 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight and Efficient Image Super-Resolution with Block State-based Recursive Network
Nov 30, 2018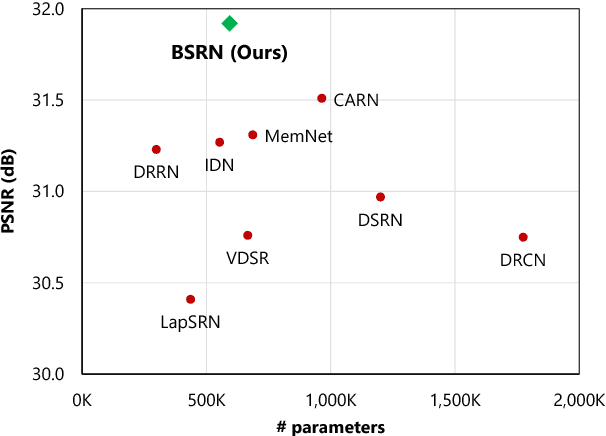
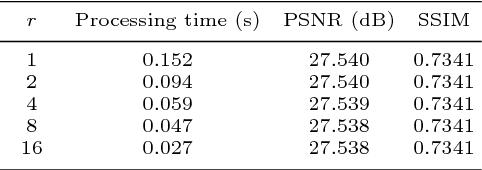
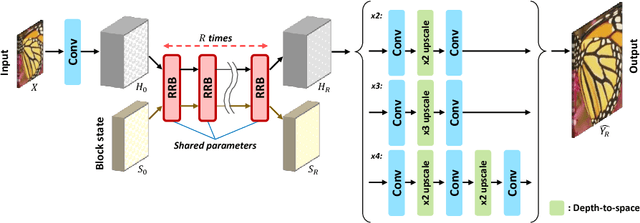
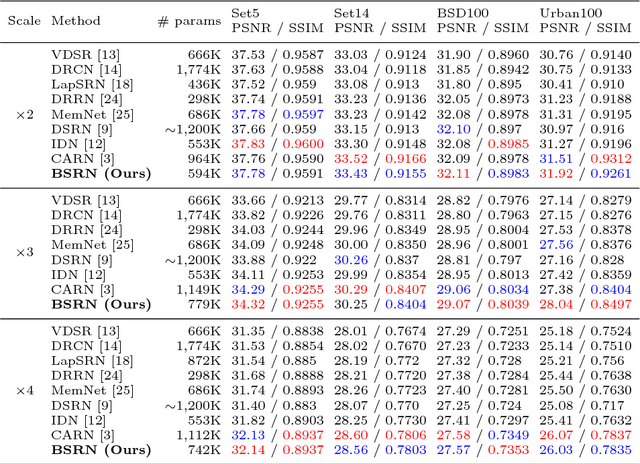
Recently, several deep learning-based image super-resolution methods have been developed by stacking massive numbers of layers. However, this leads too large model sizes and high computational complexities, thus some recursive parameter-sharing methods have been also proposed. Nevertheless, their designs do not properly utilize the potential of the recursive operation. In this paper, we propose a novel, lightweight, and efficient super-resolution method to maximize the usefulness of the recursive architecture, by introducing block state-based recursive network. By taking advantage of utilizing the block state, the recursive part of our model can easily track the status of the current image features. We show the benefits of the proposed method in terms of model size, speed, and efficiency. In addition, we show that our method outperforms the other state-of-the-art methods.
