 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-dimensional distributed semantic spaces for utterances
Apr 01, 2021High-dimensional distributed semantic spaces have proven useful and effective for aggregating and processing visual, auditory, and lexical information for many tasks related to human-generated data. Human language makes use of a large and varying number of features, lexical and constructional items as well as contextual and discourse-specific data of various types, which all interact to represent various aspects of communicative information. Some of these features are mostly local and useful for the organisation of e.g. argument structure of a predication; others are persistent over the course of a discourse and necessary for achieving a reasonable level of understanding of the content. This paper describes a model for high-dimensional representation for utterance and text level data including features such as constructions or contextual data, based on a mathematically principled and behaviourally plausible approach to representing linguistic information. The implementation of the representation is a straightforward extension of Random Indexing models previously used for lexical linguistic items. The paper shows how the implemented model is able to represent a broad range of linguistic features in a common integral framework of fixed dimensionality, which is computationally habitable, and which is suitable as a bridge between symbolic representations such as dependency analysis and continuous representations used e.g. in classifiers or further machine-learning approaches. This is achieved with operations on vectors that constitute a powerful computational algebra, accompanied with an associative memory for the vectors. The paper provides a technical overview of the framework and a worked through implemented example of how it can be applied to various types of linguistic features.
TREC 2020 Podcasts Track Overview
Mar 29, 2021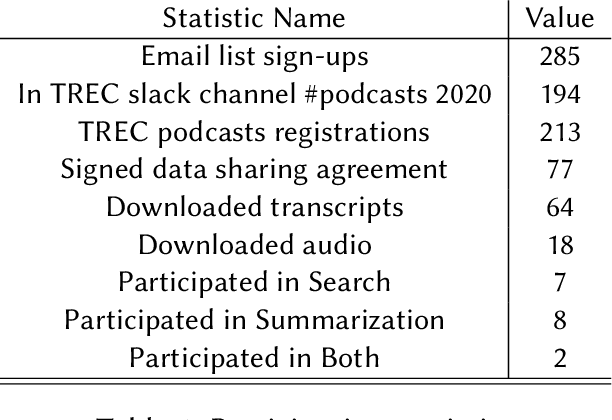
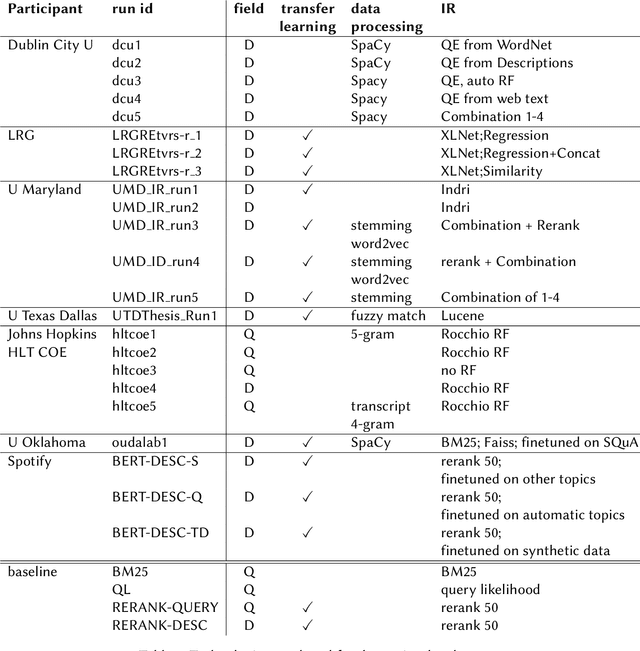
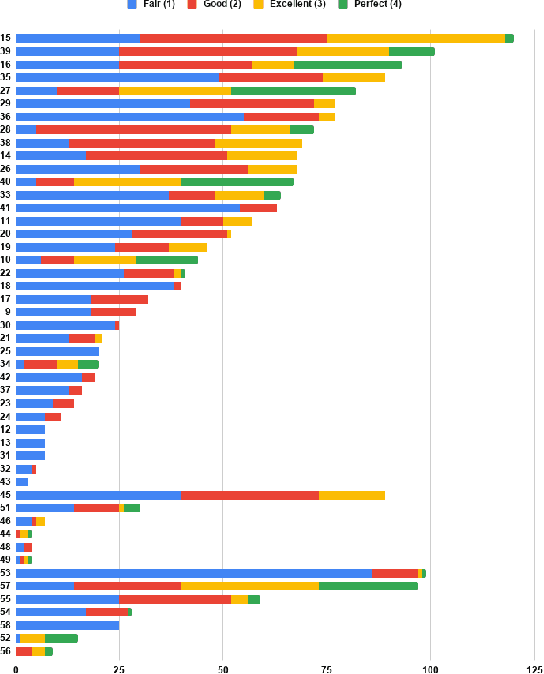
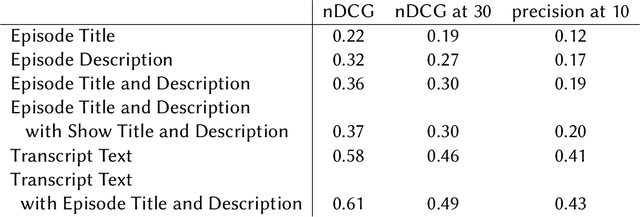
