 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Interactive Systems via Data-Driven Objectives
Jun 19, 2020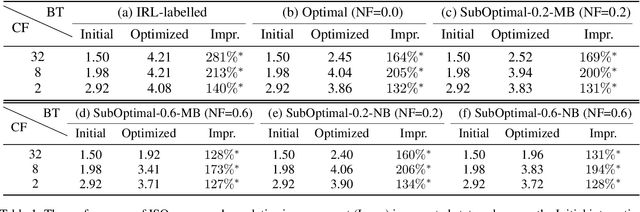
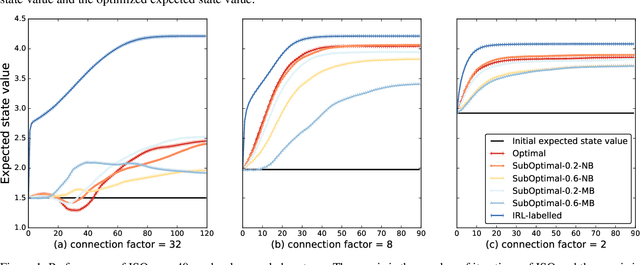
Effective optimization is essential for real-world interactive systems to provide a satisfactory user experience in response to changing user behavior. However, it is often challenging to find an objective to optimize for interactive systems (e.g., policy learning in task-oriented dialog systems). Generally, such objectives are manually crafted and rarely capture complex user needs in an accurate manner. We propose an approach that infers the objective directly from observed user interactions. These inferences can be made regardless of prior knowledge and across different types of user behavior. We introduce Interactive System Optimizer (ISO), a novel algorithm that uses these inferred objectives for optimization. Our main contribution is a new general principled approach to optimizing interactive systems using data-driven objectives. We demonstrate the high effectiveness of ISO over several simulations.
Evaluating Disentangled Representations
Oct 12, 2019

There is no generally agreed upon definition of disentangled representation. Intuitively, the data is generated by a few factors of variation, which are captured and separated in a disentangled representation. Disentangled representations are useful for many tasks such as reinforcement learning, transfer learning, and zero-shot learning. However, the absence of a formally accepted definition makes it difficult to evaluate algorithms for learning disentangled representations. Recently, important steps have been taken towards evaluating disentangled representations: the existing metrics of disentanglement were compared through an experimental study and a framework for the quantitative evaluation of disentangled representations was proposed. However, theoretical guarantees for existing metrics of disentanglement are still missing. In this paper, we analyze metrics of disentanglement and their properties. Specifically, we analyze if the metrics satisfy two desirable properties: (1)~give a high score to representations that are disentangled according to the definition; and (2)~give a low score to representations that are entangled according to the definition. We show that most of the current metrics do not satisfy at least one of these properties. Consequently, we propose a new definition for a metric of disentanglement that satisfies both of the properties.
SEntNet: Source-aware Recurrent Entity Network for Dialogue Response Selection
Jun 20, 2019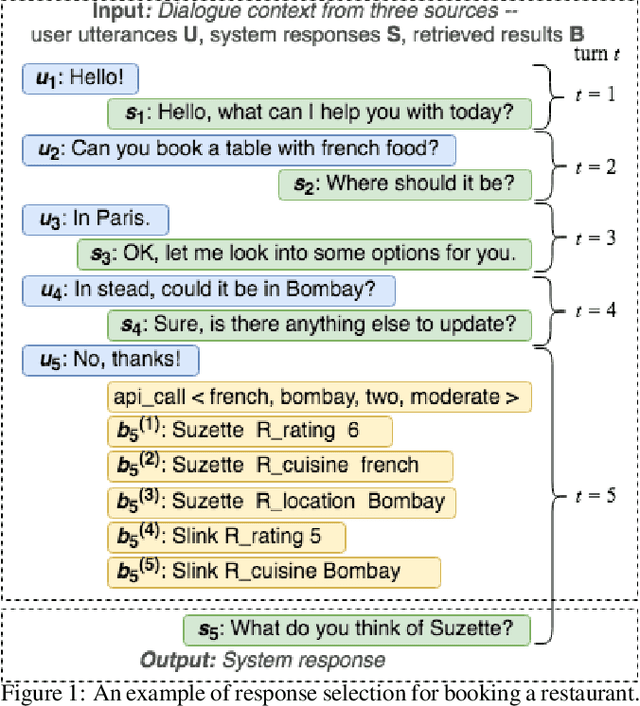
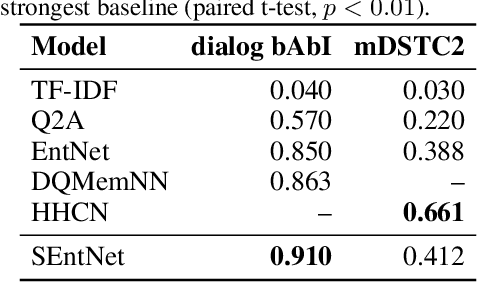
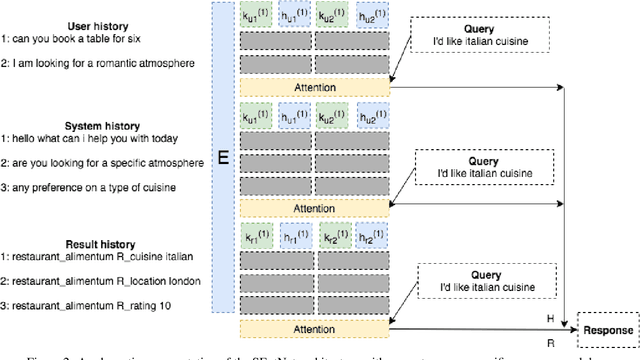
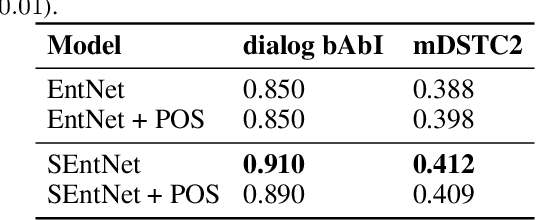
Dialogue response selection is an important part of Task-oriented Dialogue Systems (TDSs); it aims to predict an appropriate response given a dialogue context. Obtaining key information from a complex, long dialogue context is challenging, especially when different sources of information are available, e.g., the user's utterances, the system's responses, and results retrieved from a knowledge base (KB). Previous work ignores the type of information source and merges sources for response selection. However, accounting for the source type may lead to remarkable differences in the quality of response selection. We propose the Source-aware Recurrent Entity Network (SEntNet), which is aware of different information sources for the response selection process. SEntNet achieves this by employing source-specific memories to exploit differences in the usage of words and syntactic structure from different information sources (user, system, and KB). Experimental results show that SEntNet obtains 91.0% accuracy on the Dialog bAbI dataset, outperforming prior work by 4.7%. On the DSTC2 dataset, SEntNet obtains an accuracy of 41.2%, beating source unaware recurrent entity networks by 2.4%.
