 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Fuzzy Cluster Transitions for Topic Tracing
Apr 16, 2021

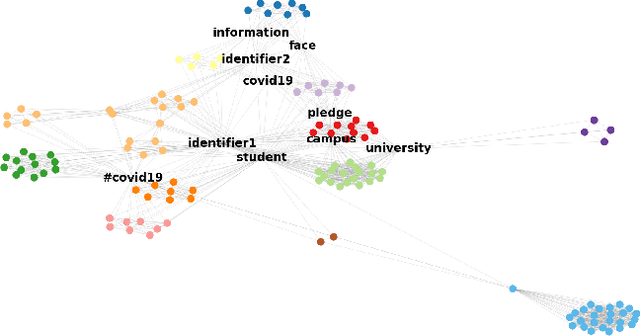
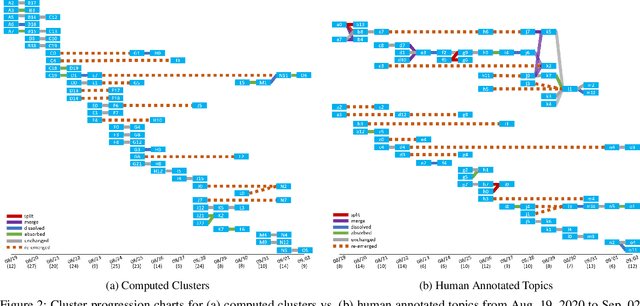
Twitter can be viewed as a data source for Natural Language Processing (NLP) tasks. The continuously updating data streams on Twitter make it challenging to trace real-time topic evolution. In this paper, we propose a framework for modeling fuzzy transitions of topic clusters. We extend our previous work on crisp cluster transitions by incorporating fuzzy logic in order to enrich the underlying structures identified by the framework. We apply the methodology to both computer generated clusters of nouns from tweets and human tweet annotations. The obtained fuzzy transitions are compared with the crisp transitions, on both computer generated clusters and human labeled topic sets.
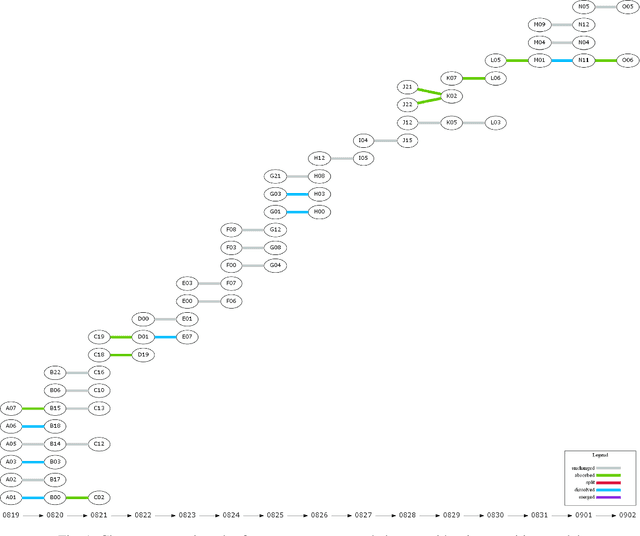
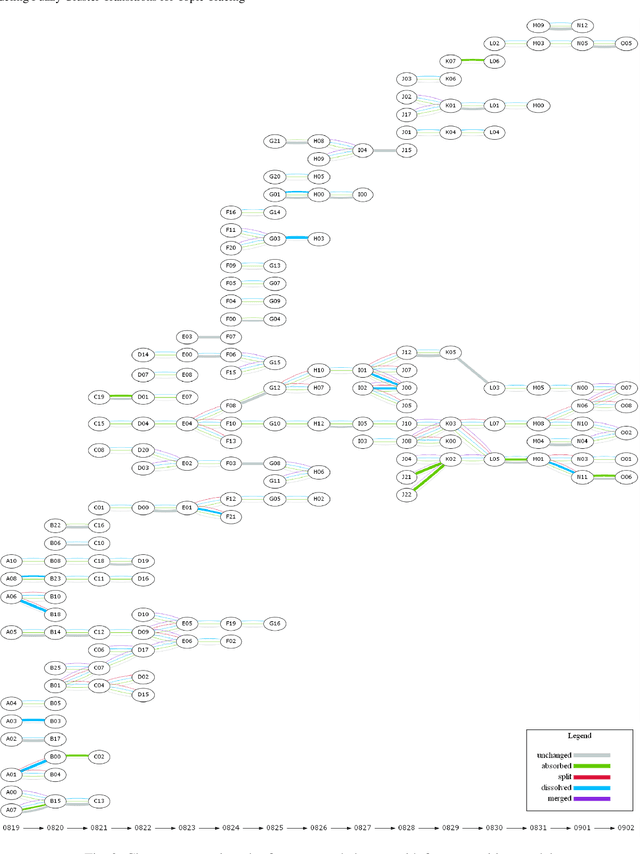
Tracing Topic Transitions with Temporal Graph Clusters
Apr 16, 2021

Twitter serves as a data source for many Natural Language Processing (NLP) tasks. It can be challenging to identify topics on Twitter due to continuous updating data stream. In this paper, we present an unsupervised graph based framework to identify the evolution of sub-topics within two weeks of real-world Twitter data. We first employ a Markov Clustering Algorithm (MCL) with a node removal method to identify optimal graph clusters from temporal