 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-Speech Synthesis Techniques for MIDI-to-Audio Synthesis
May 17, 2021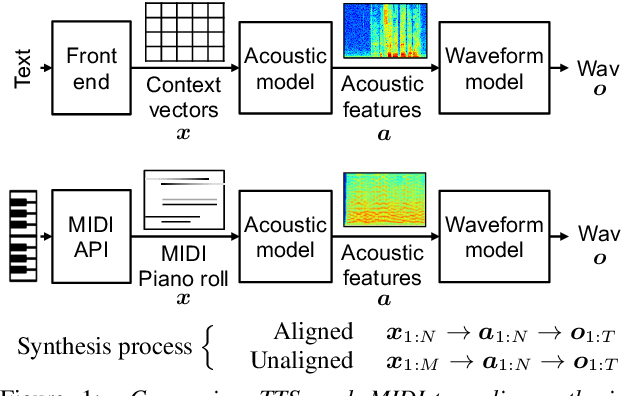
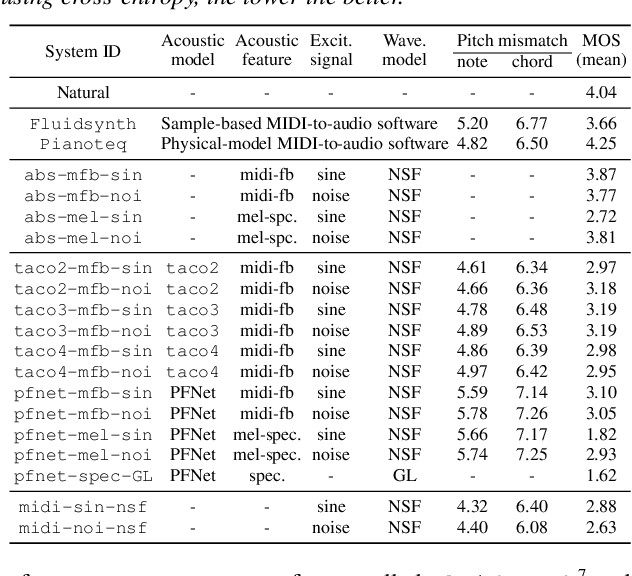
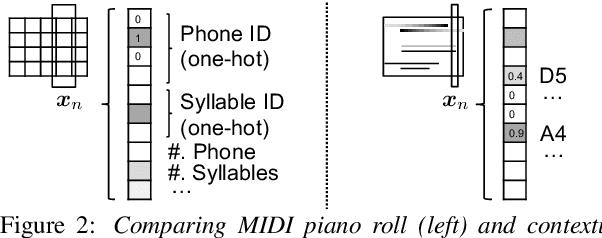
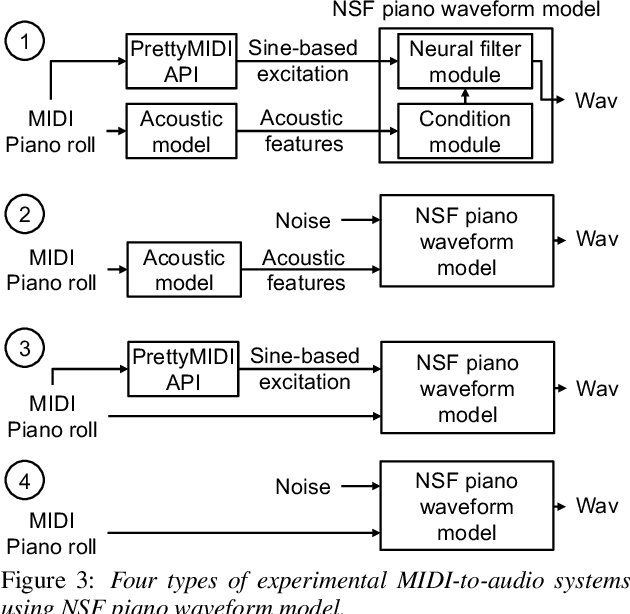
Speech synthesis and music audio generation from symbolic input differ in many aspects but share some similarities. In this study, we investigate how text-to-speech synthesis techniques can be used for piano MIDI-to-audio synthesis tasks. Our investigation includes Tacotron and neural source-filter waveform models as the basic components, with which we build MIDI-to-audio synthesis systems in similar ways to TTS frameworks. We also include reference systems using conventional sound modeling techniques such as sample-based and physical-modeling-based methods. The subjective experimental results demonstrate that the investigated TTS components can be applied to piano MIDI-to-audio synthesis with minor modifications. The results also reveal the performance bottleneck -- while the waveform model can synthesize high quality piano sound given natural acoustic features, the conversion from MIDI to acoustic features is challenging. The full MIDI-to-audio synthesis system is still inferior to the sample-based or physical-modeling-based approaches, but we encourage TTS researchers to test their TTS models for this new task and improve the performance.
