 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn In-depth Study of LLM Contributions to the Bin Packing Problem
Oct 31, 2025Recent studies have suggested that Large Language Models (LLMs) could provide interesting ideas contributing to mathematical discovery. This claim was motivated by reports that LLM-based genetic algorithms produced heuristics offering new insights into the online bin packing problem under uniform and Weibull distributions. In this work, we reassess this claim through a detailed analysis of the heuristics produced by LLMs, examining both their behavior and interpretability. Despite being human-readable, these heuristics remain largely opaque even to domain experts. Building on this analysis, we propose a new class of algorithms tailored to these specific bin packing instances. The derived algorithms are significantly simpler, more efficient, more interpretable, and more generalizable, suggesting that the considered instances are themselves relatively simple. We then discuss the limitations of the claim regarding LLMs' contribution to this problem, which appears to rest on the mistaken assumption that the instances had previously been studied. Our findings instead emphasize the need for rigorous validation and contextualization when assessing the scientific value of LLM-generated outputs.
Optimal checkpointing for heterogeneous chains: how to train deep neural networks with limited memory
Nov 27, 2019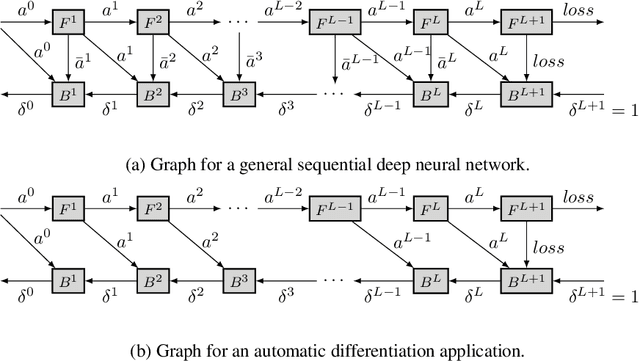

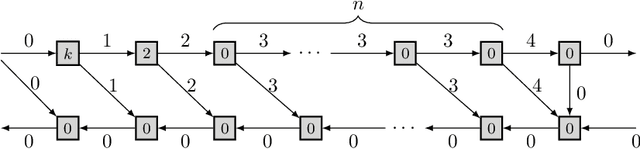
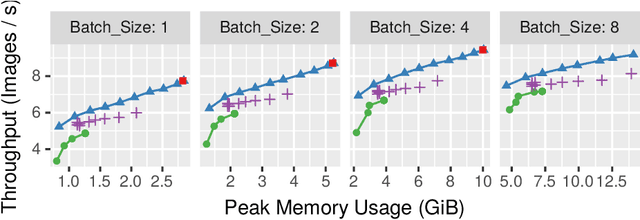
This paper introduces a new activation checkpointing method which allows to significantly decrease memory usage when training Deep Neural Networks with the back-propagation algorithm. Similarly to checkpoint-ing techniques coming from the literature on Automatic Differentiation, it consists in dynamically selecting the forward activations that are saved during the training phase, and then automatically recomputing missing activations from those previously recorded. We propose an original computation model that combines two types of activation savings: either only storing the layer inputs, or recording the complete history of operations that produced the outputs (this uses more memory, but requires fewer recomputations in the backward phase), and we provide an algorithm to compute the optimal computation sequence for this model. This paper also describes a PyTorch implementation that processes the entire chain, dealing with any sequential DNN whose internal layers may be arbitrarily complex and automatically executing it according to the optimal checkpointing strategy computed given a memory limit. Through extensive experiments, we show that our implementation consistently outperforms existing checkpoint-ing approaches for a large class of networks, image sizes and batch sizes.