 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Label Noise through Data Ambiguation
May 23, 2023



Label noise poses an important challenge in machine learning, especially in deep learning, in which large models with high expressive power dominate the field. Models of that kind are prone to memorizing incorrect labels, thereby harming generalization performance. Many methods have been proposed to address this problem, including robust loss functions and more complex label correction approaches. Robust loss functions are appealing due to their simplicity, but typically lack flexibility, while label correction usually adds substantial complexity to the training setup. In this paper, we suggest to address the shortcomings of both methodologies by "ambiguating" the target information, adding additional, complementary candidate labels in case the learner is not sufficiently convinced of the observed training label. More precisely, we leverage the framework of so-called superset learning to construct set-valued targets based on a confidence threshold, which deliver imprecise yet more reliable beliefs about the ground-truth, effectively helping the learner to suppress the memorization effect. In an extensive empirical evaluation, our method demonstrates favorable learning behavior on synthetic and real-world noise, confirming the effectiveness in detecting and correcting erroneous training labels.
Detecting Novelties with Empty Classes
Apr 30, 2023



For open world applications, deep neural networks (DNNs) need to be aware of previously unseen data and adaptable to evolving environments. Furthermore, it is desirable to detect and learn novel classes which are not included in the DNNs underlying set of semantic classes in an unsupervised fashion. The method proposed in this article builds upon anomaly detection to retrieve out-of-distribution (OoD) data as candidates for new classes. We thereafter extend the DNN by $k$ empty classes and fine-tune it on the OoD data samples. To this end, we introduce two loss functions, which 1) entice the DNN to assign OoD samples to the empty classes and 2) to minimize the inner-class feature distances between them. Thus, instead of ground truth which contains labels for the different novel classes, the DNN obtains a single OoD label together with a distance matrix, which is computed in advance. We perform several experiments for image classification and semantic segmentation, which demonstrate that a DNN can extend its own semantic space by multiple classes without having access to ground truth.
Memorization-Dilation: Modeling Neural Collapse Under Noise
Jun 11, 2022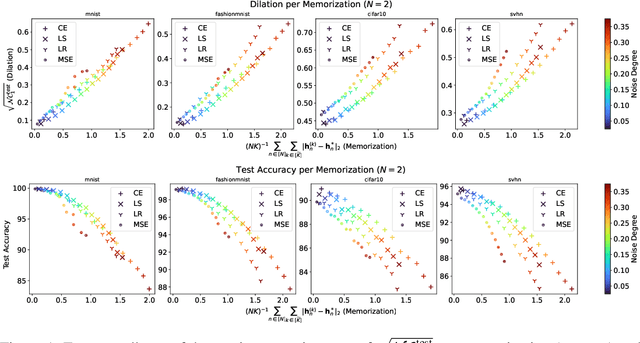

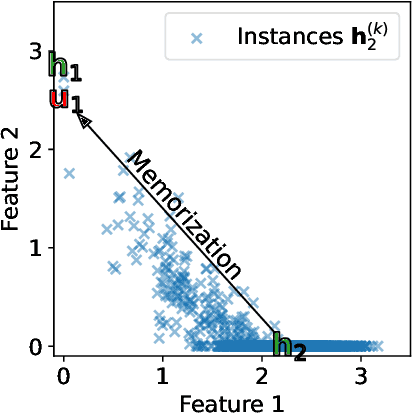
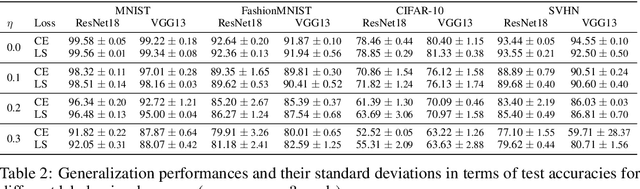
The notion of neural collapse refers to several emergent phenomena that have been empirically observed across various canonical classification problems. During the terminal phase of training a deep neural network, the feature embedding of all examples of the same class tend to collapse to a single representation, and the features of different classes tend to separate as much as possible. Neural collapse is often studied through a simplified model, called the unconstrained feature representation, in which the model is assumed to have "infinite expressivity" and can map each data point to any arbitrary representation. In this work, we propose a more realistic variant of the unconstrained feature representation that takes the limited expressivity of the network into account. Empirical evidence suggests that the memorization of noisy data points leads to a degradation (dilation) of the neural collapse. Using a model of the memorization-dilation (M-D) phenomenon, we show one mechanism by which different losses lead to different performances of the trained network on noisy data. Our proofs reveal why label smoothing, a modification of cross-entropy empirically observed to produce a regularization effect, leads to improved generalization in classification tasks.