How do Voices from Past Speech Synthesis Challenges Compare Today?
May 13, 2021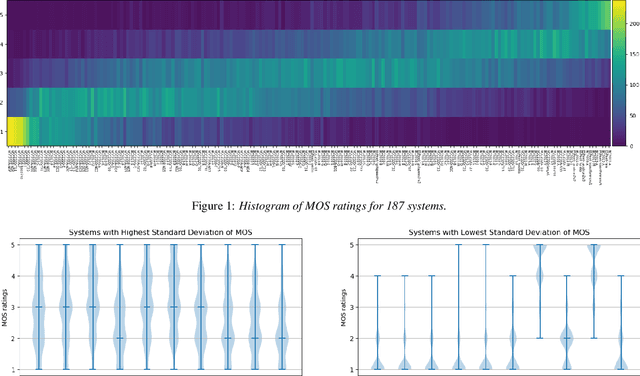
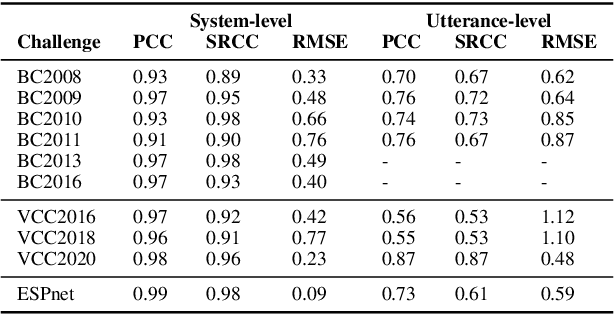

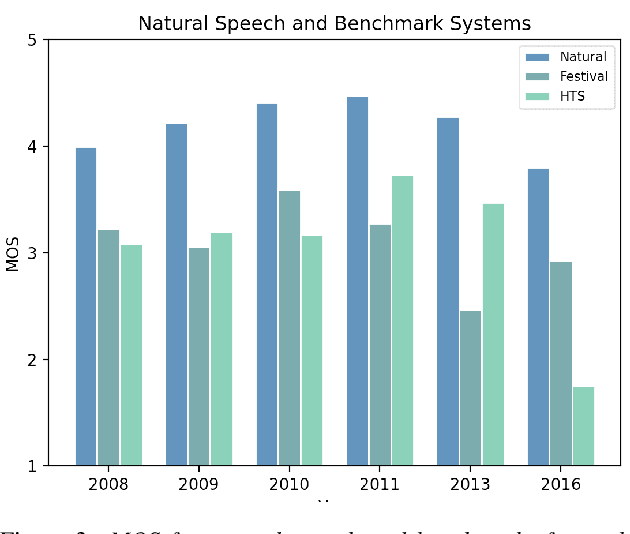
Shared challenges provide a venue for comparing systems trained on common data using a standardized evaluation, and they also provide an invaluable resource for researchers when the data and evaluation results are publicly released. The Blizzard Challenge and Voice Conversion Challenge are two such challenges for text-to-speech synthesis and for speaker conversion, respectively, and their publicly-available system samples and listening test results comprise a historical record of state-of-the-art synthesis methods over the years. In this paper, we revisit these past challenges and conduct a large-scale listening test with samples from many challenges combined. Our aims are to analyze and compare opinions of a large number of systems together, to determine whether and how opinions change over time, and to collect a large-scale dataset of a diverse variety of synthetic samples and their ratings for further research. We found strong correlations challenge by challenge at the system level between the original results and our new listening test. We also observed the importance of the choice of speaker on synthesis quality.