The Podcast Track is new at the Text Retrieval Conference (TREC) in 2020. The podcast track was designed to encourage research into podcasts in the information retrieval and NLP research communities. The track consisted of two shared tasks: segment retrieval and summarization, both based on a dataset of over 100,000 podcast episodes (metadata, audio, and automatic transcripts) which was released concurrently with the track. The track generated considerable interest, attracted hundreds of new registrations to TREC and fifteen teams, mostly disjoint between search and summarization, made final submissions for assessment. Deep learning was the dominant experimental approach for both search experiments and summarization. This paper gives an overview of the tasks and the results of the participants' experiments. The track will return to TREC 2021 with the same two tasks, incorporating slight modifications in response to participant feedback.
Text Mining for Processing Interview Data in Computational Social Science
Nov 28, 2020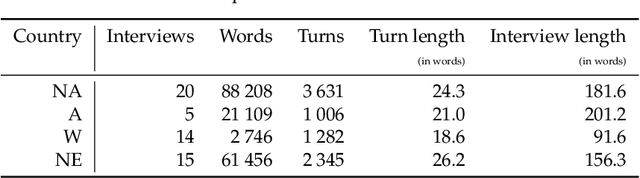
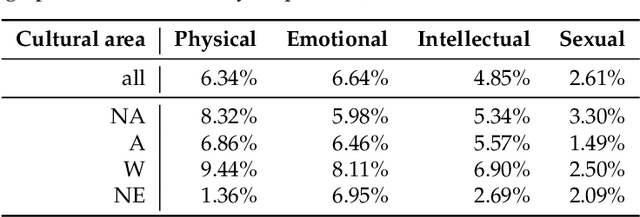
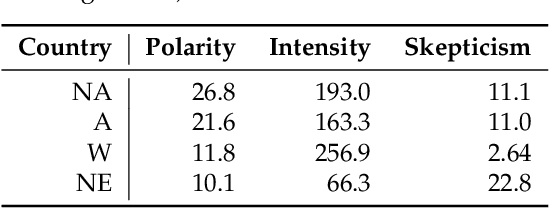
We use commercially available text analysis technology to process interview text data from a computational social science study. We find that topical clustering and terminological enrichment provide for convenient exploration and quantification of the responses. This makes it possible to generate and test hypotheses and to compare textual and non-textual variables, and saves analyst effort. We encourage studies in social science to use text analysis, especially for exploratory open-ended studies. We discuss how replicability requirements are met by text analysis technology. We note that the most recent learning models are not designed with transparency in mind, and that research requires a model to be editable and its decisions to be explainable. The tools available today, such as the one used in the present study, are not built for processing interview texts. While many of the variables under consideration are quantifiable using lexical statistics, we find that some interesting and potentially valuable features are difficult or impossible to automatise reliably at present. We note that there are some potentially interesting applications for traditional natural language processing mechanisms such as named entity recognition and anaphora resolution in this application area. We conclude with a suggestion for language technologists to investigate the challenge of processing interview data comprehensively, especially the interplay between question and response, and we encourage social science researchers not to hesitate to use text analysis tools, especially for the exploratory phase of processing interview data.?