Conformal Credal Self-Supervised Learning
May 30, 2022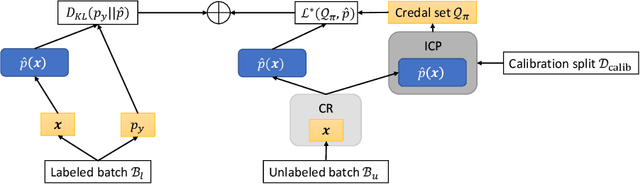
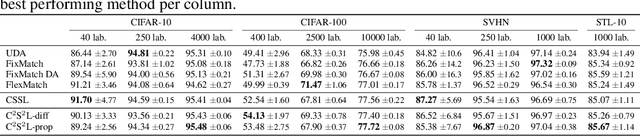
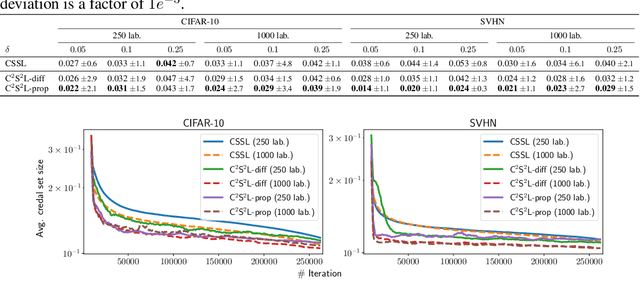
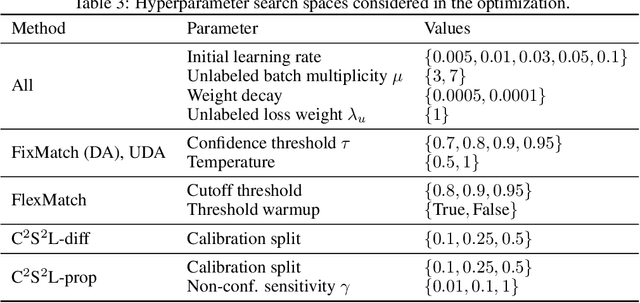
In semi-supervised learning, the paradigm of self-training refers to the idea of learning from pseudo-labels suggested by the learner itself. Across various domains, corresponding methods have proven effective and achieve state-of-the-art performance. However, pseudo-labels typically stem from ad-hoc heuristics, relying on the quality of the predictions though without guaranteeing their validity. One such method, so-called credal self-supervised learning, maintains pseudo-supervision in the form of sets of (instead of single) probability distributions over labels, thereby allowing for a flexible yet uncertainty-aware labeling. Again, however, there is no justification beyond empirical effectiveness. To address this deficiency, we make use of conformal prediction, an approach that comes with guarantees on the validity of set-valued predictions. As a result, the construction of credal sets of labels is supported by a rigorous theoretical foundation, leading to better calibrated and less error-prone supervision for unlabeled data. Along with this, we present effective algorithms for learning from credal self-supervision. An empirical study demonstrates excellent calibration properties of the pseudo-supervision, as well as the competitiveness of our method on several benchmark datasets.
