 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuide your favorite protein sequence generative model
May 07, 2025Generative machine learning models have begun to transform protein engineering, yet no principled framework for conditioning on auxiliary information in a plug-and-play manner exists; one may want to iteratively incorporate experimental feedback, or make use of an existing classifier -- such as for predicting enzyme commission number -- in order to guide the sampling of the generative model to generate sequences with desired properties. Herein, we present ProteinGuide, a rigorous and general framework to achieve just that: through unifying a broad class of protein generative models that includes masked language, (order-agnostic) autoregressive, diffusion and flow-matching models, we provide an approach to statistically condition pre-trained protein generative models. We demonstrate applicability of our approach by guiding each of two commonly used protein generative models, ProteinMPNN and ESM3, to generate amino acid and structure token sequences conditioned on several user-specified properties, namely, enhanced stability and CATH-labeled fold generation.
Unlocking Guidance for Discrete State-Space Diffusion and Flow Models
Jun 03, 2024Generative models on discrete state-spaces have a wide range of potential applications, particularly in the domain of natural sciences. In continuous state-spaces, controllable and flexible generation of samples with desired properties has been realized using guidance on diffusion and flow models. However, these guidance approaches are not readily amenable to discrete state-space models. Consequently, we introduce a general and principled method for applying guidance on such models. Our method depends on leveraging continuous-time Markov processes on discrete state-spaces, which unlocks computational tractability for sampling from a desired guided distribution. We demonstrate the utility of our approach, Discrete Guidance, on a range of applications including guided generation of images, small-molecules, DNA sequences and protein sequences.
mgcpy: A Comprehensive High Dimensional Independence Testing Python Package
Jul 18, 2019
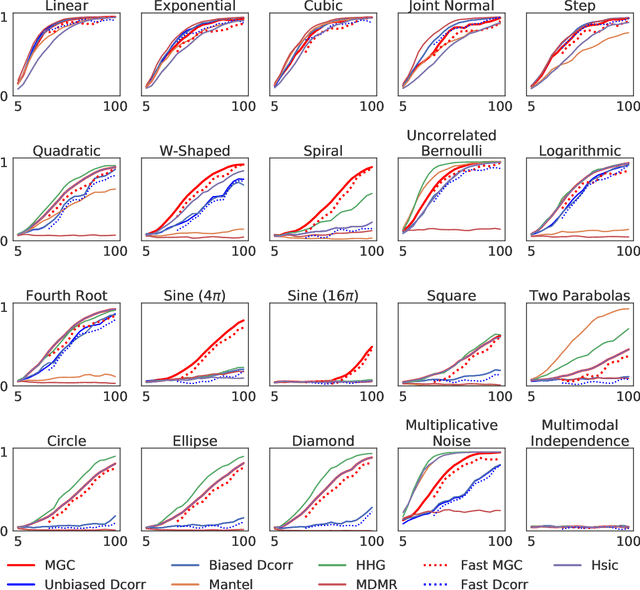
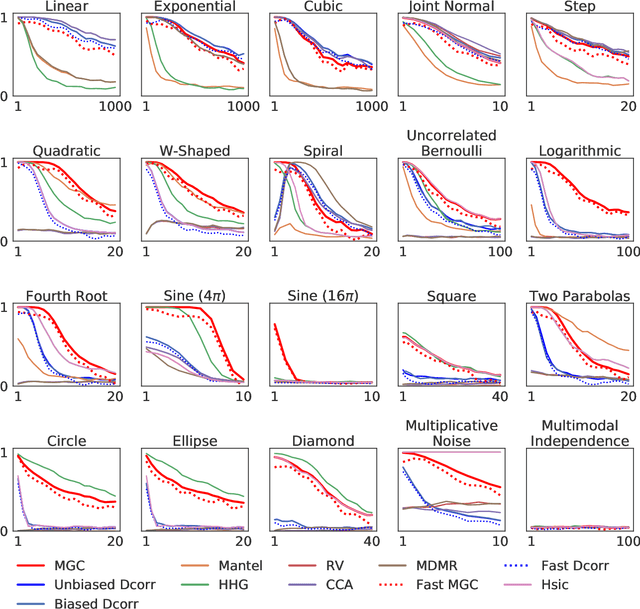
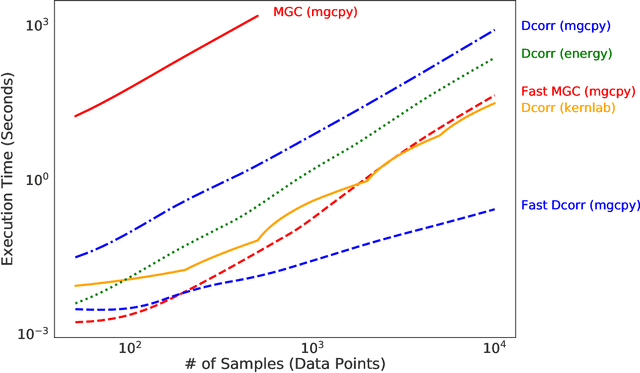
With the increase in the amount of data in many fields, a method to consistently and efficiently decipher relationships within high dimensional data sets is important. Because many modern datasets are high-dimensional, univariate independence tests are not applicable. While many multivariate independence tests have R packages available, the interfaces are inconsistent, most are not available in Python. mgcpy is an extensive Python library that includes many state of the art high-dimensional independence testing procedures using a common interface. The package is easy-to-use and is flexible enough to enable future extensions. This manuscript provides details for each of the tests as well as extensive power and run-time benchmarks on a suite of high-dimensional simulations previously used in different publications. The appendix includes demonstrations of how the user can interact with the package, as well as links and documentation.