Graph-of-Words (GoW). Subsequently, we model the clustering transitions between the temporal graphs to identify the topic evolution. Finally, the transition flows generated from both computational approach and human annotations are compared to ensure the validity of our framework.
Graph-of-Tweets: A Graph Merging Approach to Sub-event Identification
Jan 08, 2021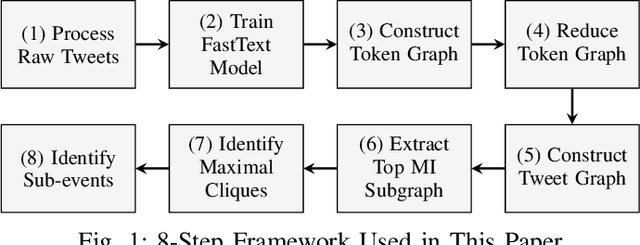
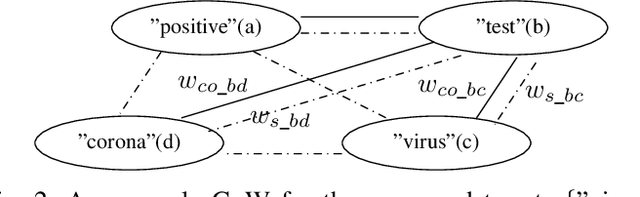


Graph structures are powerful tools for modeling the relationships between textual elements. Graph-of-Words (GoW) has been adopted in many Natural Language tasks to encode the association between terms. However, GoW provides few document-level relationships in cases when the connections between documents are also essential. For identifying sub-events on social media like Twitter, features from both word- and document-level can be useful as they supply different information of the event. We propose a hybrid Graph-of-Tweets (GoT) model which combines the word- and document-level structures for modeling Tweets. To compress large amount of raw data, we propose a graph merging method which utilizes FastText word embeddings to reduce the GoW. Furthermore, we present a novel method to construct GoT with the reduced GoW and a Mutual Information (MI) measure. Finally, we identify maximal cliques to extract popular sub-events. Our model showed promising results on condensing lexical-level information and capturing keywords of sub-events.