Kronecker Decomposition for Knowledge Graph Embeddings
May 13, 2022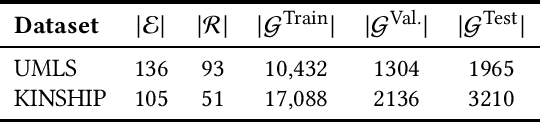
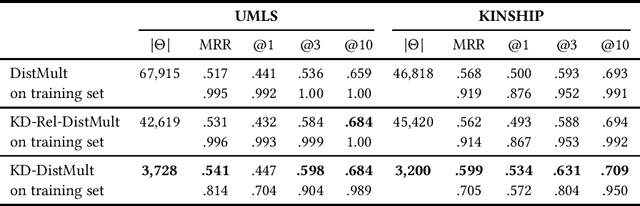
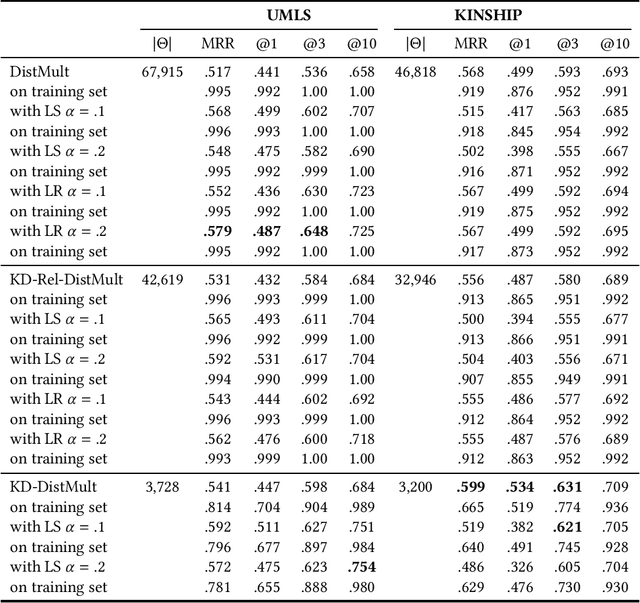
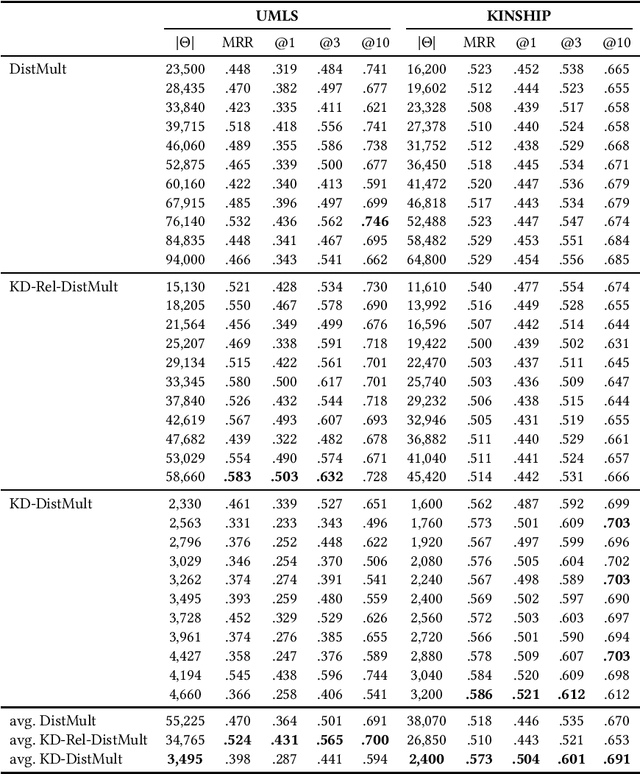
Knowledge graph embedding research has mainly focused on learning continuous representations of entities and relations tailored towards the link prediction problem. Recent results indicate an ever increasing predictive ability of current approaches on benchmark datasets. However, this effectiveness often comes with the cost of over-parameterization and increased computationally complexity. The former induces extensive hyperparameter optimization to mitigate malicious overfitting. The latter magnifies the importance of winning the hardware lottery. Here, we investigate a remedy for the first problem. We propose a technique based on Kronecker decomposition to reduce the number of parameters in a knowledge graph embedding model, while retaining its expressiveness. Through Kronecker decomposition, large embedding matrices are split into smaller embedding matrices during the training process. Hence, embeddings of knowledge graphs are not plainly retrieved but reconstructed on the fly. The decomposition ensures that elementwise interactions between three embedding vectors are extended with interactions within each embedding vector. This implicitly reduces redundancy in embedding vectors and encourages feature reuse. To quantify the impact of applying Kronecker decomposition on embedding matrices, we conduct a series of experiments on benchmark datasets. Our experiments suggest that applying Kronecker decomposition on embedding matrices leads to an improved parameter efficiency on all benchmark datasets. Moreover, empirical evidence suggests that reconstructed embeddings entail robustness against noise in the input knowledge graph. To foster reproducible research, we provide an open-source implementation of our approach, including training and evaluation scripts as well as pre-trained models in our knowledge graph embedding framework (https://github.com/dice-group/dice-embeddings).
