 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCAF: Efficient Agent-based Video Understanding Framework through Multimodal Coarse-to-Fine Attention Focusing
Paper and Code
Apr 24, 2025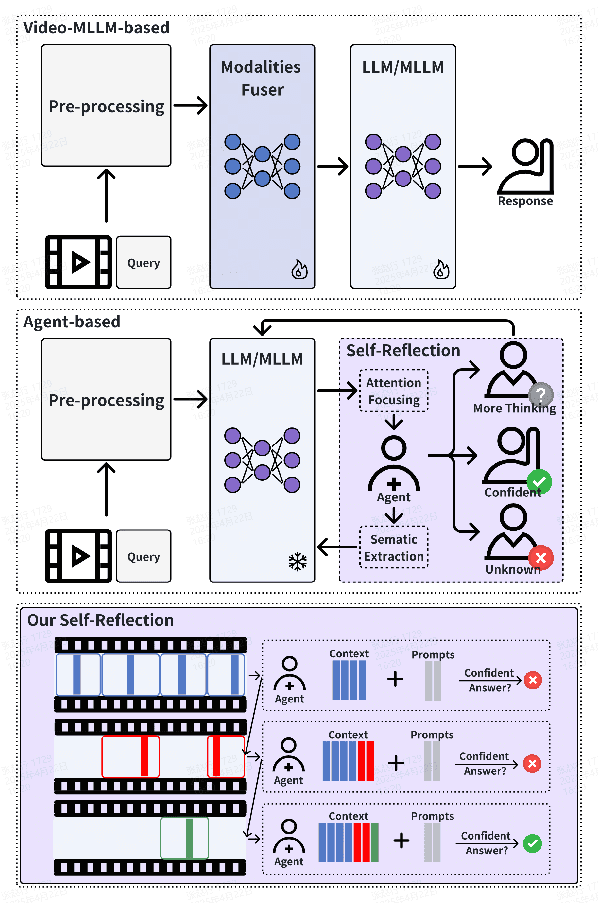
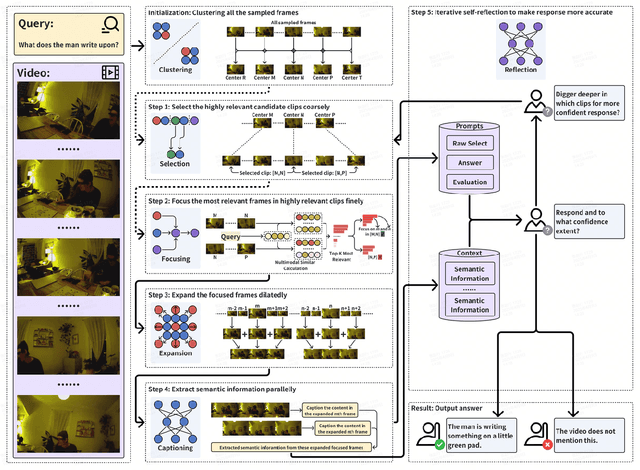
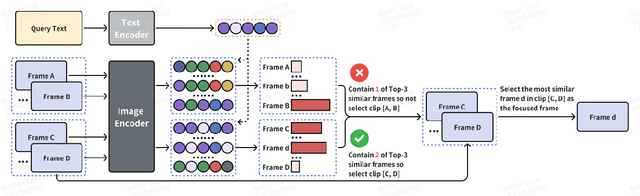
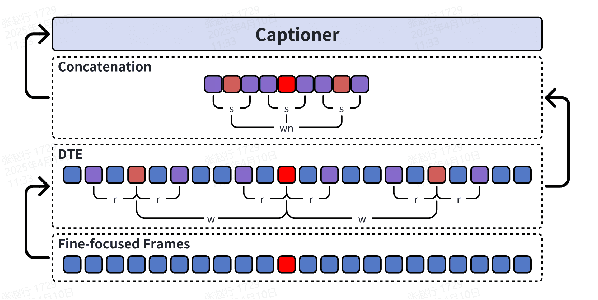
Even in the era of rapid advances in large models, video understanding, particularly long videos, remains highly challenging. Compared with textual or image-based information, videos commonly contain more information with redundancy, requiring large models to strategically allocate attention at a global level for accurate comprehension. To address this, we propose MCAF, an agent-based, training-free framework perform video understanding through Multimodal Coarse-to-fine Attention Focusing. The key innovation lies in its ability to sense and prioritize segments of the video that are highly relevant to the understanding task. First, MCAF hierarchically concentrates on highly relevant frames through multimodal information, enhancing the correlation between the acquired contextual information and the query. Second, it employs a dilated temporal expansion mechanism to mitigate the risk of missing crucial details when extracting information from these concentrated frames. In addition, our framework incorporates a self-reflection mechanism utilizing the confidence level of the model's responses as feedback. By iteratively applying these two creative focusing strategies, it adaptively adjusts attention to capture highly query-connected context and thus improves response accuracy. MCAF outperforms comparable state-of-the-art methods on average. On the EgoSchema dataset, it achieves a remarkable 5% performance gain over the leading approach. Meanwhile, on Next-QA and IntentQA datasets, it outperforms the current state-of-the-art standard by 0.2% and 0.3% respectively. On the Video-MME dataset, which features videos averaging nearly an hour in length, MCAF also outperforms other agent-based methods.