Exploring Disentanglement with Multilingual and Monolingual VQ-VAE
May 04, 2021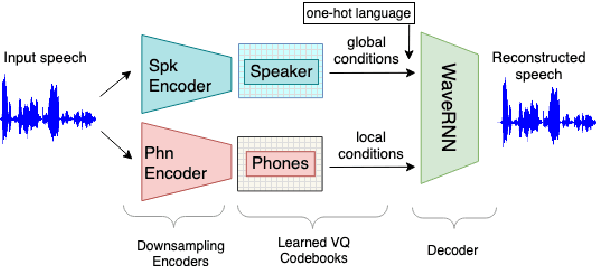
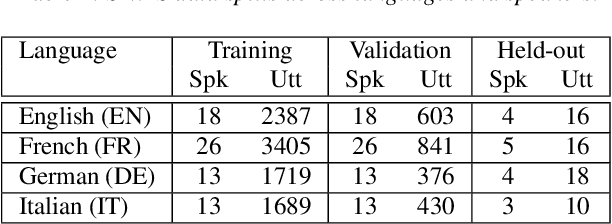
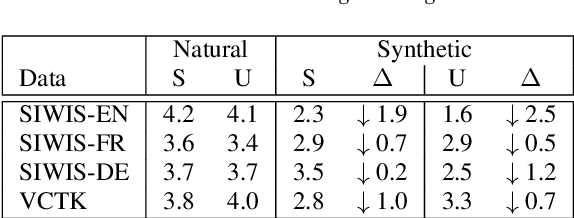
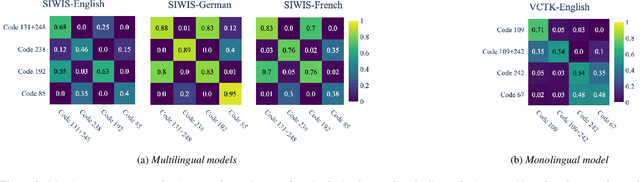
This work examines the content and usefulness of disentangled phone and speaker representations from two separately trained VQ-VAE systems: one trained on multilingual data and another trained on monolingual data. We explore the multi- and monolingual models using four small proof-of-concept tasks: copy-synthesis, voice transformation, linguistic code-switching, and content-based privacy masking. From these tasks, we reflect on how disentangled phone and speaker representations can be used to manipulate speech in a meaningful way. Our experiments demonstrate that the VQ representations are suitable for these tasks, including creating new voices by mixing speaker representations together. We also present our novel technique to conceal the content of targeted words within an utterance by manipulating phone VQ codes, while retaining speaker identity and intelligibility of surrounding words. Finally, we discuss recommendations for further increasing the viability of disentangled representations.
Fashion-Guided Adversarial Attack on Person Segmentation
Apr 20, 2021
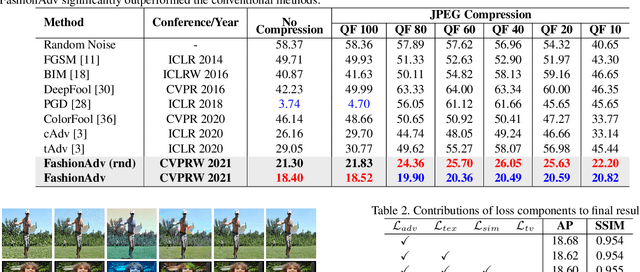

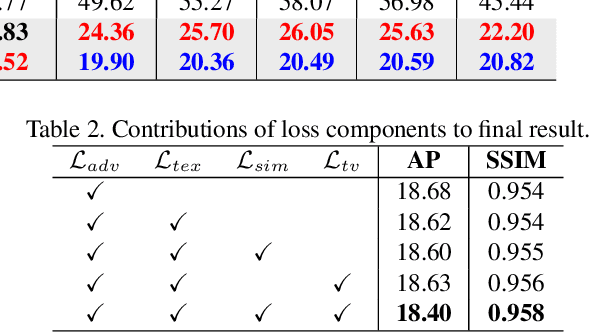
This paper presents the first adversarial example based method for attacking human instance segmentation networks, namely person segmentation networks in short, which are harder to fool than classification networks. We propose a novel Fashion-Guided Adversarial Attack (FashionAdv) framework to automatically identify attackable regions in the target image to minimize the effect on