Credal Self-Supervised Learning
Jun 22, 2021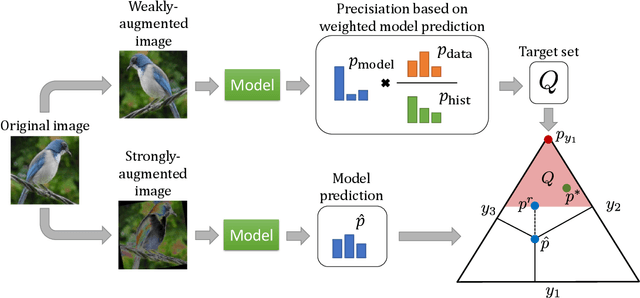
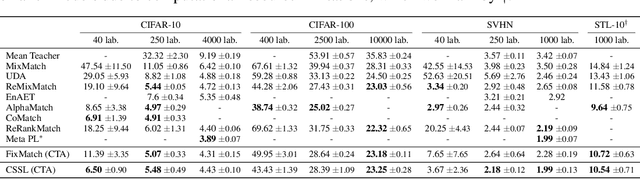
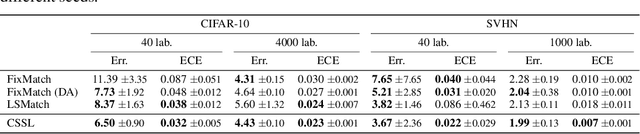
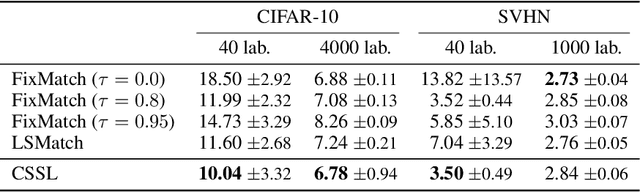
Self-training is an effective approach to semi-supervised learning. The key idea is to let the learner itself iteratively generate "pseudo-supervision" for unlabeled instances based on its current hypothesis. In combination with consistency regularization, pseudo-labeling has shown promising performance in various domains, for example in computer vision. To account for the hypothetical nature of the pseudo-labels, these are commonly provided in the form of probability distributions. Still, one may argue that even a probability distribution represents an excessive level of informedness, as it suggests that the learner precisely knows the ground-truth conditional probabilities. In our approach, we therefore allow the learner to label instances in the form of credal sets, that is, sets of (candidate) probability distributions. Thanks to this increased expressiveness, the learner is able to represent uncertainty and a lack of knowledge in a more flexible and more faithful manner. To learn from weakly labeled data of that kind, we leverage methods that have recently been proposed in the realm of so-called superset learning. In an exhaustive empirical evaluation, we compare our methodology to state-of-the-art self-supervision approaches, showing competitive to superior performance especially in low-label scenarios incorporating a high degree of uncertainty.
Monocular Depth Estimation via Listwise Ranking using the Plackett-Luce Model
Oct 31, 2020


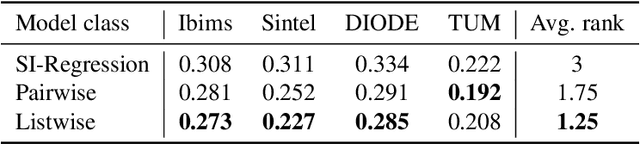
In many real-world applications, the relative depth of objects in an image is crucial for scene understanding, e.g., to calculate occlusions in augmented reality scenes. Predicting depth in monocular images has recently been tackled using machine learning methods, mainly by treating the problem as a regression task. Yet, being interested in an order relation in the first place, ranking methods suggest themselves as a natural alternative to regression, and indeed, ranking approaches leveraging pairwise comparisons as training information ("object A is closer to the camera than B") have shown promising performance on this problem. In this paper, we elaborate on the use of so-called listwise ranking as a generalization of the pairwise approach. Listwise ranking goes beyond pairwise comparisons between objects and considers rankings of arbitrary length as training information. Our approach is based on the Plackett-Luce model, a probability distribution on rankings, which we combine with a state-of-the-art neural network architecture and a sampling strategy to reduce training complexity. An empirical evaluation on benchmark data in a "zero-shot" setting demonstrates the effectiveness of our proposal compared to existing ranking and regression methods.