Misspelling Correction with Pre-trained Contextual Language Model
Jan 08, 2021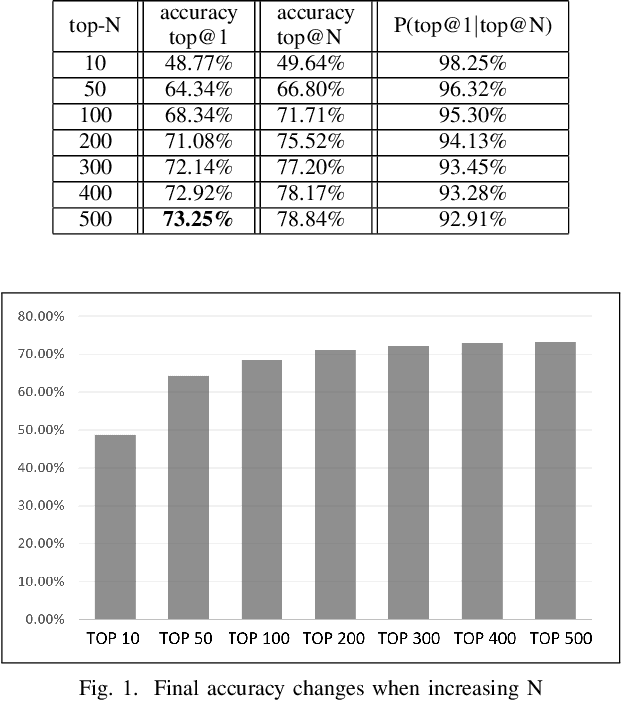


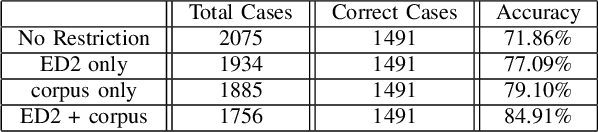
Spelling irregularities, known now as spelling mistakes, have been found for several centuries. As humans, we are able to understand most of the misspelled words based on their location in the sentence, perceived pronunciation, and context. Unlike humans, computer systems do not possess the convenient auto complete functionality of which human brains are capable. While many programs provide spelling correction functionality, many systems do not take context into account. Moreover, Artificial Intelligence systems function in the way they are trained on. With many current Natural Language Processing (NLP) systems trained on grammatically correct text data, many are vulnerable against adversarial examples, yet correctly spelled text processing is crucial for learning. In this paper, we investigate how spelling errors can be corrected in context, with a pre-trained language model BERT. We present two experiments, based on BERT and the edit distance algorithm, for ranking and selecting candidate corrections. The results of our experiments demonstrated that when combined properly, contextual word embeddings of BERT and edit distance are capable of effectively correcting spelling errors.
Model Choices Influence Attributive Word Associations: A Semi-supervised Analysis of Static Word Embeddings
Dec 14, 2020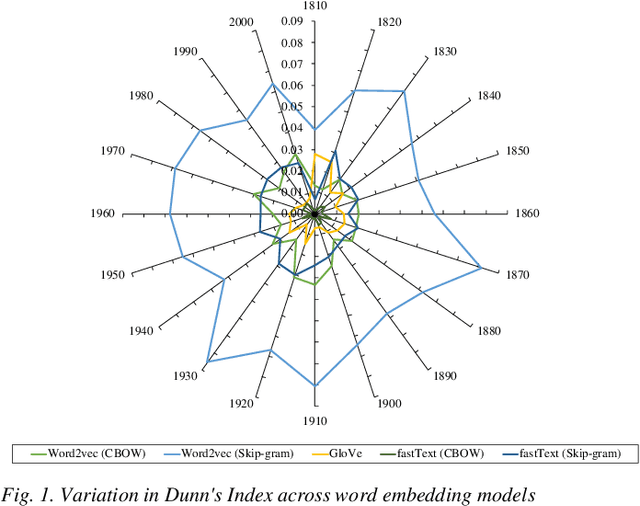
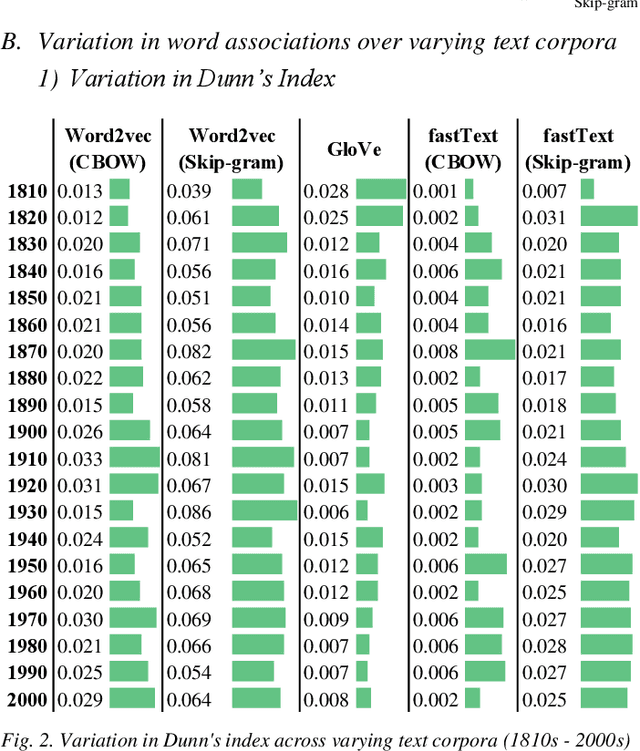
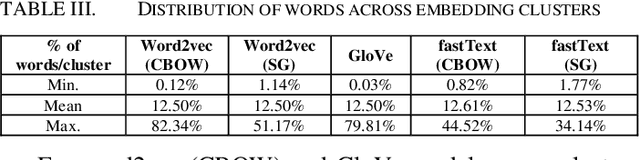
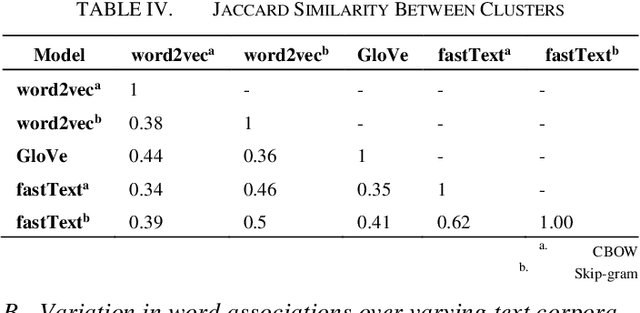
