieval recall and the accuracy of answers while maintaining efficiency. Also, a small classifier is applied to two different selection strategies to determine the contribution of the retrieved documents to answering the query and retrieve the relatively relevant documents. Meanwhile, DR-RAG call the LLMs only once, which significantly improves the efficiency of the experiment. The experimental results on multi-hop QA datasets show that DR-RAG can significantly improve the accuracy of the answers and achieve new progress in QA systems.