RAM: Residual Attention Module for Single Image Super-Resolution
Nov 29, 2018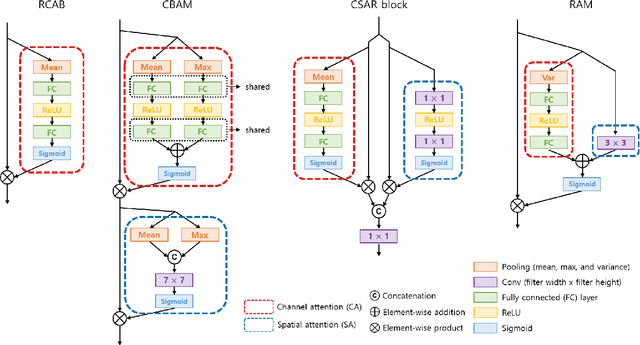
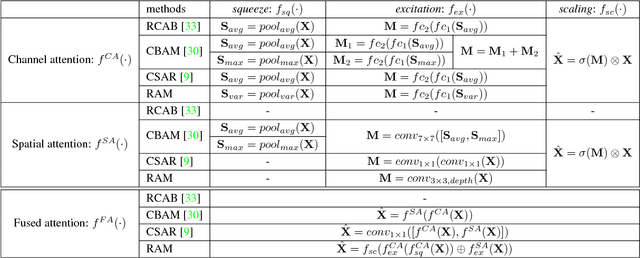

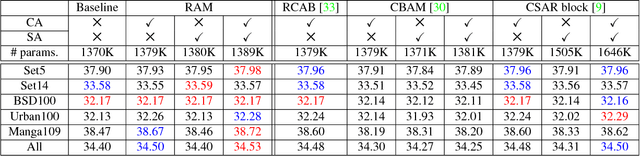
Attention mechanisms are a design trend of deep neural networks that stands out in various computer vision tasks. Recently, some works have attempted to apply attention mechanisms to single image super-resolution (SR) tasks. However, they apply the mechanisms to SR in the same or similar ways used for high-level computer vision problems without much consideration of the different nature between SR and other problems. In this paper, we propose a new attention method, which is composed of new channel-wise and spatial attention mechanisms optimized for SR and a new fused attention to combine them. Based on this, we propose a new residual attention module (RAM) and a SR network using RAM (SRRAM). We provide in-depth experimental analysis of different attention mechanisms in SR. It is shown that the proposed method can construct both deep and lightweight SR networks showing improved performance in comparison to existing state-of-the-art methods.
Generative adversarial network-based image super-resolution using perceptual content losses
Sep 21, 2018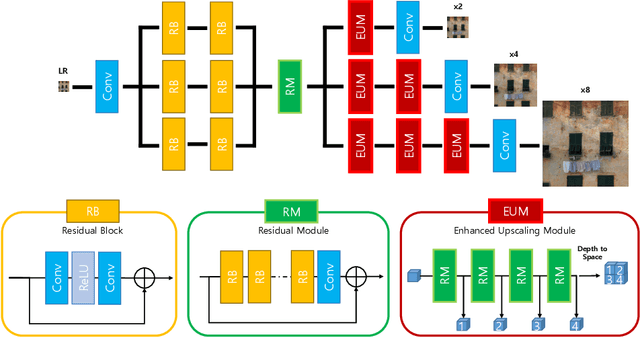
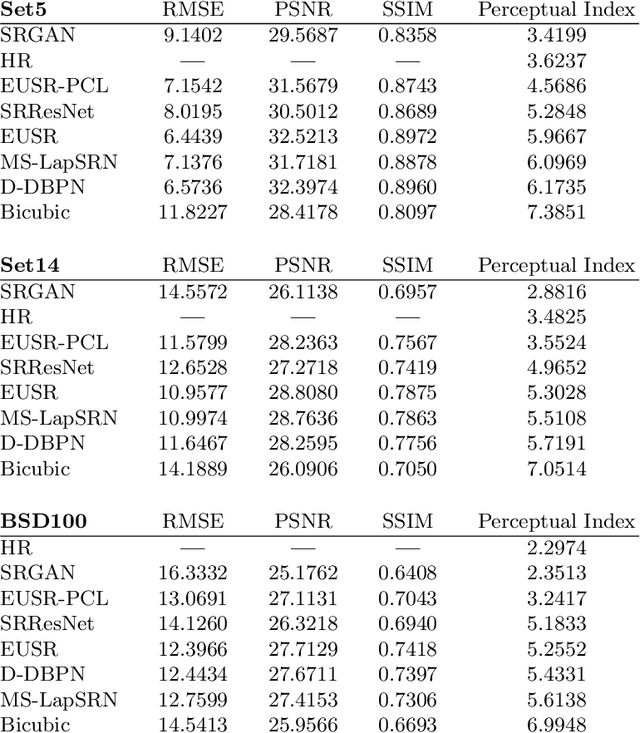

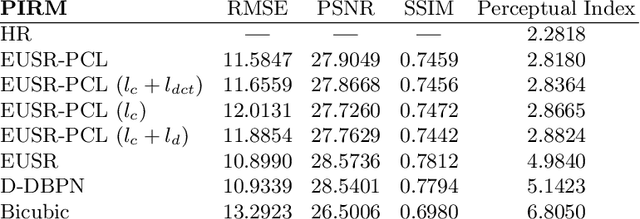
In this paper, we propose a deep generative adversarial network for super-resolution considering the trade-off between perception and distortion. Based on good performance of a recently developed model for super-resolution, i.e., deep residual network using enhanced upscale modules (EUSR), the proposed model is trained to improve perceptual performance with only slight increase of distortion. For this purpose, together with the conventional content loss, i.e., reconstruction loss such as L1 or L2, we consider additional losses in the training phase, which are the discrete cosine transform coefficients loss and differential content loss. These consider perceptual part in the content loss, i.e., consideration of proper high frequency components is helpful for the trade-off problem in super-resolution. The experimental results show that our proposed model has good performance for both perception and distortion, and is effective in perceptual super-resolution applications.