image quality. It generates adversarial textures learned from fashion style images and then overlays them on the clothing regions in the original image to make all persons in the image invisible to person segmentation networks. The synthesized adversarial textures are inconspicuous and appear natural to the human eye. The effectiveness of the proposed method is enhanced by robustness training and by jointly attacking multiple components of the target network. Extensive experiments demonstrated the effectiveness of FashionAdv in terms of robustness to image manipulations and storage in cyberspace as well as appearing natural to the human eye. The code and data are publicly released on our project page https://github.com/nii-yamagishilab/fashion_adv
* Accepted to Workshop on Media Forensics, CVPR 2021. Project page: https://github.com/nii-yamagishilab/fashion_adv
Multi-Metric Optimization using Generative Adversarial Networks for Near-End Speech Intelligibility Enhancement
Apr 17, 2021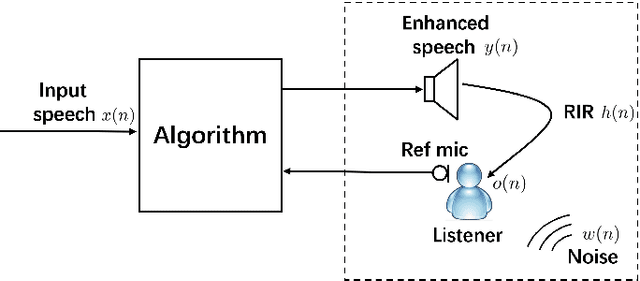
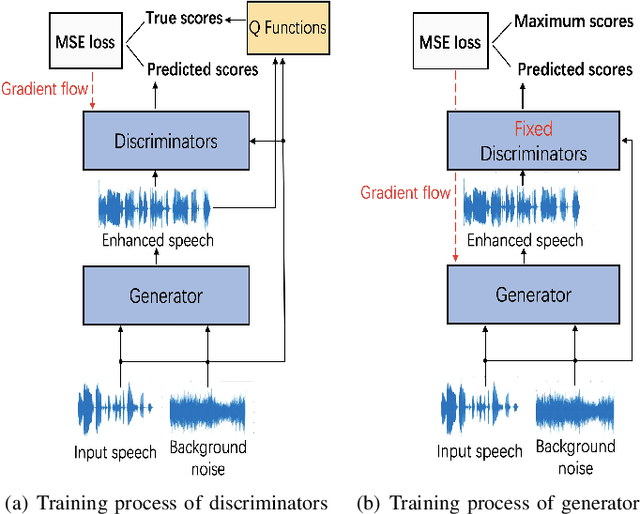
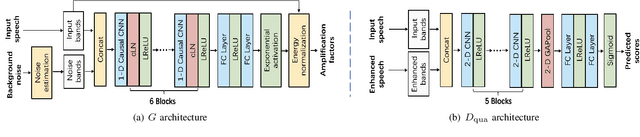
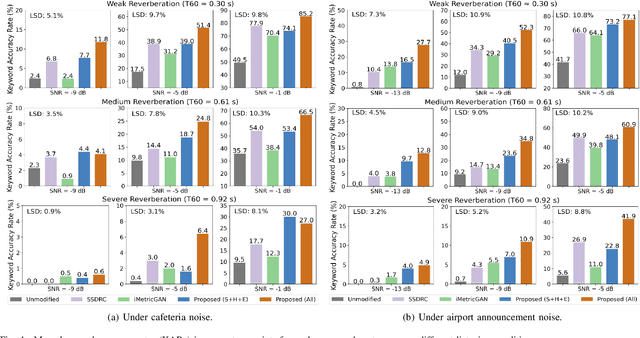
The intelligibility of speech severely degrades in the presence of environmental noise and reverberation. In this paper, we propose a novel deep learning based system for modifying the speech signal to increase its intelligibility under the equal-power constraint, i.e., signal power before and after modification must be the same. To achieve this, we use generative adversarial networks (GANs) to obtain time-frequency dependent amplification factors, which are then applied to the input raw speech to reallocate the speech energy. Instead of optimizing only a single, simple metric, we train a deep neural network (DNN) model