The Spotify Podcasts Dataset
Apr 08, 2020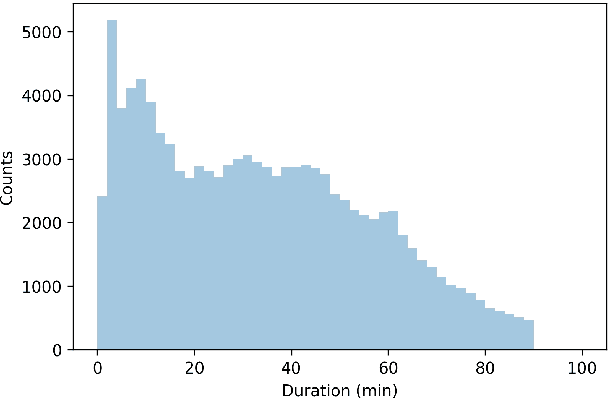
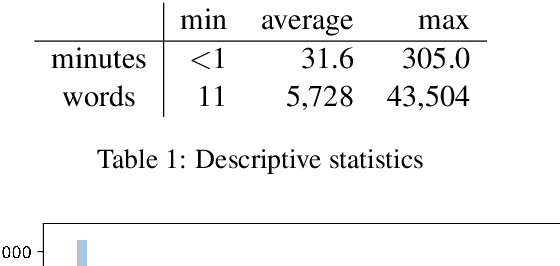

Podcasts are a relatively new form of audio media. Episodes appear on a regular cadence, and come in many different formats and levels of formality. They can be formal news journalism or conversational chat; fiction or non-fiction. They are rapidly growing in popularity and yet have been relatively little studied. As an audio format, podcasts are more varied in style and production types than, say, broadcast news, and contain many more genres than typically studied in video research. The medium is therefore a rich domain with many research avenues for the IR and NLP communities. We present the Spotify Podcasts Dataset, a set of approximately 100K podcast episodes comprised of raw audio files along with accompanying ASR transcripts. This represents over 47,000 hours of transcribed audio, and is an order of magnitude larger than previous speech-to-text corpora.
Inferring the location of authors from words in their texts
Dec 20, 2016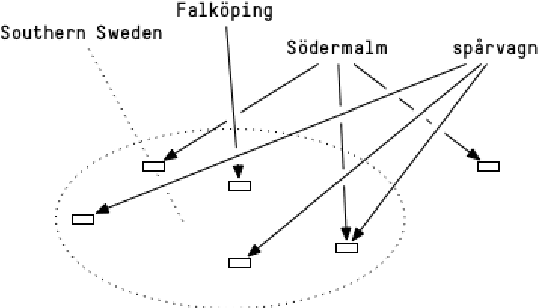

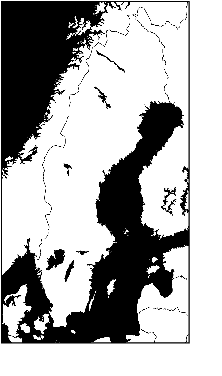

For the purposes of computational dialectology or other geographically bound text analysis tasks, texts must be annotated with their or their authors' location. Many texts are locatable through explicit labels but most have no explicit annotation of place. This paper describes a series of experiments to determine how positionally annotated microblog posts can be used to learn location-indicating words which then can be used to locate blog texts and their authors. A Gaussian distribution is used to model the locational qualities of words. We introduce the notion of placeness to describe how locational words are. We find that modelling word distributions to account for several locations and thus several Gaussian distributions per word, defining a filter which picks out words with high placeness based on their local distributional context, and aggregating locational information in a centroid for each text gives the most useful results. The results are applied to data in the Swedish language.