Deep Learning-based Image Super-Resolution Considering Quantitative and Perceptual Quality
Sep 13, 2018
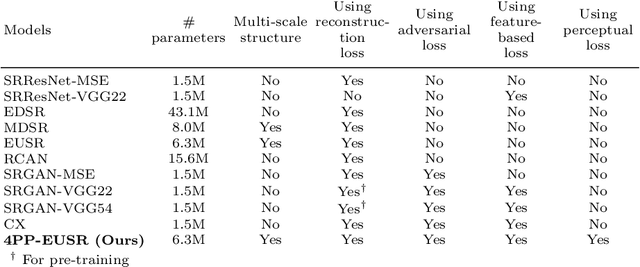
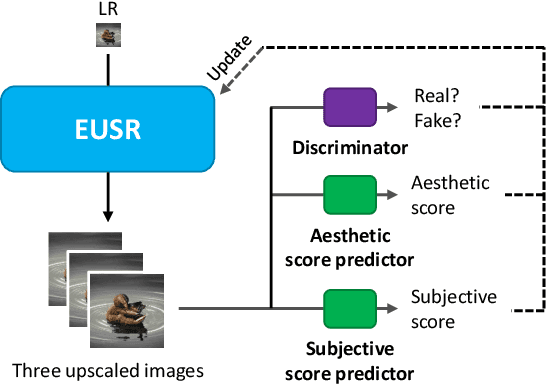
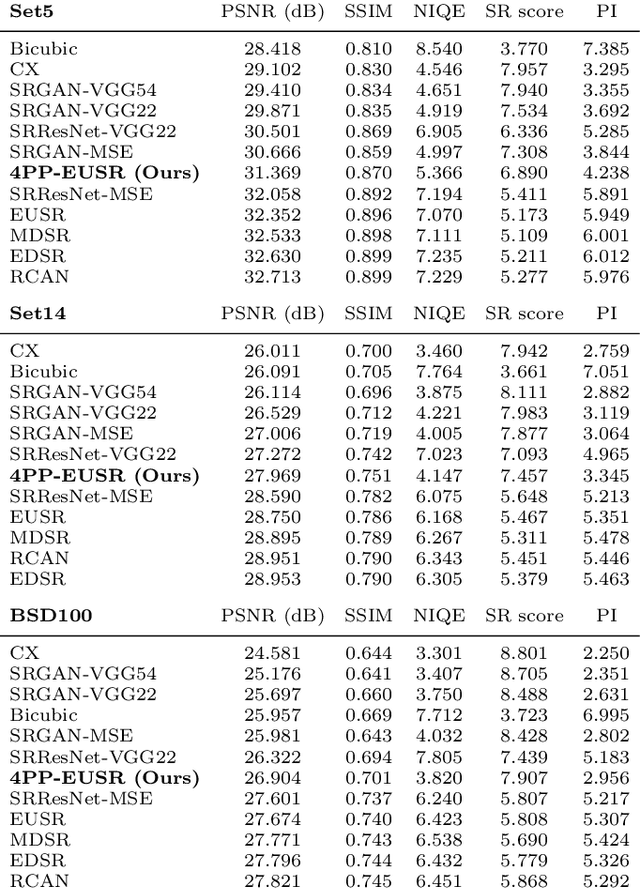
Recently, it has been shown that in super-resolution, there exists a tradeoff relationship between the quantitative and perceptual quality of super-resolved images, which correspond to the similarity to the ground-truth images and the naturalness, respectively. In this paper, we propose a novel super-resolution method that can improve the perceptual quality of the upscaled images while preserving the conventional quantitative performance. The proposed method employs a deep network for multi-pass upscaling in company with a discriminator network and two quantitative score predictor networks. Experimental results demonstrate that the proposed method achieves a good balance of the quantitative and perceptual quality, showing more satisfactory results than existing methods.