Dialogue Generation: From Imitation Learning to Inverse Reinforcement Learning
Dec 09, 2018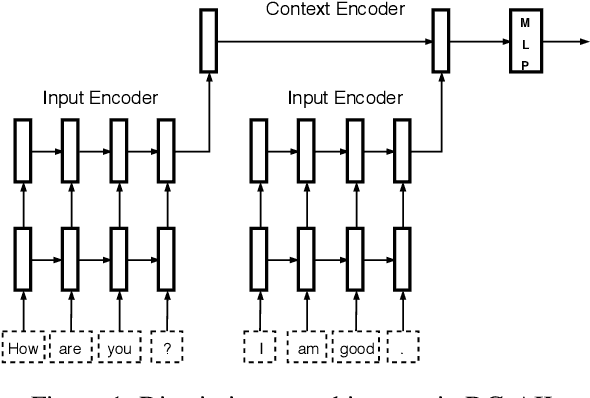

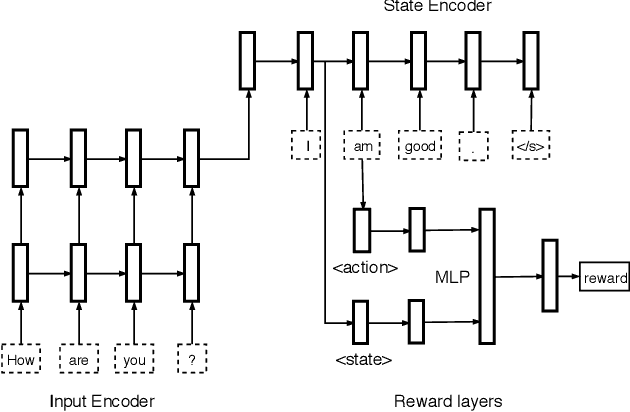
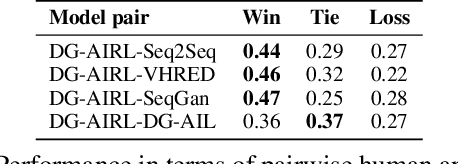
The performance of adversarial dialogue generation models relies on the quality of the reward signal produced by the discriminator. The reward signal from a poor discriminator can be very sparse and unstable, which may lead the generator to fall into a local optimum or to produce nonsense replies. To alleviate the first problem, we first extend a recently proposed adversarial dialogue generation method to an adversarial imitation learning solution. Then, in the framework of adversarial inverse reinforcement learning, we propose a new reward model for dialogue generation that can provide a more accurate and precise reward signal for generator training. We evaluate the performance of the resulting model with automatic metrics and human evaluations in two annotation settings. Our experimental results demonstrate that our model can generate more high-quality responses and achieve higher overall performance than the state-of-the-art.
Optimizing Interactive Systems with Data-Driven Objectives
Oct 17, 2018Effective optimization is essential for interactive systems to provide a satisfactory user experience. However, it is often challenging to find an objective to optimize for. Generally, such objectives are manually crafted and rarely capture complex user needs in an accurate manner. We propose an approach that infers the objective directly from observed user interactions. These inferences can be made regardless of prior knowledge and across different types of user behavior. We introduce Interactive System Optimizer (ISO), a novel algorithm that uses these inferred objectives for optimization. Our main contribution is a new general principled approach to optimizing interactive systems using data-driven objectives. We demonstrate the high effectiveness of ISO over several simulations.
Modeling Label Ambiguity for Neural List-Wise Learning to Rank
Jul 24, 2017
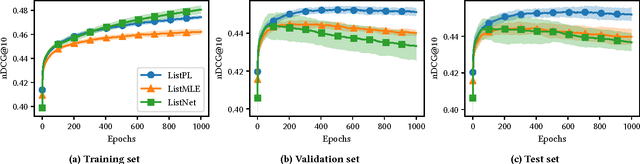
List-wise learning to rank methods are considered to be the state-of-the-art. One of the major problems with these methods is that the ambiguous nature of relevance labels in learning to rank data is ignored. Ambiguity of relevance labels refers to the phenomenon that multiple documents may be assigned the same relevance label for a given query, so that no preference order should be learned for those documents. In this paper we propose a novel sampling technique for computing a list-wise loss that can take into account this ambiguity. We show the effectiveness of the proposed method by training a 3-layer deep neural network. We compare our new loss function to two strong baselines: ListNet and ListMLE. We show that our method generalizes better and significantly outperforms other methods on the validation and test sets.