 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Interaction-Aware 3D Reconstruction from a Single Image
Apr 07, 2026Reconstructing textured 3D human models from a single image is fundamental for AR/VR and digital human applications. However, existing methods mostly focus on single individuals and thus fail in multi-human scenes, where naive composition of individual reconstructions often leads to artifacts such as unrealistic overlaps, missing geometry in occluded regions, and distorted interactions. These limitations highlight the need for approaches that incorporate group-level context and interaction priors. We introduce a holistic method that explicitly models both group- and instance-level information. To mitigate perspective-induced geometric distortions, we first transform the input into a canonical orthographic space. Our primary component, Human Group-Instance Multi-View Diffusion (HUG-MVD), then generates complete multi-view normals and images by jointly modeling individuals and group context to resolve occlusions and proximity. Subsequently, the Human Group-Instance Geometric Reconstruction (HUG-GR) module optimizes the geometry by leveraging explicit, physics-based interaction priors to enforce physical plausibility and accurately model inter-human contact. Finally, the multi-view images are fused into a high-fidelity texture. Together, these components form our complete framework, HUG3D. Extensive experiments show that HUG3D significantly outperforms both single-human and existing multi-human methods, producing physically plausible, high-fidelity 3D reconstructions of interacting people from a single image. Project page: https://jongheean11.github.io/HUG3D_project
Uncertainty-guided Compositional Alignment with Part-to-Whole Semantic Representativeness in Hyperbolic Vision-Language Models
Mar 23, 2026While Vision-Language Models (VLMs) have achieved remarkable performance, their Euclidean embeddings remain limited in capturing hierarchical relationships such as part-to-whole or parent-child structures, and often face challenges in multi-object compositional scenarios. Hyperbolic VLMs mitigate this issue by better preserving hierarchical structures and modeling part-whole relations (i.e., whole scene and its part images) through entailment. However, existing approaches do not model that each part has a different level of semantic representativeness to the whole. We propose UNcertainty-guided Compositional Hyperbolic Alignment (UNCHA) for enhancing hyperbolic VLMs. UNCHA models part-to-whole semantic representativeness with hyperbolic uncertainty, by assigning lower uncertainty to more representative parts and higher uncertainty to less representative ones for the whole scene. This representativeness is then incorporated into the contrastive objective with uncertainty-guided weights. Finally, the uncertainty is further calibrated with an entailment loss regularized by entropy-based term. With the proposed losses, UNCHA learns hyperbolic embeddings with more accurate part-whole ordering, capturing the underlying compositional structure in an image and improving its understanding of complex multi-object scenes. UNCHA achieves state-of-the-art performance on zero-shot classification, retrieval, and multi-label classification benchmarks. Our code and models are available at: https://github.com/jeeit17/UNCHA.git.
DiffBMP: Differentiable Rendering with Bitmap Primitives
Feb 26, 2026We introduce DiffBMP, a scalable and efficient differentiable rendering engine for a collection of bitmap images. Our work addresses a limitation that traditional differentiable renderers are constrained to vector graphics, given that most images in the world are bitmaps. Our core contribution is a highly parallelized rendering pipeline, featuring a custom CUDA implementation for calculating gradients. This system can, for example, optimize the position, rotation, scale, color, and opacity of thousands of bitmap primitives all in under 1 min using a consumer GPU. We employ and validate several techniques to facilitate the optimization: soft rasterization via Gaussian blur, structure-aware initialization, noisy canvas, and specialized losses/heuristics for videos or spatially constrained images. We demonstrate DiffBMP is not just an isolated tool, but a practical one designed to integrate into creative workflows. It supports exporting compositions to a native, layered file format, and the entire framework is publicly accessible via an easy-to-hack Python package.
One-Shot Item Search with Multimodal Data
Nov 28, 2018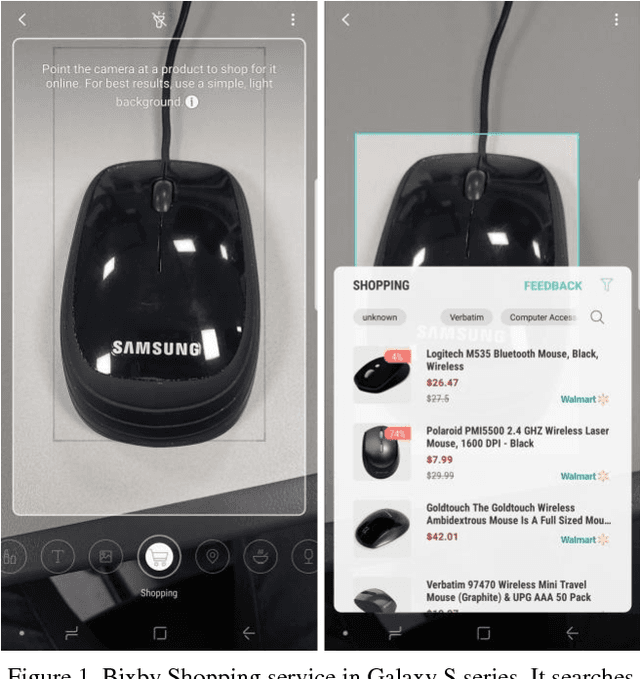
In the task of near similar image search, features from Deep Neural Network is often used to compare images and measure similarity. In the past, we only focused visual search in image dataset without text data. However, since deep neural network emerged, the performance of visual search becomes high enough to apply it in many industries from 3D data to multimodal data. Compared to the needs of multimodal search, there has not been sufficient researches. In this paper, we present a method of near similar search with image and text multimodal dataset. Earlier time, similar image search, especially when searching shopping items, treated image and text separately to search similar items and reorder the results. This regards two tasks of image search and text matching as two different tasks. Our method, however, explore the vast data to compute k-nearest neighbors using both image and text. In our experiment of similar item search, our system using multimodal data shows better performance than single data while it only increases minute computing time. For the experiment, we collected more than 15 million of accessory and six million of digital product items from online shopping websites, in which the product item comprises item images, titles, categories, and descriptions. Then we compare the performance of multimodal searching to single space searching in these datasets.