to simultaneously optimize multiple advanced speech metrics, including both intelligibility- and quality-related ones, which results in notable improvements in performance and robustness. Our system can not only work in non-realtime mode for offline audio playback but also support practical real-time speech applications. Experimental results using both objective measurements and subjective listening tests indicate that the proposed system significantly outperforms state-ofthe-art baseline systems under various noisy and reverberant listening conditions.
An Initial Investigation for Detecting Partially Spoofed Audio
Apr 06, 2021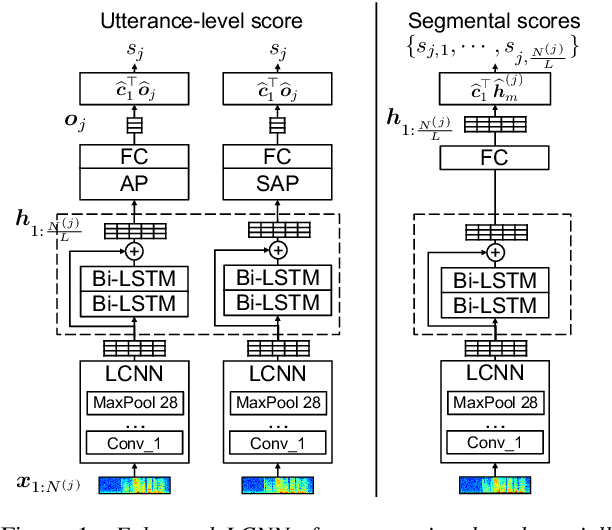
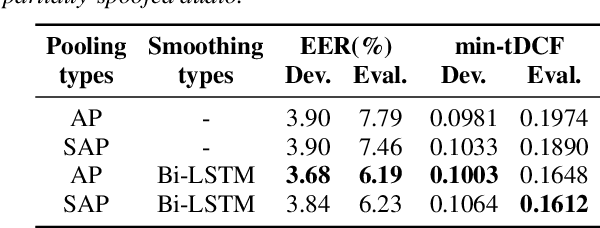
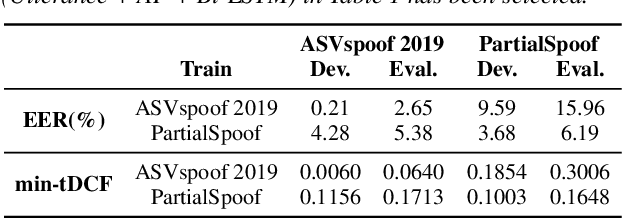
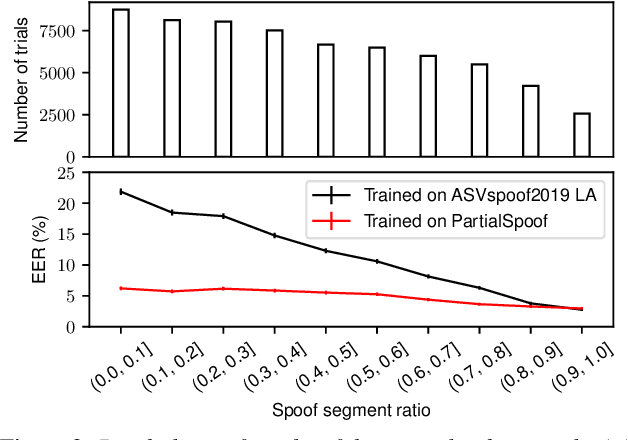
All existing databases of spoofed speech contain attack data that is spoofed in its entirety. In practice, it is entirely plausible that successful attacks can be mounted with utterances that are only partially spoofed. By definition, partially-spoofed utterances contain a mix of both spoofed and bona fide segments, which will likely degrade the performance of countermeasures trained with entirely spoofed utterances. This hypothesis raises the obvious question: 'Can we detect partially-spoofed audio?' This paper introduces a new database of partially-spoofed data, named PartialSpoof, to help address this question. This new database enables us to investigate and compare the performance of countermeasures on both utterance- and segmental- level labels. Experimental results using the utterance-level labels reveal that the reliability of countermeasures trained to detect fully-spoofed data is found to degrade substantially when tested with partially-spoofed data, whereas