Viewpoint and Topic Modeling of Current Events
Aug 14, 2016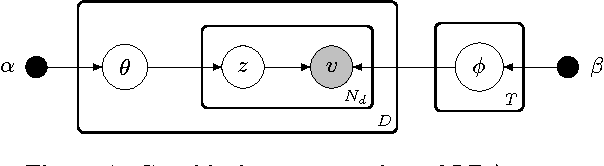

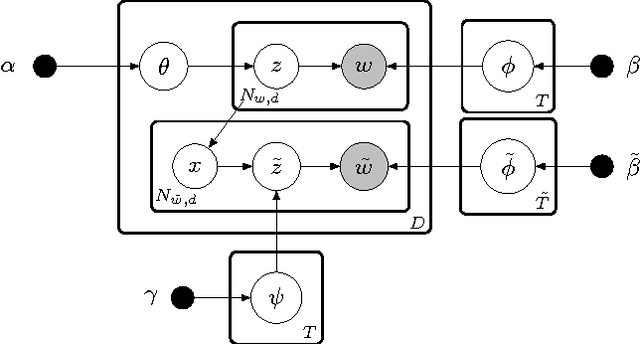

There are multiple sides to every story, and while statistical topic models have been highly successful at topically summarizing the stories in corpora of text documents, they do not explicitly address the issue of learning the different sides, the viewpoints, expressed in the documents. In this paper, we show how these viewpoints can be learned completely unsupervised and represented in a human interpretable form. We use a novel approach of applying CorrLDA2 for this purpose, which learns topic-viewpoint relations that can be used to form groups of topics, where each group represents a viewpoint. A corpus of documents about the Israeli-Palestinian conflict is then used to demonstrate how a Palestinian and an Israeli viewpoint can be learned. By leveraging the magnitudes and signs of the feature weights of a linear SVM, we introduce a principled method to evaluate associations between topics and viewpoints. With this, we demonstrate, both quantitatively and qualitatively, that the learned topic groups are contextually coherent, and form consistently correct topic-viewpoint associations.
Stylistic Variation in an Information Retrieval Experiment
Aug 08, 1996
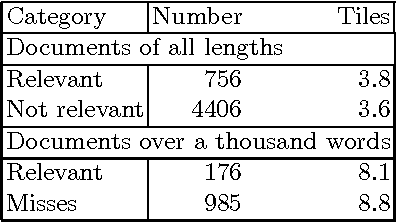
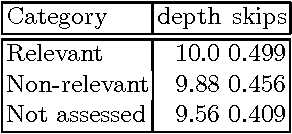
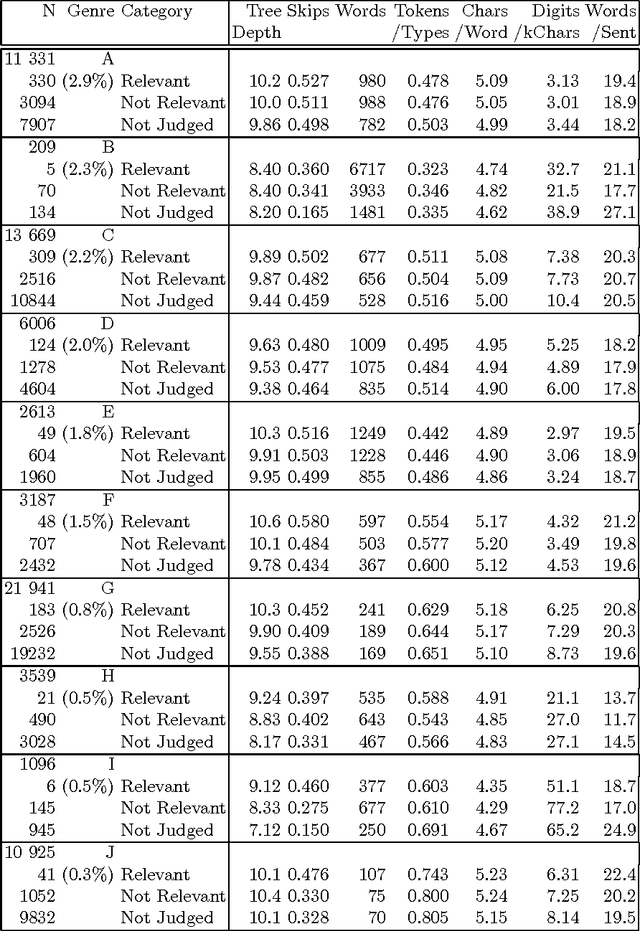
Texts exhibit considerable stylistic variation. This paper reports an experiment where a corpus of documents (N= 75 000) is analyzed using various simple stylistic metrics. A subset (n = 1000) of the corpus has been previously assessed to be relevant for answering given information retrieval queries. The experiment shows that this subset differs significantly from the rest of the corpus in terms of the stylistic metrics studied.