Static word embeddings encode word associations, extensively utilized in downstream NLP tasks. Although prior studies have discussed the nature of such word associations in terms of biases and lexical regularities captured, the variation in word associations based on the embedding training procedure remains in obscurity. This work aims to address this gap by assessing attributive word associations across five different static word embedding architectures, analyzing the impact of the choice of the model architecture, context learning flavor and training corpora. Our approach utilizes a semi-supervised clustering method to cluster annotated proper nouns and adjectives, based on their word embedding features, revealing underlying attributive word associations formed in the embedding space, without introducing any confirmation bias. Our results reveal that the choice of the context learning flavor during embedding training (CBOW vs skip-gram) impacts the word association distinguishability and word embeddings' sensitivity to deviations in the training corpora. Moreover, it is empirically shown that even when trained over the same corpora, there is significant inter-model disparity and intra-model similarity in the encoded word associations across different word embedding models, portraying specific patterns in the way the embedding space is created for each embedding architecture.
Exploring BERT's Sensitivity to Lexical Cues using Tests from Semantic Priming
Oct 06, 2020
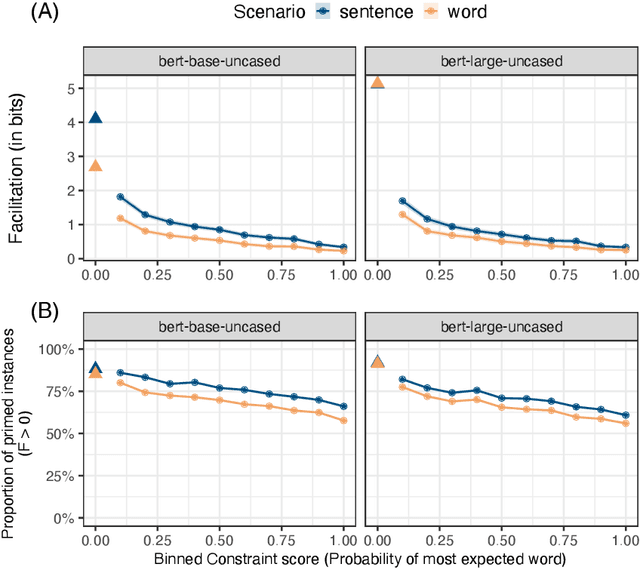
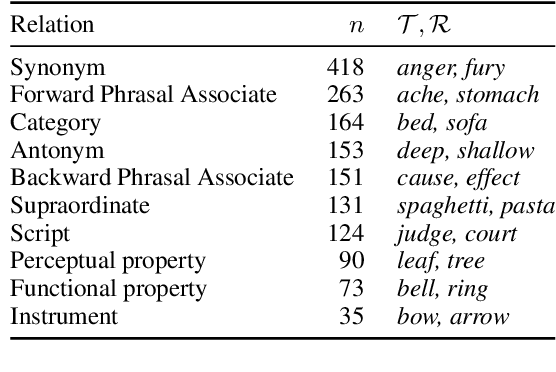
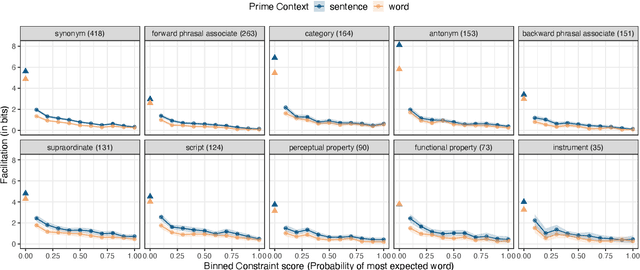
Models trained to estimate word probabilities in context have become ubiquitous in natural language processing. How do these models use lexical cues in context to inform their word probabilities? To answer this question, we present a case study analyzing the pre-trained BERT model with tests informed by semantic priming. Using English lexical