training on partially-spoofed data performs reliably in the case of both fully- and partially-spoofed utterances. Additional experiments using segmental-level labels show that spotting injected spoofed segments included in an utterance is a much more challenging task even if the latest countermeasure models are used.
Attention Back-end for Automatic Speaker Verification with Multiple Enrollment Utterances
Apr 04, 2021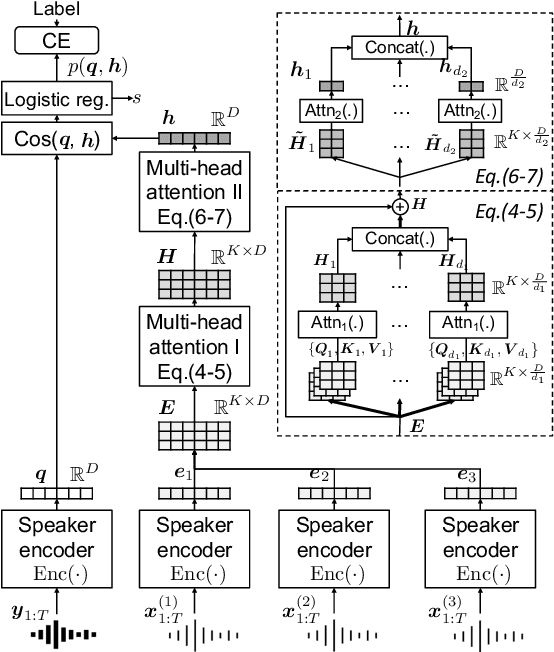
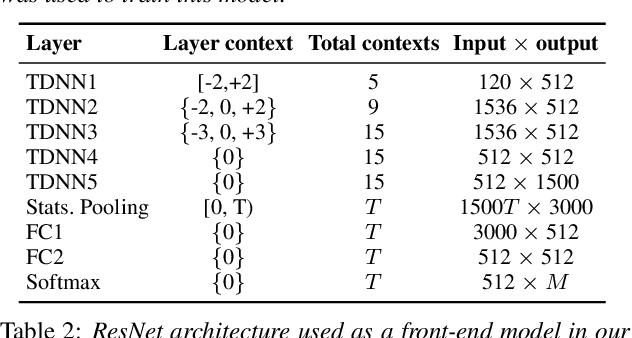
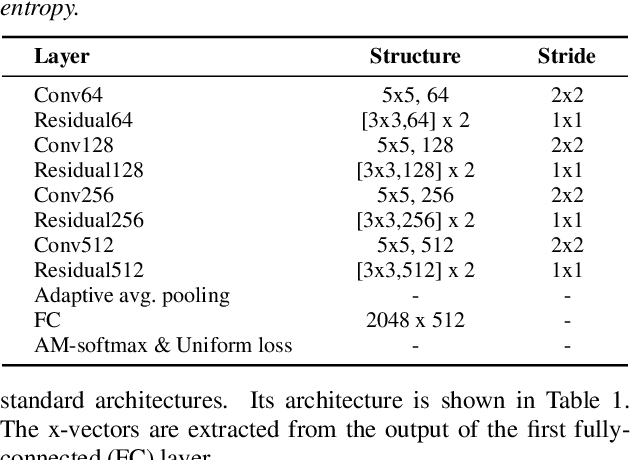
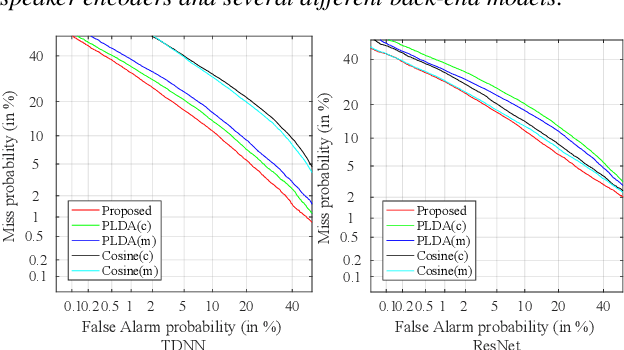
A back-end model is a key element of modern speaker verification systems. Probabilistic linear discriminant analysis (PLDA) has been widely used as a back-end model in speaker verification. However, it cannot fully make use of multiple utterances from enrollment speakers. In this paper, we propose a novel attention-based back-end model, which can be used for both text-independent (TI) and text-dependent (TD) speaker verification with multiple enrollment utterances, and employ scaled-dot self-attention and feed-forward self-attention networks as architectures that learn the intra-relationships of the enrollment utterances. In order to verify the proposed attention back-end, we combine it with two completely different but dominant speaker encoders, which are time delay neural network (TDNN) and ResNet trained using the additive-margin-based softmax loss and the uniform loss, and compare them with the conventional PLDA or cosine scoring approaches. Experimental results on a multi-genre dataset called CN-Celeb show that the performance of our proposed approach outperforms PLDA scoring with TDNN and cosine scoring with ResNet by around 14.1% and 7.8% in relative EER, respectively. Additionally, an ablation experiment is also reported in this paper for examining the impact of some significant hyper-parameters for the proposed back-end model.