Dilemma - An Instant Lexicographer
Oct 21, 1994Dilemma is intended to enhance quality and increase productivity of expert human translators by presenting to the writer relevant lexical information mechanically extracted from comparable existing translations, thus replacing - or compensating for the absence of - a lexicographer and stand-by terminologist rather than the translator. Using statistics and crude surface analysis and a minimum of prior information, Dilemma identifies instances and suggests their counterparts in parallel source and target texts, on all levels down to individual words. Dilemma forms part of a tool kit for translation where focus is on text structure and over-all consistency in large text volumes rather than on framing sentences, on interaction between many actors in a large project rather than on retrieval of machine-stored data and on decision making rather than on application of given rules. In particular, the system has been tuned to the needs of the ongoing translation of European Community legislation into the languages of candidate member countries. The system has been demonstrated to and used by professional translators with promising results.
Recognizing Text Genres with Simple Metrics Using Discriminant Analysis
Oct 20, 1994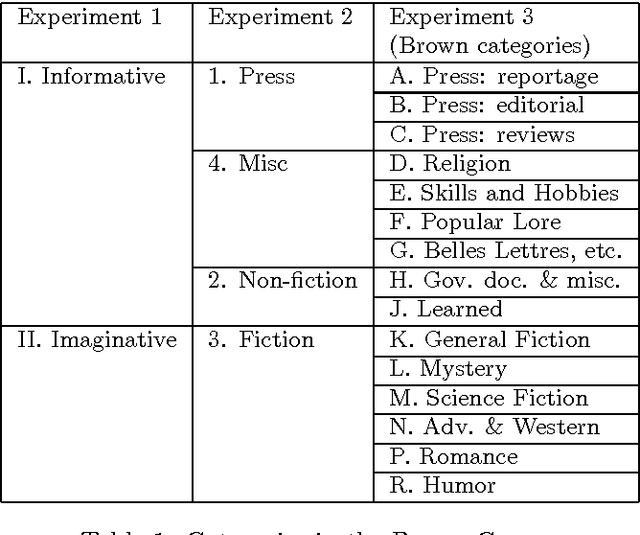
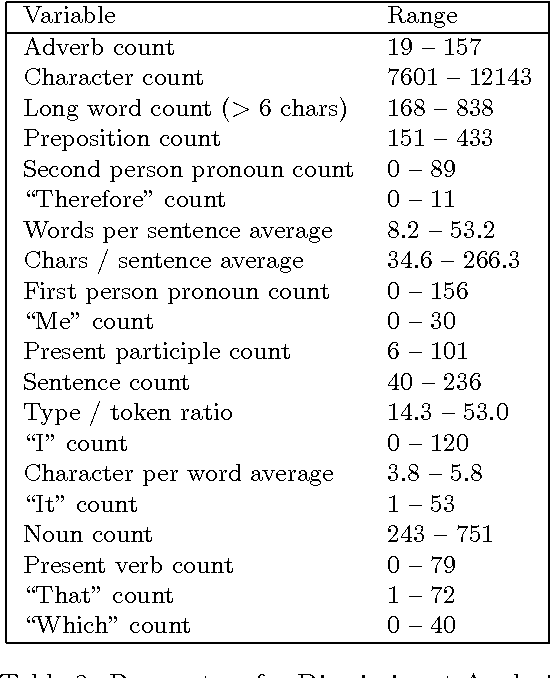


A simple method for categorizing texts into predetermined text genre categories using the statistical standard technique of discriminant analysis is demonstrated with application to the Brown corpus. Discriminant analysis makes it possible use a large number of parameters that may be specific for a certain corpus or information stream, and combine them into a small number of functions, with the parameters weighted on basis of how useful they are for discriminating text genres. An application to information retrieval is discussed.