stimuli that show priming in humans, we find that BERT too shows "priming," predicting a word with greater probability when the context includes a related word versus an unrelated one. This effect decreases as the amount of information provided by the context increases. Follow-up analysis shows BERT to be increasingly distracted by related prime words as context becomes more informative, assigning lower probabilities to related words. Our findings highlight the importance of considering contextual constraint effects when studying word prediction in these models, and highlight possible parallels with human processing.
An Event Detection Approach Based On Twitter Hashtags
Apr 02, 2018
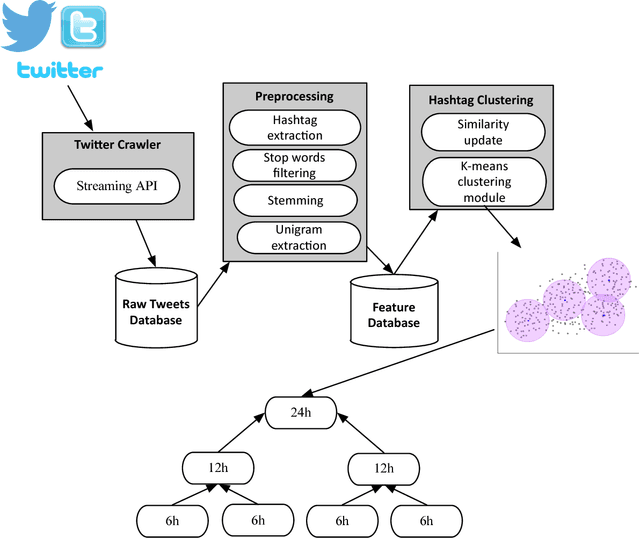


Twitter is one of the most popular microblogging services in the world. The great amount of information within Twitter makes it an important information channel for people to learn and share news. Twitter hashtag is an popular feature that can be viewed as human-labeled information which people use to identify the topic of a tweet. Many researchers have proposed event-detection approaches that can monitor Twitter data and determine whether special events, such as accidents, extreme weather, earthquakes, or crimes take place. Although many approaches use hashtags as one of their features, few of them explicitly focus on the effectiveness of using hashtags on event detection. In this study, we proposed an event detection approach that utilizes hashtags in tweets. We adopted the feature extraction used in STREAMCUBE and applied a clustering K-means approach to it. The experiments demonstrated that the K-means approach performed better than STREAMCUBE in the clustering results. A discussion on optimal K values for the K-means approach is also provided.