ASVspoof 2019: spoofing countermeasures for the detection of synthesized, converted and replayed speech
Feb 11, 2021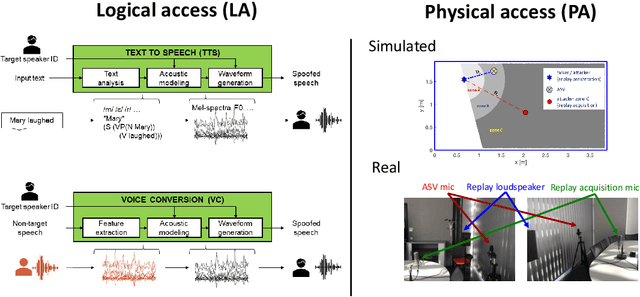
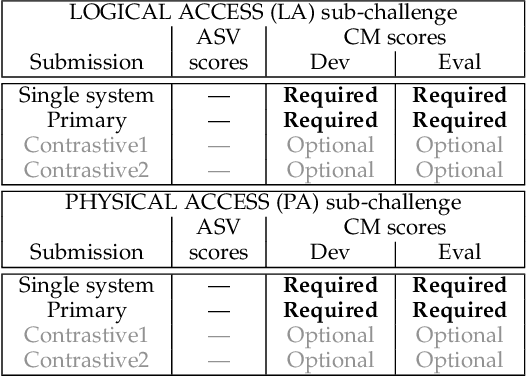
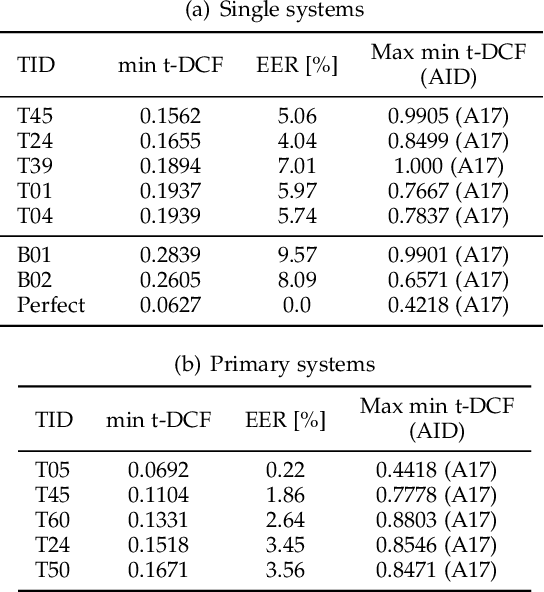
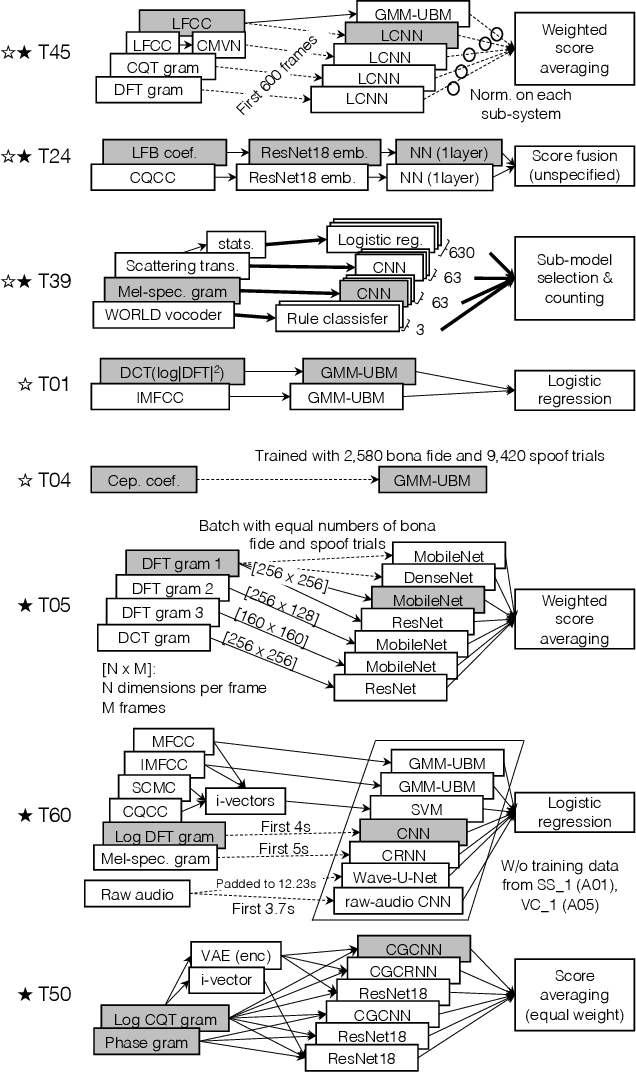
The ASVspoof initiative was conceived to spearhead research in anti-spoofing for automatic speaker verification (ASV). This paper describes the third in a series of bi-annual challenges: ASVspoof 2019. With the challenge database and protocols being described elsewhere, the focus of this paper is on results and the top performing single and ensemble system submissions from 62 teams, all of which out-perform the two baseline systems, often by a substantial margin. Deeper analyses shows that performance is dominated by specific conditions involving either specific spoofing attacks or specific acoustic environments. While fusion is shown to be particularly effective for the logical access scenario involving speech synthesis and voice conversion attacks, participants largely struggled to apply fusion successfully for the physical access scenario involving simulated replay attacks. This is likely the result of a lack of system complementarity, while oracle fusion experiments show clear potential to improve performance. Furthermore, while results for simulated data are promising, experiments with real replay data show a substantial gap, most likely due to the presence of additive noise in the latter. This finding, among others, leads to a number of ideas for further research and directions for future editions of the ASVspoof challenge.
Pretraining Strategies, Waveform Model Choice, and Acoustic Configurations for Multi-Speaker End-to-End Speech Synthesis
Nov 10, 2020
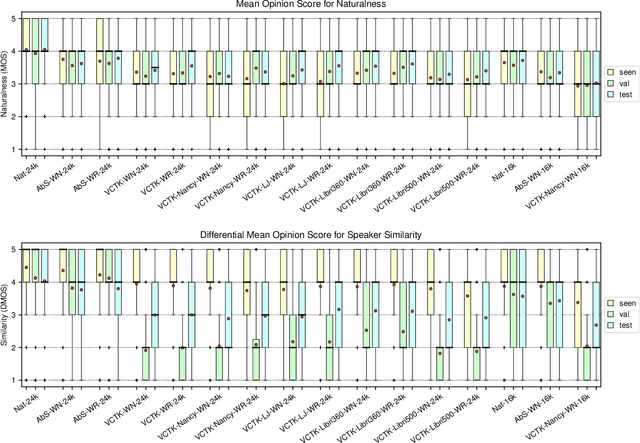
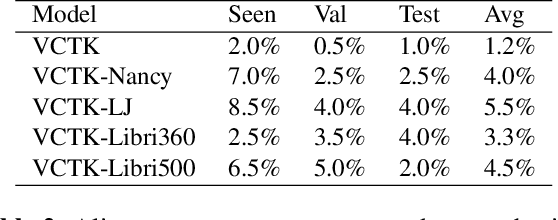
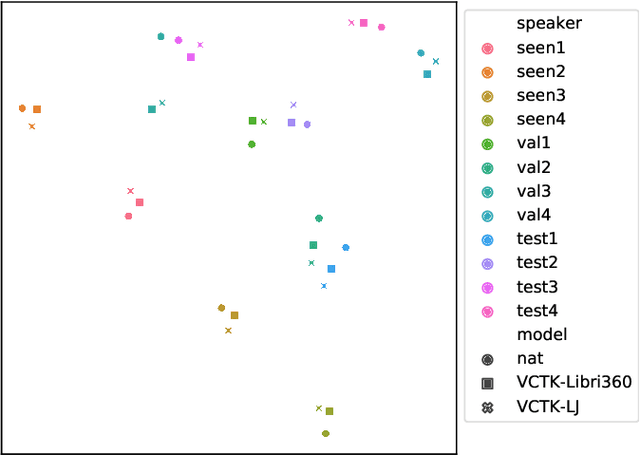
We explore pretraining strategies including choice of base corpus with the aim of choosing the best strategy for zero-shot multi-speaker end-to-end synthesis. We also examine choice of neural vocoder for waveform synthesis, as well as acoustic configurations used for mel spectrograms and final audio output. We find that fine-tuning a multi-speaker model from found audiobook data that has passed a simple quality threshold can improve naturalness and similarity to unseen target speakers of synthetic speech. Additionally, we find that listeners can discern between a 16kHz and 24kHz sampling rate, and that WaveRNN produces output waveforms of a comparable quality to WaveNet, with a faster inference time.
Learning Disentangled Phone and Speaker Representations in a Semi-Supervised VQ-VAE Paradigm
Oct 21, 2020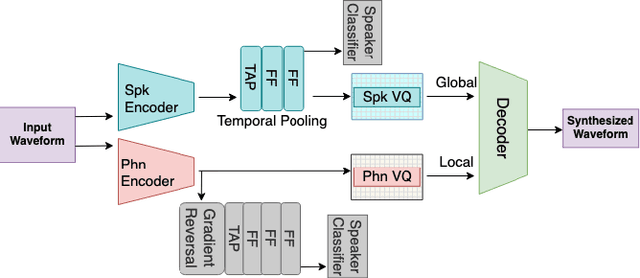
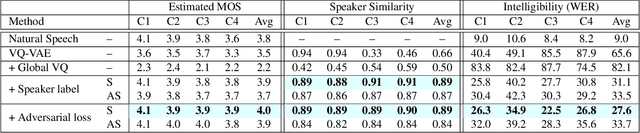

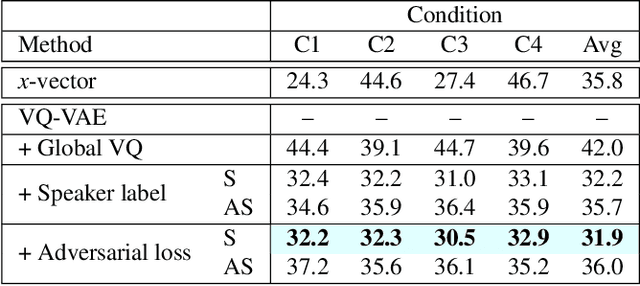
We present a new approach to disentangle speaker voice and phone content by introducing new components to the VQ-VAE architecture for speech synthesis. The original VQ-VAE does not generalize well to unseen speakers or content. To alleviate this problem, we have incorporated a speaker encoder and speaker VQ codebook that learns global speaker characteristics entirely separate from the existing sub-phone codebooks. We also compare two training methods: self-supervised with global conditions and semi-supervised with speaker labels. Adding a speaker VQ component improves objective measures of speech synthesis quality (estimated MOS, speaker similarity, ASR-based intelligibility) and provides learned representations that are meaningful. Our speaker VQ codebook indices can be used in a simple speaker diarization task and perform slightly better than an x-vector baseline. Additionally, phones can be recognized from sub-phone VQ codebook indices in our semi-supervised VQ-VAE better than self-supervised with global conditions.